
It's the second follow-up Data+AI Summit post but the first one focusing on the stateful operations and their interaction with the state store.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
When I was preparing this blog post, I was more than surprised seeing how the limit query on a streaming data source works. That's the reason why, instead of going directly to the state store aspect, you will first learn the mechanism behind the global limit in a streaming query. Only later you will see the role of the state store in this kind of query.
Global limit implementation
The physical rule responsible for preparing the execution of global limit is StreamingGlobalLimitStrategy. It executes a pattern matching against the Limit or ReturnAnswer (for take() or collect()) node and transforms it into a subtree composed of a StreamingGlobalLimitExec node wrapping a StreamingLocalLimitExec:
case ReturnAnswer(Limit(IntegerLiteral(limit), child)) if generatesStreamingAppends(child) => StreamingGlobalLimitExec(limit, StreamingLocalLimitExec(limit, planLater(child))) :: Nil case Limit(IntegerLiteral(limit), child) if generatesStreamingAppends(child) => StreamingGlobalLimitExec(limit, StreamingLocalLimitExec(limit, planLater(child))) :: Nil
At this moment, it's worth adding that the global limit works only with append or complete output mode if the query has some aggregations. If it's not the case, you'll get one of the following error messages:
# 1 AnalysisException: Complete output mode not supported when there are no streaming aggregations on streaming DataFrames/Datasets; # 2 AnalysisException: Limits are not supported on streaming DataFrames/Datasets in Update output mode;;
But let's move on and and suppose that the query is valid. The first executed operation is the local limit represented in the first snippet's subtree by StreamingLocalLimitExec physical node. This local limit nodes takes the same limit attribute as the global limit. It means that every partition will return up to limit rows:
override def doExecute(): RDD[InternalRow] = child.execute().mapPartitions { iter =>
var generatedCount = 0
new NextIterator[InternalRow]() {
override protected def getNext(): InternalRow = {
if (generatedCount < limit && iter.hasNext) {
generatedCount += 1
iter.next()
} else {
finished = true
null
}
}
override protected def close(): Unit = {
while (iter.hasNext) iter.next() // consume the iterator completely
}
}
}
The state store is not yet involved in the query. It happens only in the step executing the global limit. But before that, the data is shuffled into a single partition used by the global limit code. You can see then that this local limit behaves a bit like a partial aggregation where Apache Spark moves the partition computation results to one node for final processing. And that's the moment when the limit operator starts to interact with the state store.
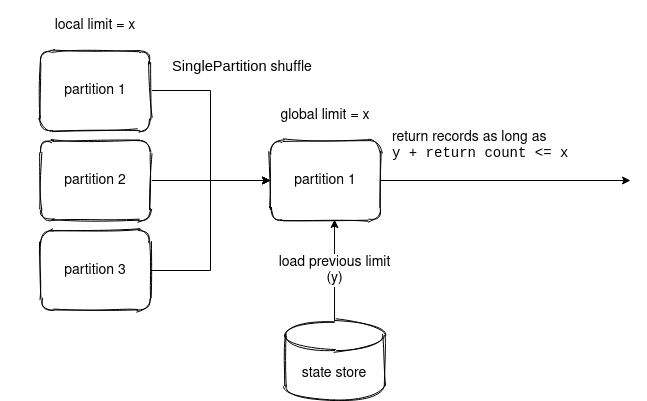
But wait a minute! Why is the shuffle added to the execution plan? It's due to the StreamingGlobalLimitExec's requiredChildDistribution that enforces the single partition character:
override def requiredChildDistribution: Seq[Distribution] = AllTuples :: Nil
/**
* Represents a distribution that only has a single partition and all tuples of the dataset
* are co-located.
*/
case object AllTuples extends Distribution {
override def requiredNumPartitions: Option[Int] = Some(1)
override def createPartitioning(numPartitions: Int): Partitioning = {
assert(numPartitions == 1, "The default partitioning of AllTuples can only have 1 partition.")
SinglePartition
}
}
Global limit and state store
The global limit operator in Structured Streaming works ... globally. It'll then limit the number of records returned in all micro-batch queries of the application! From that, I'm sure that you already see the main role of the state store here. Yes, the state store is used to store the number of records returned so far in all micro-batches. And the logic behind that is quite straightforward:
val key = UnsafeProjection.create(keySchema)(new GenericInternalRow(Array[Any](null)))
// ...
val preBatchRowCount: Long = Option(store.get(key)).map(_.getLong(0)).getOrElse(0L)
var cumulativeRowCount = preBatchRowCount
val result = iter.filter { r =>
val x = cumulativeRowCount < streamLimit
if (x) {
cumulativeRowCount += 1
}
x
}
CompletionIterator[InternalRow, Iterator[InternalRow]](result, {
if (cumulativeRowCount > preBatchRowCount) {
numUpdatedStateRows += 1
numOutputRows += cumulativeRowCount - preBatchRowCount
store.put(key, getValueRow(cumulativeRowCount))
}
allUpdatesTimeMs += NANOSECONDS.toMillis(System.nanoTime - updatesStartTimeNs)
commitTimeMs += timeTakenMs { store.commit() }
setStoreMetrics(store)
})
As you can see in the snippet above, the query - remember, it executes on a single partition - starts by getting the previous limit counter that obviously for the first execution will be 0. In the next micro-batch, if there were some new records (let's say x), the value of this counter will be 0+x, and it will increment that way as long as the x is smaller than limit.
When the executed micro-batch does include some new rows to the sink, the state store is updated with the new counter (cumulativeRowCount). If not, the micro-batch returns an empty because none of the rows will meet the filter predicate.
If I satisfied your curiosity about the global limit implementation in streaming queries, I'm glad. As you saw, it involves multiple intermediary steps like a partial aggregation simulation. And only at the end, it interacts with the state store to control the total number of records returned to the sink.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Data+AI Summit follow-up post: Why RocksDB rocks?
- Data+AI Summit: custom state store integration feedback
- Data+AI Summit: Custom state store - API
- Data+AI follow-up: Introduction to MapDB
- Data+AI Summit follow-up: arbitrary stateful processing and state management
Did you already use the global limit in #StructuredStreaming ? I didn't and that's why I was quite surprised to discover it among the stateful operations ? If interested, you will find more details in the new blog post ? https://t.co/DaQOE6DzHb
— Bartosz Konieczny (@waitingforcode) November 14, 2020