
Using cloud managed services is often a love and hate story. On one hand, they abstract a lot of tedious administrative work to let you focus on the essentials. From another, they often have quotas and limits that you, as a data engineer, have to take into account in your daily work. These limits become even more serious when they operate in a latency-sensitive context, as the one of stream processing.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this blog post you're going to see how three different Apache Spark Structured Streaming connectors address the limits and quotas issues for Amazon Kinesis Data Streams. Apache Spark and Kinesis is a long story. Long time ago, at Spark Streaming module times, the connector was included in the Open Source version. However, when Structured Streaming replaced the Streaming, the Kinesis connector was not there. Over the years people were using Qubole's Open Source alternative that got the last commit in 2020...
From that moment many alternative solutions appeared, including Databricks' version, Qubole-based connector, and more recently, an almost official one proposed by AWS in their labs repository. Three different options and different implementation choices to solve the same problem - read data from Kinesis Data Streams in the most efficient manner.
Qubole-based
That's the successor for Spark Streaming's connector available in early Structured Streaming versions. It was replaced in the 3.2 release by ronmercer's spark-sql-kinesis, henceforth Archived. Despite this inactive status, let's analyze it to understand better the alternative processing patterns proposed by two next connectors.
In simple terms, the Qubole-based connector interleaves data fetching and data returning loops. If there is no records fetched, or all previously read rows were already returned to the downstream operator, the consumer issues a new Kinesis GetRecords call to fill the local buffer. The next schema shows how this logic works:
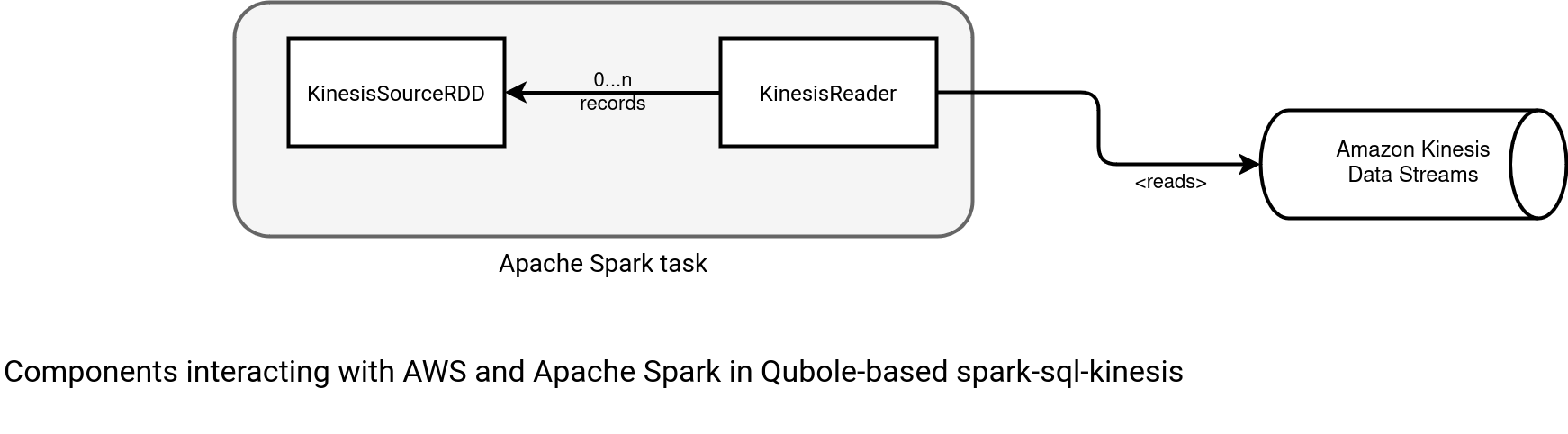
As you can see, the reading here is synchronous. From one hand, there are less risks to hit the service limits but from another one, the Kinesis reader stays idle while the downstream operators process the fetched records.
AWS labs
The most recent connector solves this synchronicity issue. The library is part of AWS Labs repository and you can find it in the spark-sql-kinesis-connector project.
The AWS' connector implements a more reactive fetching. The consumer doesn't remain idle. Instead, it's continuously running in a background thread to fill the local buffer. As a result, the KinesisV2PartitionReader which interacts directly with Apache Spark's internals, doesn't communicate with the Kinesis API at all. It delegates this responsibility to the ShardConsumer, as shown in the schema below:
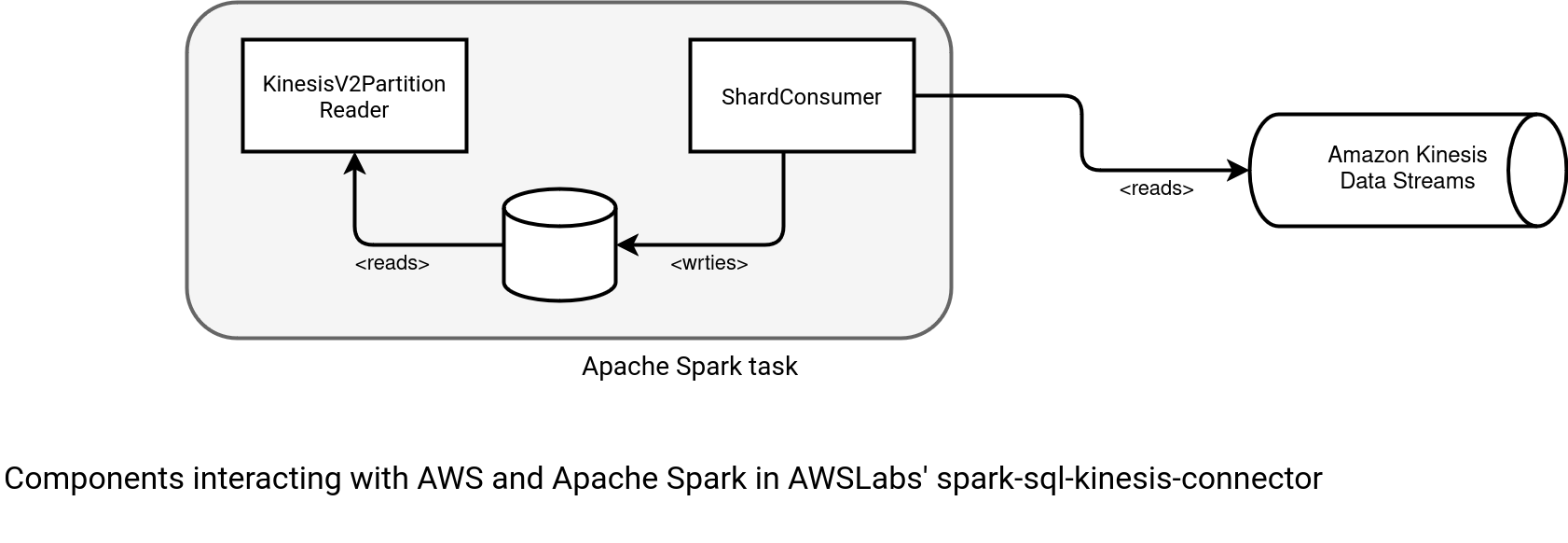
Thanks to this loose coupling, there is no more synchronous dependency between the fetching and processing parts. But it doesn't mean it's fully asynchronous. The local buffer is defined as follows, with some fixed capacity:
class KinesisV2PartitionReader ... extends PartitionReader[InternalRow] with DataReceiver {
private val queueCapacity = kinesisOptions.dataQueueCapacity
private val dataQueue: BlockingQueue[KinesisUserRecord] = new
ArrayBlockingQueue[KinesisUserRecord](queueCapacity);
When the buffer is full, which means the consumer is not processing already fetched records fast enough, the asynchronous Kinesis reader will try to add it as long as the dataReader, therefore the KinesisV2PartitionReader is up:
class ShardConsumer(
val dataReader: DataReceiver,
val recordBatchPublisher: RecordBatchPublisher) extends Runnable with Logging{
// ...
private def isRunning = (!Thread.interrupted) && dataReader.isRunning
private def enqueueRecord(record: KinesisUserRecord): Unit = synchronized {
var result = false
breakable {
while (isRunning && !result) {
result = dataReader.enqueueRecord(streamShard, record)
if (KinesisUserRecord.emptyUserRecord(record)) {
break // Don't retry empty user record
}
}
}
// ...
The KinesisV2PartitionReader, hence the class of an Apache Spark task, doesn't run continuously. The connector has a property called kinesis.maxFetchTimePerShardSec to control the reading time:
private def hasTimeForMoreRecords(currentTimestamp: Long): Boolean = {
// always return true if kinesisOptions.maxFetchTimePerShardSec is None
kinesisOptions.maxFetchTimePerShardSec.forall { maxFetchTimePerShardSec =>
(currentTimestamp - startTimestamp) < (maxFetchTimePerShardSec * 1000L)
}
}
This timeout is impacted by the processing latency itself but also by the queue capacity. When the task buffer is full, the ShardConsumer will wait some time before giving up. The time is configured as kinesis.internal.dataQueueWaitTimeoutSec:
// KinesisV2PartitionReader
override def enqueueRecord(streamShard: StreamShard, record: KinesisUserRecord): Boolean = {
if (!isRunning) return false
val putResult = dataQueue.offer(record, dataQueueWaitTimeout.getSeconds, TimeUnit.SECONDS)
Databricks
After the two Open Source versions let's see now how the Amazon Kinesis Data Streams problem solves Databricks. It shares the buffering idea of AWSLabs' solution but with a different flavor. The buffer is global instead of being coupled to the task execution. Consequently, when you run a Kinesis job, you will see two types of job groups, one for your business logic, and one for Kinesis data buffer:

Remember, the jobs in Apache Spark are isolated units. It's then not surprising to see both different jobs submitted at the same time. It's even less surprising to see multiple jobs of the same type (buffering in this case), submitted in a row:

The Databricks' version creates a buffer per executor of fetchBufferSize which defaults to 20GB. According to the documentation, the fetching can be controlled with the following options:
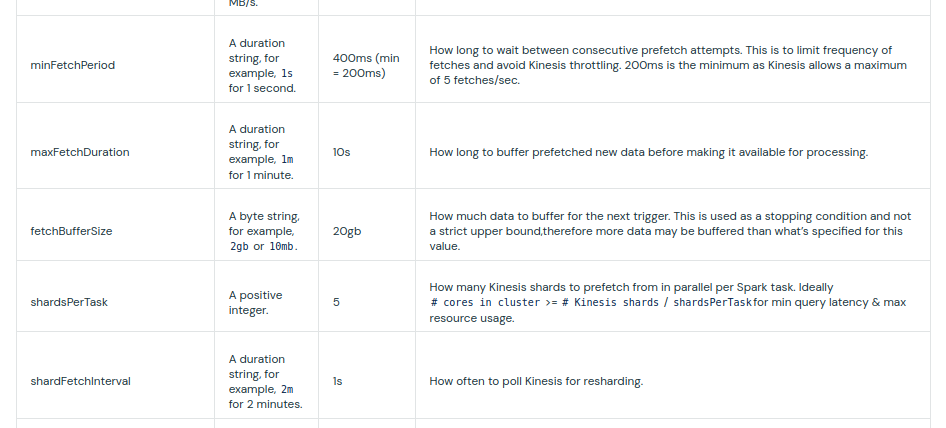
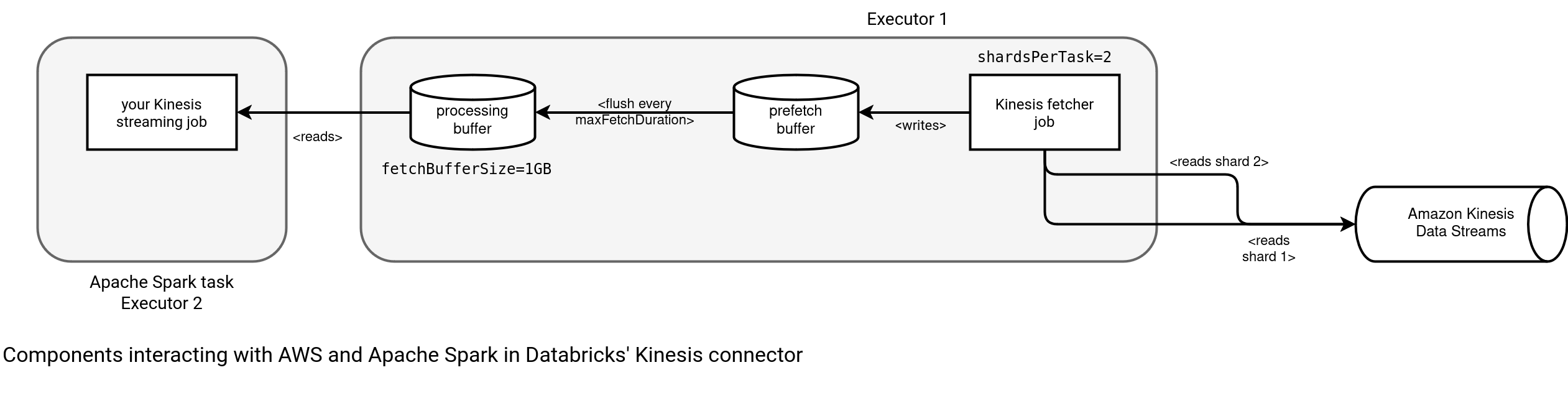
Although the options are pretty self-explanatory, I'm still not sure about the fetching vs. pre-fetching difference in the naming. From my observations, there is a kind of private buffer for the fetching consumer that keeps retrieved records hidden as long as the maxFetchDuration period is not reached. It might help scheduling the micro-batch on small dataset:
Takeaways
From the performance standpoint, the Databricks' approach of the almost-continuous fetching is the winner. Indeed, there is that fetchBufferSize limitation but it'll be the blocking factor only when your consumers are very slow and the fetcher will have to wait extra time to see the data taken out of the buffer.
However, the buffer decorelated from the processing has one gotcha. You can't rely on the IteratorAge metric anymore to evaluate your lag. Since this buffering task is only doing Kinesis calls to cache the records locally, it will be fast and will never be able to represent how your processing job is doing. It doesn't apply to the AWSLabs' version as the buffering is tightly coupled to the processing task itself. As a result, a slower task will clearly be visible in an increased lag while for Databricks it might not be the case if the buffer is big and the fetching process can run despite the processing being stuck.
Another major difference is the throughput perception. In Databricks you will reason in terms of buffer and time. In AWSLabs, you will simply set a number in the kinesis.maxFetchRecordsPerShard option, like for Apache Kafka throughput controls. Depending on the person, thinking about a number than a time/space combination, might be easier.
Despite the various buffering approaches that are technically interesting but at the same time, might be confusing for an Apache Spark user, is there any good news? I'd say yes, as finally AWS has an almost official Apache Spark connector for Kinesis Data Streams! And it looks like a solid one 💪
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Dealing with quotas and limits - Apache Spark Structured Streaming for Amazon Kinesis Data Streams here:
Related blog posts:
- Spark Declarative Pipelines internals
- Spark Declarative Pipelines, going further
- Spark Declarative Pipelines 101