
Testing batch jobs is not the same as testing streaming ones. Although the transformation (the WHAT from the previous article) is similar in both cases, more complete validation tests on the job logic are not. After all, streaming jobs often iteratively build the final outcome while the batch ones generate it in a single pass.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this follow-up blog post of my Data+AI Summit talk you'll see how to orchestrate streaming assertions. To understand it, let's take an example of the sesions_generation_job_logic.py that looks like follows:
def generate_sessions(visits_source: DataFrame, devices: DataFrame, trigger: Dict[str, str]) -> DataStreamWriter:
raw_visits = select_raw_visits(visits_source)
enriched_visits = enrich_visits_with_devices(raw_visits, devices)
grouped_visits = (enriched_visits.withWatermark('event_time', '1 minute')
.groupBy(F.col('visit_id')))
sessions = grouped_visits.applyInPandasWithState(
func=map_visits_to_session,
outputStructType=get_session_output_schema(),
stateStructType=get_session_state_schema(),
outputMode="append",
timeoutConf="EventTimeTimeout"
)
visits_to_write = sessions.withColumn('value', F.to_json(F.struct('*'))).select('value')
return set_up_visits_writer(visits_to_write, trigger)
Orchestrating assertions - AvailableNow
While you consider orchestrating assertions in Apache Spark Structured Streaming, you'll probably think about the AvailableNow trigger or the processAllAvailable helper method. Without saying which one is better now, let's analyze the trigger first.
The AvailableNow trigger takes all data available at a given moment and processes it with the respect of throughput configuration. Theoretically, it's then a good way to orchestrate multiple assertions for a streaming job. Well, in theory yes, but in practice it can be a bit cumbersome. Take a look at the following test:
def should_generate_sessions_as_the_watermark_when_watermark_passes_by(generate_spark_session):
test_name = sys._getframe().f_code.co_name
spark_session = generate_spark_session[0]
# ...
visit_writer = generate_sessions(visits_reader, devices_to_test, {'availableNow': 'true'}) # use 0 to disable the trigger
query = (visit_writer.option('checkpointLocation', '/tmp/test')
.foreachBatch(assertions_io.write_results_to_batch_id_partitioned_storage()))
started_query = query.start()
started_query.awaitTermination()
# ...
assert_that(emitted_visits_0).is_empty()
assert_that(emitted_visits_1).is_empty()
# Next add new visits
started_query.awaitTermination()
assert_that(emitted_visits_2).is_empty()
assert_that(emitted_visits_3).is_empty()
# Finally add the last visit to expire the v1 and v2 sessions
started_query.awaitTermination()
assert_that(emitted_visits_4).is_empty()
assert_that(emitted_visits_5).is_not_empty()
assert_that(emitted_visits_5).is_length(2)
The goal here is to accumulate the visits for two sessions and emit the results once the watermark moves on. Spoiler alert, it works but compared to the next method, has some drawbacks. First, you need to define the checkpointLocation to persist the state. Next, you need to repeat the start() - awaitTermination() whenever you want to assert a new micro-batch sequence. If it sounds like too many things to remember for a unit test, there is a simpler way.
Orchestrating assertions - processAllAvailable()
An alternative to the availableNow is the processAllAvailable. In simple terms, it blocks the main thread as long as the input data doesn't get fully processed. The implementation is present in the StreamExecution as:
override def processAllAvailable(): Unit = {
assertAwaitThread()
if (streamDeathCause != null) {
throw streamDeathCause
}
if (!isActive) return
awaitProgressLock.lock()
try {
noNewData = false
while (true) {
awaitProgressLockCondition.await(10000, TimeUnit.MILLISECONDS)
if (streamDeathCause != null) {
throw streamDeathCause
}
if (noNewData || !isActive) {
return
}
}
} finally {
awaitProgressLock.unlock()
}
}
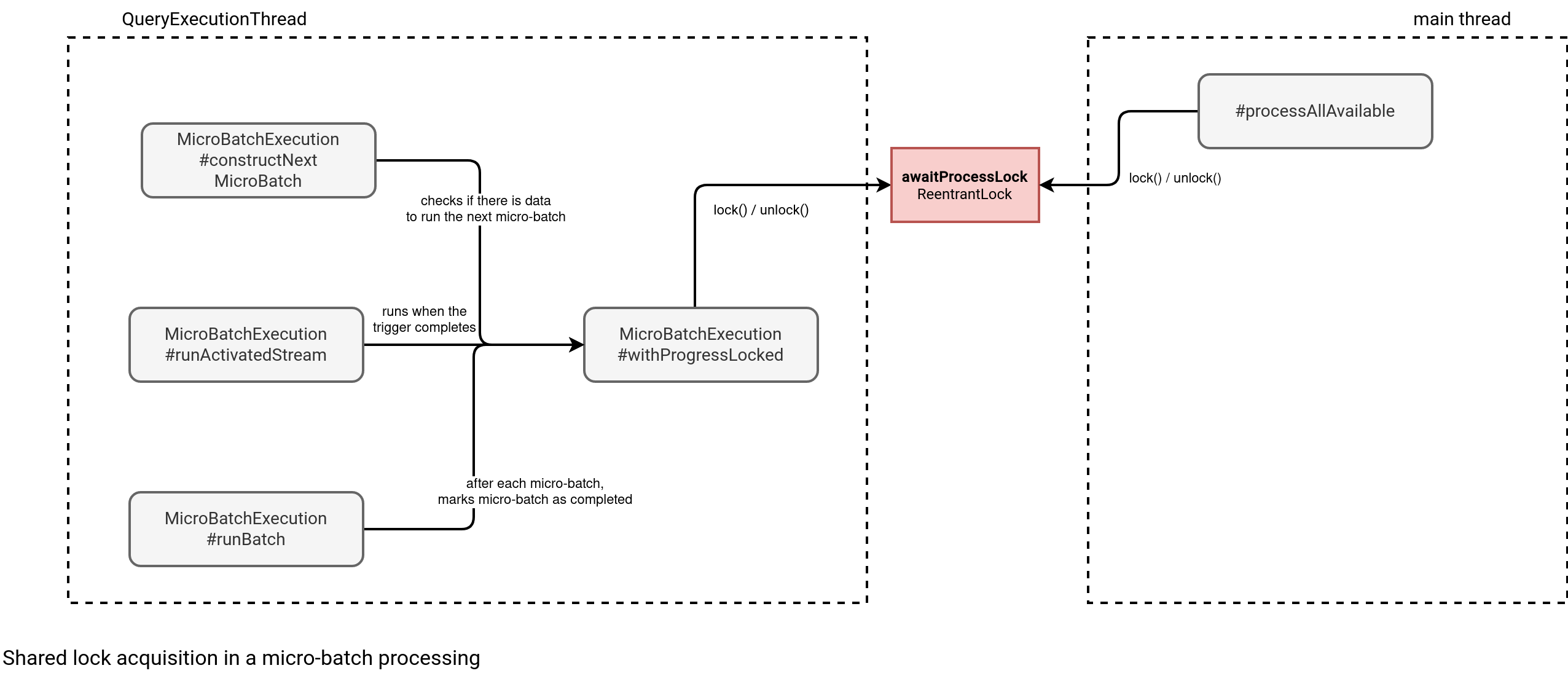
The awaitProgressLock is an ReentrantLock, so a lock that can be acquired many times within a given thread. Put differently, the thread running the streaming query can lock it many times. But to consider the lock as released, the thread should unlock it as many times as well.
When you call the start() method on your stream for the first time, Apache Spark starts a new QueryExecutionThread that runs your processing logic until an error happens or the trigger completes. Therefore, it's a background process. During each micro-batch, the job locks and unlocks the ReentrantLock. Just after starting the query, even before processing the first records, the processAllAvailable gets called and blocks since the lock is acquired by the QueryExecutionThread. Later, the main thread completes and releases the lock. The processAllAvailable can acquire the lock on its turn and enter into the while loop:
while (true) {
awaitProgressLockCondition.await(10000, TimeUnit.MILLISECONDS)
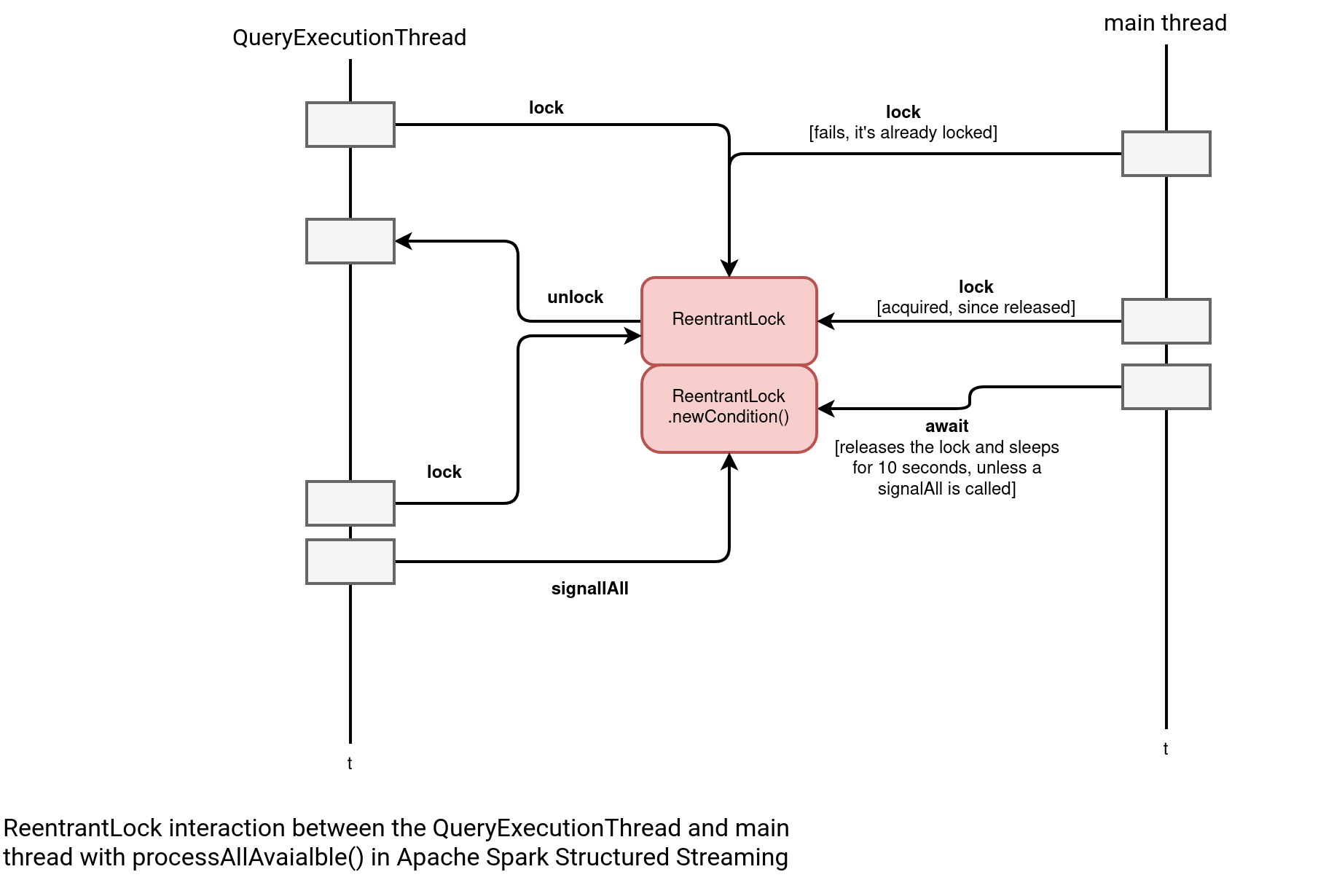
Inside it calls the await that releases the lock and disabled the processAllAvaialble's threads. Meantime, the QueryExecutionThread checks for new data and if there is nothing to process as in our test case, it activates the processAllAvailable's thread by setting the noNewData flag to false and calling the awaitProgressLockCondition.signalAll(). The processAllAvaialble sees no more data to process and exits, releasing the main thread. The following schema summarizes the workflow:
When it comes to the methods interacting with the lock, you can find them below:
To sum up:
- The main thread starts a background thread with the query.
- The query thread is running the first micro-batch and the processAllAvailable tries to acquire the lock but cannot as it's already taken.
- The query thread releases the lock and the processAllAvailable acquires the lock immediately as it's the oldest one waiting for it (ReentrantLock is configured as the fair one, privileging the longest waiting threads).
- The processAllAvailable checks if there is no new data but the flag has been set to false, as the first micro-batch processed some records.
- The processAllAvailable puts itself in the await state by making the lock available again.
- The query thread acquires the lock again and sets the no new data flag to true as there is nothing new to process.
- After setting the flag, the query thread calls the signalAll() of the ReentrantLock's condition.
- The signalAll awakes the processAllAvailable.
- The processAllAvaikable sees no new data. It quits after releasing the lock.
- The main job can now add new data and call the processAllAvailable again. The query execution thread is still running on the background, as we set the trigger to continuously run.
Beware of the processing time trigger > 0 seconds!
As you saw in the schema, only the next triggered micro-batch can tell whether there is no new data to process. Below is one of the Github repository tests executed with a 2 minutes processing time trigger:
For that reason, albeit it looks weird at first glance, the code composition extracted this processing time trigger configuration to make it settable.
The processAllAvailable test
The processAllAvailable-based unit test in my opinion has a simpler semantic than the AvailableNow-based one, since it doesn't require restarting the query. And currently, that's the main visible difference between them, as you can see by yourself in the next snippet:
test_name = sys._getframe().f_code.co_name
spark_session = generate_spark_session[0]
# ...
visits_writer = DatasetWriter(f'/tmp/visits_{test_name}', spark_session)
visits_writer.write_dataframe([visit_1.as_kafka_row()])
# ...
visits_reader: DataFrame = spark_session.readStream.schema('value STRING').json(visits_writer.output_dir)
visit_writer = generate_sessions(visits_reader, devices_to_test, {'processingTime': '0 seconds'})
started_query = visit_writer.foreachBatch(assertions_io.write_results_to_batch_id_partitioned_storage()).start()
started_query.processAllAvailable()
emitted_visits_0 = assertions_io.get_dataframe_to_assert(0)
assert_that(emitted_visits_0).is_empty()
emitted_visits_1 = assertions_io.get_dataframe_to_assert(1)
assert_that(emitted_visits_1).is_empty()
# ...
visits_writer.write_dataframe([visit_2.as_kafka_row()])
started_query.processAllAvailable()
emitted_visits_2 = assertions_io.get_dataframe_to_assert(2)
assert_that(emitted_visits_2).is_empty()
emitted_visits_3 = assertions_io.get_dataframe_to_assert(3)
assert_that(emitted_visits_3).is_length(1)
Again, that's purely subjective opinion, but also the processAllAvailable name is more meaningful than the awaitTermination in the unit tests context. For that reason, it's my preferred way for synchronizing micro-batches. But synchronizing them is not the single challenge. Besides, you also need a way to assert micro-batches results.
Asserting micro-batches
I bet it will not surprise you if I say that one of the easiest scoped assertions methods is the foreachBatch. It's real swiss knife of Apache Spark Structured Streaming that not only gives you a possibility to use the batch API but also to access the micro-batch number, which is important for scoping the results.
An easy way to assert the results is to access them from memory, by the micro-batch index. Below you can find a DataToAssertWriterReader called as a foreachBatch sink:
class DataToAssertWriterReader:
def __init__(self, base_dir: str, spark_session: SparkSession):
self.spark_session = spark_session
self._results_per_micro_batch: Dict[int, List[Dict[str, Any]]] = {}
def write_results_to_batch_id_partitioned_storage(self):
def write_to_test_output_dir(dataframe: DataFrame, batch_number: int):
rows = dataframe.collect()
results = []
for row in rows:
results.append(json.loads(row.value))
self._results_per_micro_batch[batch_number] = results
return write_to_test_output_dir
def get_results_to_assert_for_micro_batch(self, batch_number: int) -> List[Dict[str, Any]]:
return self._results_per_micro_batch[batch_number]
As you can see, the code is relatively easy. It collects all Rows written in a given micro-batch, converts them to a dictionary (json.loads), and accumulates in a list. In the end, it appends the list to the results storage dictionary that is available from the getter.
In your tests you can refer to this class as:
assertions_io = DataToAssertWriterReader(test_name, spark_session)
# ...
visit_writer = generate_sessions(visits_reader, devices_to_test, {'processingTime': '0 seconds'})
started_query = visit_writer.foreachBatch(assertions_io.write_results_to_batch_id_partitioned_storage()).start()
started_query.processAllAvailable()
# ...
emitted_visits_2 = assertions_io.get_results_to_assert_for_micro_batch(2)
assert_that(emitted_visits_2).is_empty()
emitted_visits_3 = assertions_io.get_results_to_assert_for_micro_batch(3)
assert_that(emitted_visits_3).is_length(1)
assert emitted_visits_3[0] == {'visit_id': 'v1', 'user_id': 'user A id',
'start_time': '2024-01-05T10:00:00.000Z',
'end_time': '2024-01-05T10:00:00.000Z',
'visited_pages': [{'page': 'page 2', 'event_time_as_milliseconds': 1704448800000}],
'duration_in_milliseconds': 0}
You clearly see that streaming tests, due to the iterative nature of processing, are different from the batch ones. Thankfully, Apache Spark Structured Streaming comes with processAllAvailable and foreachBatch, which are two convenient ways to orchestrate the tests.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- DAIS 2024: Unit tests - configuration and declaration
- Data+AI Summit 2024 - Retrospective - Apache Spark
- DAIS 2024: Testing framework from the Dataflow model for Apache Spark Structured Streaming
- Data+AI Summit 2024 - Retrospective - Streaming
- Data+AI Summit 2023, retrospective part 2