
A few months ago I wrote a blog post about event skew and how dangerous it is for a stateful streaming job. Since it was a high-level explanation, I didn't cover Apache Spark Structured Streaming deeply at that moment. Now the watermark topic is back to my learning backlog and it's a good opportunity to return to the event skew topic and see the dangers it brings for Structured Streaming stateful jobs.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Before going into details, let's recall some terms:
- Event skew happens when a partition of your input streaming broker moves much faster than the others. For example, the partition might be processing records for 11:00 while the others are dealing with the events coming from 10:00. I know, the 1-hour skew looks scary and probably won't happen very often but this exaggeration is here to illustrate the event skew better.
- Watermark defines the completeness of a state compared to the event time of your input records. Put differently, it determines the accepted event time for the incoming events.
Watermark 101 in Structured Streaming
To see the logic behind the watermarks in Apache Spark Structured Streaming, let's take a job that deduplicates record data:
val memoryStream1 = MemoryStream[Event](2)(Encoders.product[Event], sparkSession.sqlContext)
val query = memoryStream1.toDS
.withWatermark("eventTime", "20 seconds")
.dropDuplicatesWithinWatermark("id")
val writeQuery = query.writeStream.format("console").option("truncate", false).start()
The job sets an accepted latency to 20 seconds and is going to deduplicate rows falling within the watermark. When you analyze the query plans for the code, you'll notice an EventTimeWatermark node:
== Parsed Logical Plan == WriteToMicroBatchDataSource org.apache.spark.sql.execution.streaming.ConsoleTable$@6e12f38c, e7d0ef39-cca5-4bc5-8331-c5ff02b52bdd, [truncate=false], Append, 1 +- DeduplicateWithinWatermark [id#2] +- EventTimeWatermark eventTime#3: timestamp, 20 seconds +- LocalRelation, [id#2, eventTime#3] == Analyzed Logical Plan == WriteToMicroBatchDataSource org.apache.spark.sql.execution.streaming.ConsoleTable$@6e12f38c, e7d0ef39-cca5-4bc5-8331-c5ff02b52bdd, [truncate=false], Append, 1 +- DeduplicateWithinWatermark [id#2] +- EventTimeWatermark eventTime#3: timestamp, 20 seconds +- LocalRelation , [id#2, eventTime#3] == Optimized Logical Plan == WriteToDataSourceV2 MicroBatchWrite[epoch: 1, writer: ConsoleWriter[numRows=20, truncate=false]] +- DeduplicateWithinWatermark [id#2] +- EventTimeWatermark eventTime#3: timestamp, 20 seconds +- LocalRelation , [id#2, eventTime#3] == Physical Plan == WriteToDataSourceV2 MicroBatchWrite[epoch: 1, writer: ConsoleWriter[numRows=20, truncate=false]], org.apache.spark.sql.execution.datasources.v2.DataSourceV2Strategy$$Lambda$2065/0x0000000800fe4040@2baba5c5 +- StreamingDeduplicateWithinWatermark [id#2], state info [ checkpoint = file:/tmp/temporary-6fad4a7f-7e25-40f8-bd78-2638a676ce47/state, runId = b2c05a7a-a23d-469e-9adc-5f1acfc766ba, opId = 0, ver = 1, numPartitions = 200], 0, 1686392430000 +- Exchange hashpartitioning(id#2, 200), ENSURE_REQUIREMENTS, [plan_id=139] +- EventTimeWatermark eventTime#3: timestamp, 20 seconds +- LocalTableScan , [id#2, eventTime#3]
The EventTimeWatermark node refers to the column and the allowed latency configured in the withWatermark method. Under-the-hood, it translates to the workflow from the next schema. You can see there a WatermarkTracker object associated to the micro-batch executor that references the physical node responsible for watermark tracking across tasks (EventTimeWatermarkExec):
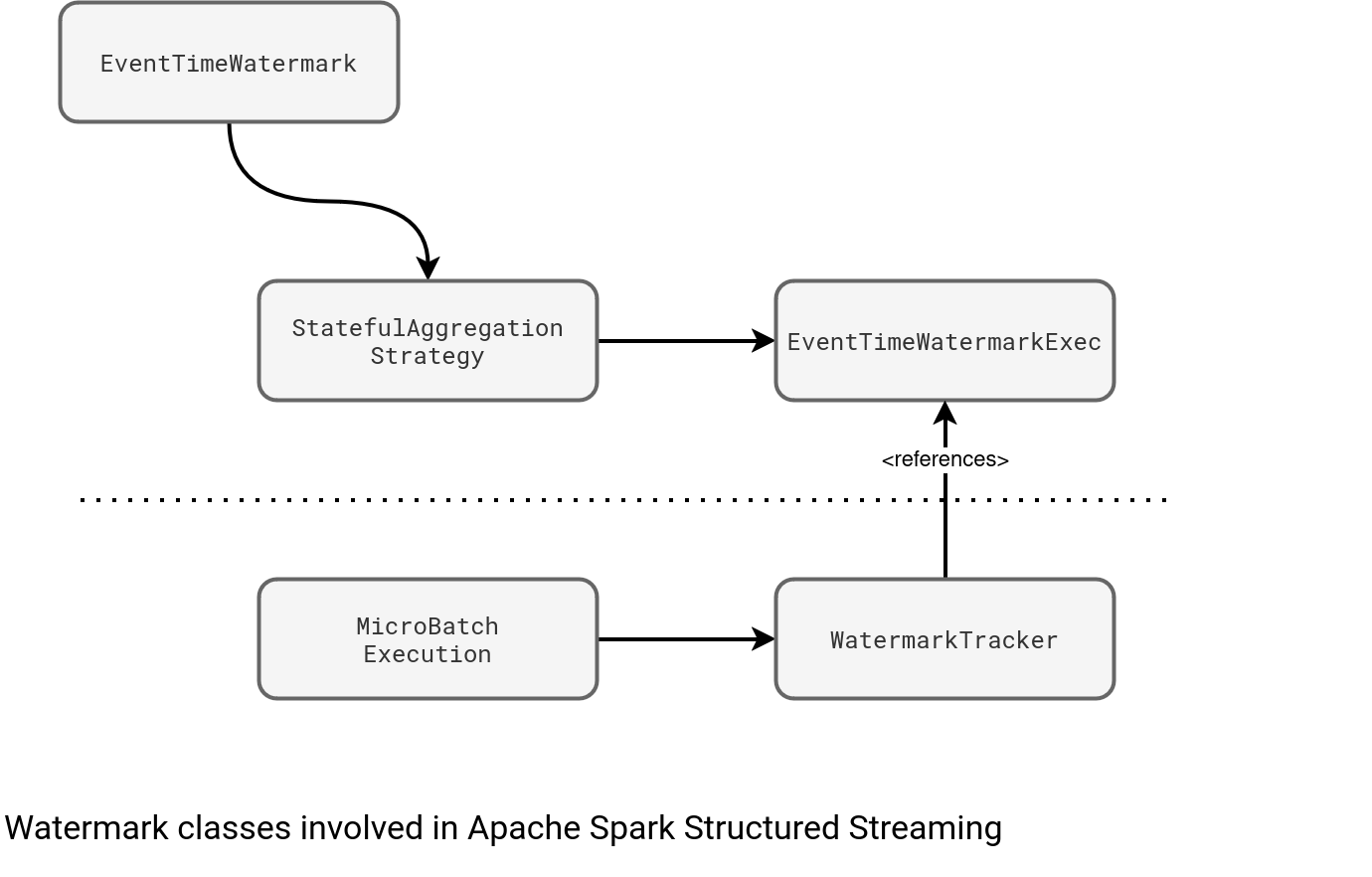
When a micro-batch completes, it calls WatermarkTracker's updateWatermark method that resolves the global watermark to the biggest event time observed between the current watermark and new events processed in the micro-batch:
def updateWatermark(executedPlan: SparkPlan): Unit = synchronized {
val watermarkOperators = executedPlan.collect {
case e: EventTimeWatermarkExec => e
}
// ...
watermarkOperators.zipWithIndex.foreach {
case (e, index) if e.eventTimeStats.value.count > 0 =>
val newWatermarkMs = e.eventTimeStats.value.max - e.delayMs
val prevWatermarkMs = operatorToWatermarkMap.get(index)
if (prevWatermarkMs.isEmpty || newWatermarkMs > prevWatermarkMs.get) {
operatorToWatermarkMap.put(index, newWatermarkMs)
}
// ...
}
val chosenGlobalWatermark = policy.chooseGlobalWatermark(operatorToWatermarkMap.values.toSeq)
if (chosenGlobalWatermark > globalWatermarkMs) {
globalWatermarkMs = chosenGlobalWatermark
} else {
logDebug(s"Event time watermark didn't move: $chosenGlobalWatermark < $globalWatermarkMs")
}
Although the snippet above mentions a global watermark policy, it doesn't apply to the tasks! It only applies if you have two streaming data sources with watermarks defined. The policy will either take the min (default), or the max watermark from them. In other words, if there is one data source, as it's the case of our example, the watermark will be the most recent event time. How is it possible? The e.eventTimeStats.value.max is an accumulator that accumulates the biggest event times as:
case class EventTimeStats(var max: Long, var min: Long, var avg: Double, var count: Long) {
def add(eventTime: Long): Unit = {
this.max = math.max(this.max, eventTime)
this.min = math.min(this.min, eventTime)
this.count += 1
this.avg += (eventTime - avg) / count
}
Since the WatermarkTracker explicitly asks for the max value, there will always be the max returned by the accumulator. Is it dangerous? Not if all your tasks process the records with approximately the same event time. Otherwise, you'll face event skew and depending on the allowed lateness and the skew size itself, you may be missing data, a lot of data.
Event skew example
To see the impact of event skew, let's take an Apache Kafka topic with two partitions. The processing logic uses the same deduplication code as before but since it's easier to target partitions with Apache Kafka, the snippet relies on Kafka data source:
val kafkaSource = sparkSession.readStream
.option("kafka.bootstrap.servers", "localhost:9094")
.option("subscribe", "events").format("kafka").load()
val eventsToDeduplicate = kafkaSource.select(functions.from_json(
functions.col("value").cast("string"), StructType.fromDDL("id INT, eventTime TIMESTAMP")).alias("value"))
.selectExpr("value.*")
val query = eventsToDeduplicate
.withWatermark("eventTime", "20 minutes")
.dropDuplicatesWithinWatermark("id")
val writeQuery = query.writeStream.format("console")
.option("truncate", false).start()
Pretty simple, isn't it? Unfortunately, even this simple code can be a nightmare on production if the event skew happens. Let's take a look at the data now. The first micro-batch processes the following records:
// Micro-batch #1
Seq(
(0, """{"id": 1, "eventTime": "2023-06-10 10:21:00"}"""),
(0, """{"id": 1, "eventTime": "2023-06-10 10:22:00"}"""),
(0, """{"id": 2, "eventTime": "2023-06-10 10:23:00"}"""),
(0, """{"id": 3, "eventTime": "2023-06-10 10:24:00"}"""),
(1, """{"id": 10, "eventTime": "2023-06-10 11:20:00"}"""),
(1, """{"id": 10, "eventTime": "2023-06-10 11:25:00"}""")
).toDF("partition", "value")
.write.option("kafka.bootstrap.servers", "localhost:9094").option("topic", "events")
.format("kafka").save()
// Micro-batch #2
Seq(
(0, """{"id": 4, "eventTime": "2023-06-10 10:25:00"}"""),
(0, """{"id": 5, "eventTime": "2023-06-10 10:26:00"}"""),
(0, """{"id": 6, "eventTime": "2023-06-10 10:27:00"}"""),
(0, """{"id": 7, "eventTime": "2023-06-10 10:28:00"}"""),
(1, """{"id": 11, "eventTime": "2023-06-10 11:11:00"}"""),
(1, """{"id": 12, "eventTime": "2023-06-10 11:15:00"}""")
).toDF("partition", "value")
.write.option("kafka.bootstrap.servers", "localhost:9094").option("topic", "events")
.format("kafka").save()
As you can see, the events from partition 0 occurred at 10 o'clock while the ones from partition 1 at 11, hence one hour later! Once the first micro-batch runs, you will observe a pretty high watermark:
// ...
"eventTime" : {
"watermark" : "2023-06-10T11:05:00.000Z"
},
Nothing special if you know that the watermark rule relies on the MAX function. But because of that, all subsequent events from partition 0 will be ignored. Let's take a look at the console print after running the job:
------------------------------------------- Batch: 0 ------------------------------------------- +---+---------+ |id |eventTime| +---+---------+ +---+---------+ ------------------------------------------- Batch: 1 ------------------------------------------- +---+-------------------+ |id |eventTime | +---+-------------------+ |1 |2023-06-10 10:21:00| |3 |2023-06-10 10:24:00| |10 |2023-06-10 11:20:00| |2 |2023-06-10 10:23:00| +---+-------------------+ ------------------------------------------- Batch: 2 ------------------------------------------- +---+---------+ |id |eventTime| +---+---------+ +---+---------+ ------------------------------------------- Batch: 3 ------------------------------------------- +---+-------------------+ |id |eventTime | +---+-------------------+ |12 |2023-06-10 11:15:00| |11 |2023-06-10 11:11:00| +---+-------------------+
If you analyze the progress report, you'll see that 4 records, which corresponds to all the records from the partition 0 of the second micro-batch:
"stateOperators" : [ {
"operatorName" : "dedupeWithinWatermark",
"numRowsTotal" : 3,
"numRowsUpdated" : 2,
"numRowsRemoved" : 0,
"numRowsDroppedByWatermark" : 4
} ],
To be clear, you should always apply this event skew phenomena to your dataset. If you're pretty confident your producers will not deliver that skewed data, you can rest easy. If it's not guaranteed, you don't need to drop using Structured Streaming. But instead you'll need to adapt and potentially define a higher accepted latency threshold that corresponds to the max expected skew. Of course, it'll have important implications on your state as the watermark-based state will be buffered longer and potentially emitted later to your downstream consumers. But that's probably better than losing the data, isn't it?
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Event time skew and global watermark in Apache Spark Structured Streaming here:
Related blog posts:
- Spark Declarative Pipelines internals
- Spark Declarative Pipelines, going further
- Spark Declarative Pipelines 101