
Welcome to the second blog post dedicated to the previous Data+AI Summit. This time I'm going to share with you a summary of Apache Spark talks.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Introducing the New Python Data Source API for Apache Spark™
Let's start this blog post with a feature that I briefly introduced last week, a new data source API available in Python! Allison Wang and Ryan Nienhuis explained all the ins and outs, with additional code examples.
Notes from the talk:
- If you tried to implement a custom data source in PySpark, you probably used one of the following implementations:
 The new data source API has several advantages, including integration ease (just use like any other regular data source in your code!), explicit partitioning support, and interoperability across different pipelines.
The new data source API has several advantages, including integration ease (just use like any other regular data source in your code!), explicit partitioning support, and interoperability across different pipelines.
- The API is available for batch and streaming workloads.
- Three steps to create a data source are
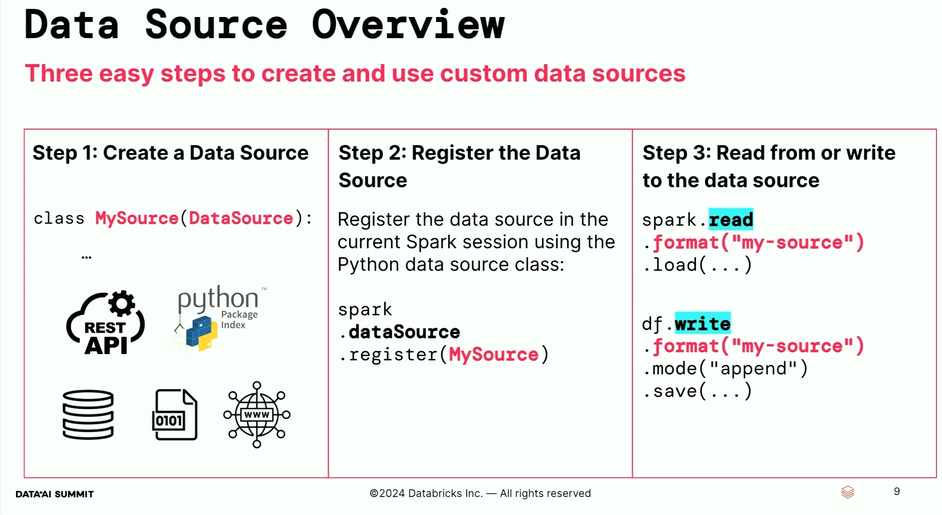
- Data source API focuses on the following attributes:
 The name is the short name you can later reference in your spark.read.format("...") operations. The schema is the default schema that will be used if the user doesn't provide a schema. The reader is the factory method creating a DataSourceReader that physically interacts with the custom data source.
The name is the short name you can later reference in your spark.read.format("...") operations. The schema is the default schema that will be used if the user doesn't provide a schema. The reader is the factory method creating a DataSourceReader that physically interacts with the custom data source. - The interaction between the JVM and Python VM still exists but the serialization overhead got optimized with the usage of Apache Arrow for the data exchange.
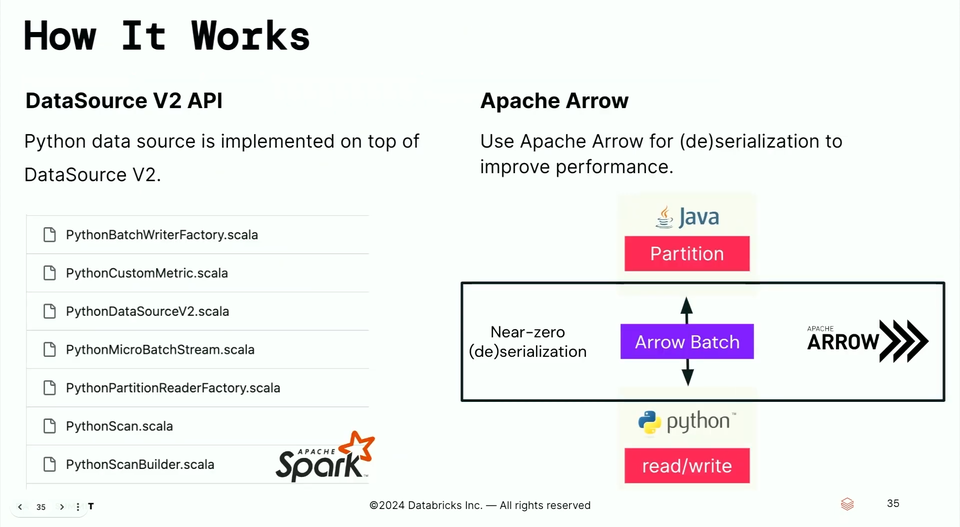
- Some features remain not supported, though such as limit or aggregate push-downs, complete and update output modes.
- Besides the data source, the new API also supports writers (aka sinks).
 The implementation requires a DataStreamWriter that has a possibility to confirm and abort the batch writing with, respectively, commit and abort functions.
The implementation requires a DataStreamWriter that has a possibility to confirm and abort the batch writing with, respectively, commit and abort functions.
Connect with speakers and watch the talk online:
Exploring UDTFs (User-Defined Table Functions) in PySpark
Another new feature in PySpark are User-Defined Table Functions (UDTF), greatly introduced by Haejoon Lee and Takuya Ueshin.
Notes from the talk:
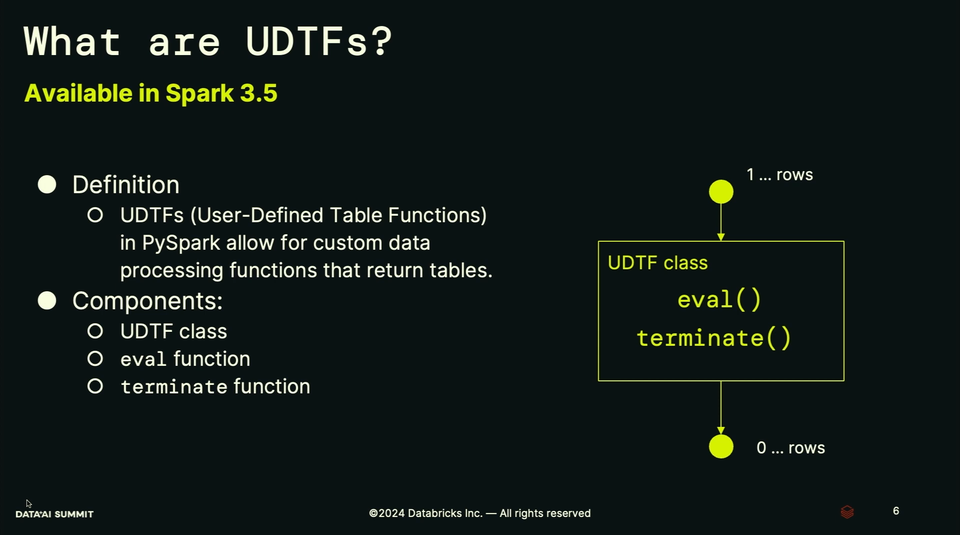
- A UDTF returns a set of rows and not scalar value, as User-Defined Function.
- A UDTF is composed of:
- To use a UDTF, you can register it via spark_session.udtf.register("function_name", MyUdtfFunctionClass) and reference in SQL API, or directly call the function as a part of the DataFrame API:

- The UDTFs are already available in Apache Spark 3.5.0 and you can leverage them for aggregating data or generating multiple rows. However, they have some issues that are going to be addressed in Apache Spark 4.0 with polymorphic UDTFs.
- Polymorphic UDT means support for different input and output schemas in the same function. The UDTFs in Apache Spark 4 has a new method called analyze that determines the output schema from the input parameters. Consequently, the function doesn't include the hardcoded returnType, commented in the snippets below:
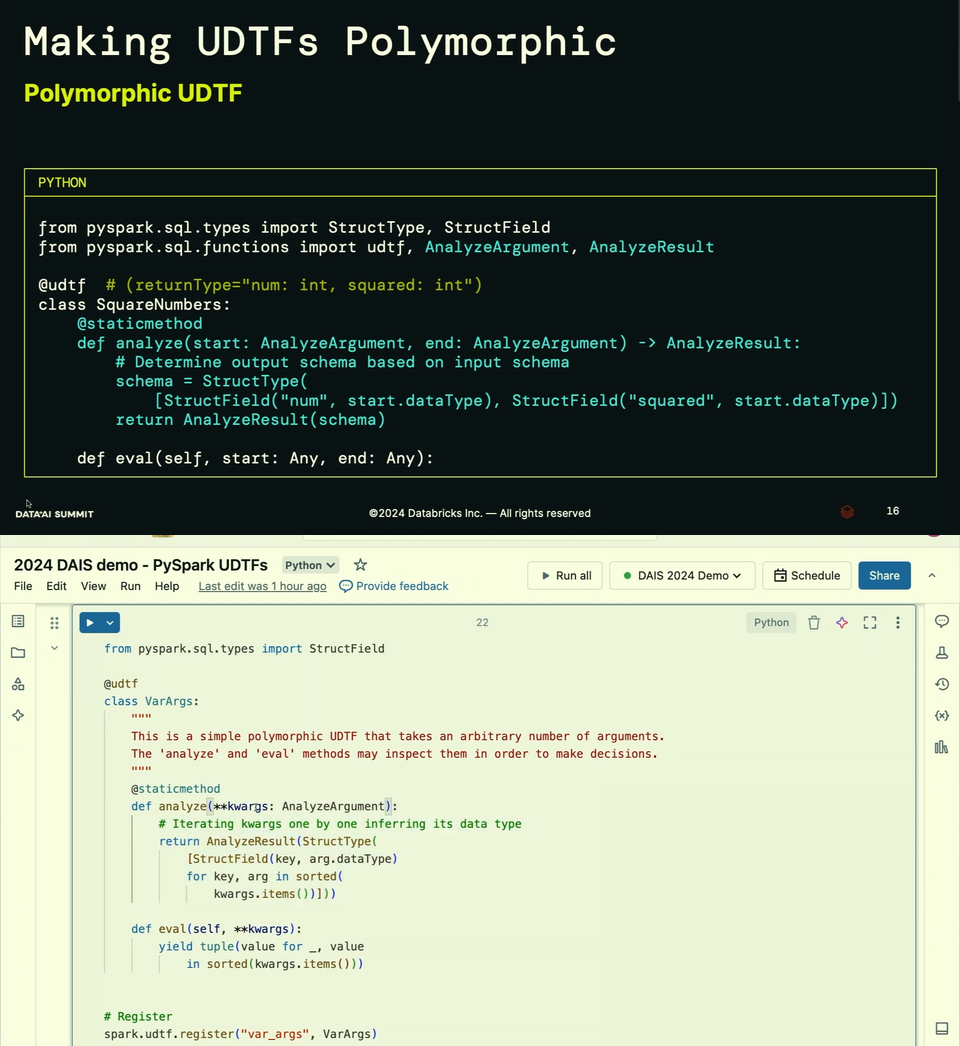
Connect with speakers and watch the talk online:
Dependency Management in Spark Connect: Simple, Isolated, Powerful
Spark Connect has been a top topic for the past year. It also got some attention at the Data+AI Summit. Hyukjin Kwon and Akhil Gudesa shared how to manage dependencies in Spark Connect.
Notes from the talk:
- Although the dependencies are supported nowadays in classical Apache Spark deployments, they all have some drawbacks, such as same version forced for all users:
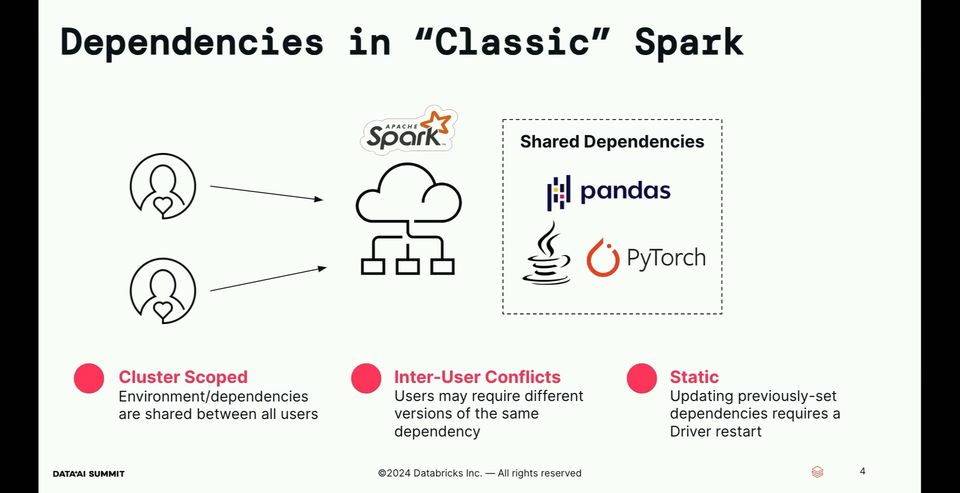 Spark Connect addresses all the three issues with session-scoped isolated dependencies without requiring driver restarts to update those dependencies.
Spark Connect addresses all the three issues with session-scoped isolated dependencies without requiring driver restarts to update those dependencies.
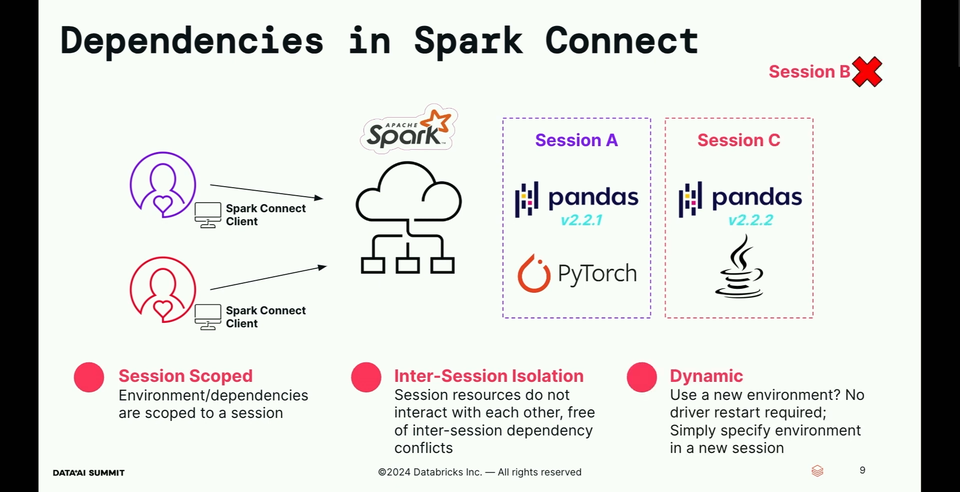
- How does the dependencies isolation work? There is a new, Spark Connect-specific API called AddArtifact.
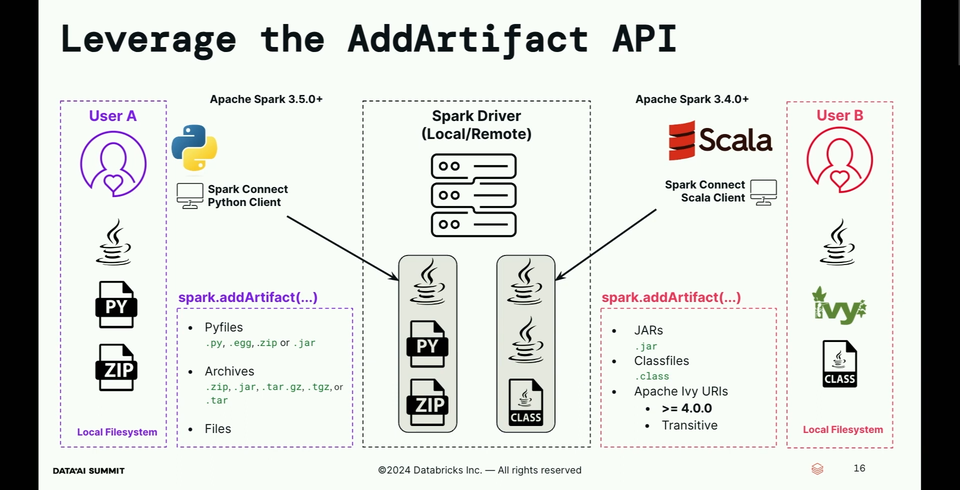
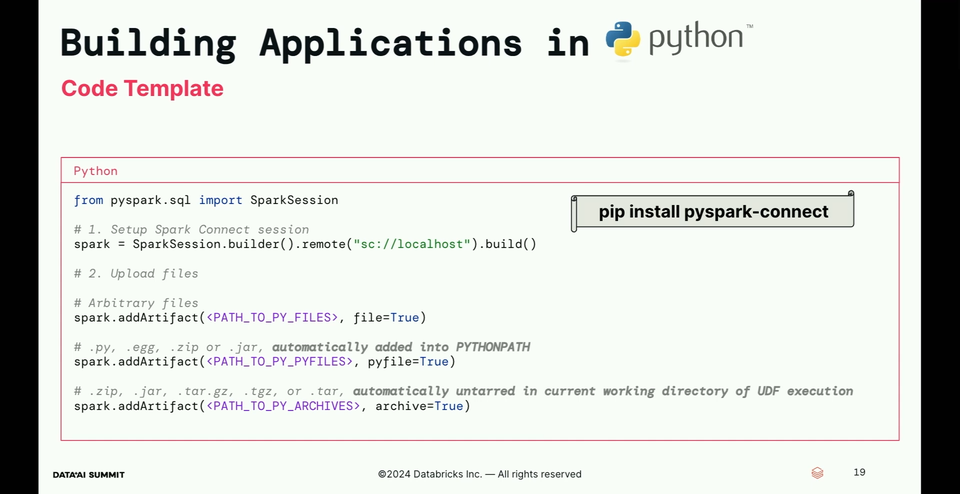
- Python supports three types of files: arbitrary files (files attribute must be set to true), packages or .py files (pyfile attribute set to true), and finally archives (archive set to true).
- Scala version is similar to Python's but since Scala generated bytecode, it has an extra operation sparkSession.registerCassFinder that uploads bytecode from the User-Defined Functions to the executors to make them executable:

Connect with speakers and watch the talk online:
Best Practices for Unit Testing PySpark
Another interesting talk in operationalizing Apache Spark theme was given by Matthew Powers who has contributed to the community with various libraries and ebooks. At the Summit he recalled how to test PySpark jobs locally, without requiring to set up a distributed cluster.
Notes from the talk:
- How unit tests can make a data engineer happier? Matthew greatly resumed it in 5 points:

- But comparing datasets is not easy as besides values, it also involves checking the schemas with all the variances, like column name, type, and nullability.
- How to write unit tests locally? Isolation is the key here as you won't be able to easily test your logic if it's too coupled with all job dependencies. Two slides speak for themselves:
 Same testability workflow applies to the SQL queries.
Same testability workflow applies to the SQL queries.

- Column functions can also be tested but the approach looks more like table-driven tests with the input/expected value pairs defined rowwise.

Connect with speakers and watch the talk online:
Stranger Triumphs: Automating Spark Upgrades & Migrations at Netflix
Two next talks from my list are great examples that Apache Spark is not only about writing data processing jobs. In the first of them Holden Karau and Robert Morck explained how to automate Apache Spark version upgrades at the Netflix scale!
Notes from the talk:
- To start, Holden explained why an obsolete version is bad. Having it in production is a dilemma. On one hand, upgrading your job is not the most exciting task you may face, while on the other, more up-to-date software will make your daily life more comfortable.

- Even though automating upgrades can be an exciting engineering task, the technology is only one face of it. Without involving people by increasing the visibility and change incentives, it might not work well. At Netflix, Holden and Robert has created "Spark Migration Newsletter" where they share the upgrade status for the pipeline.
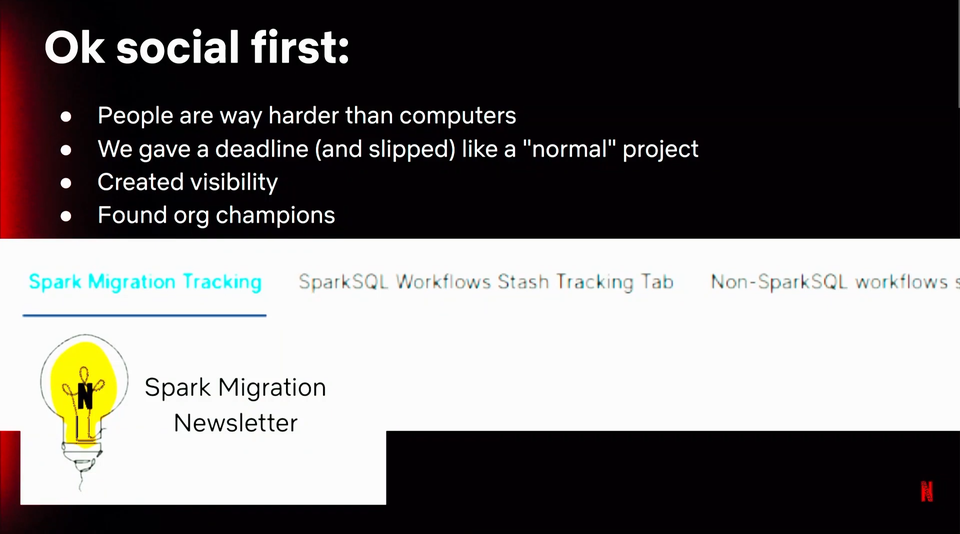
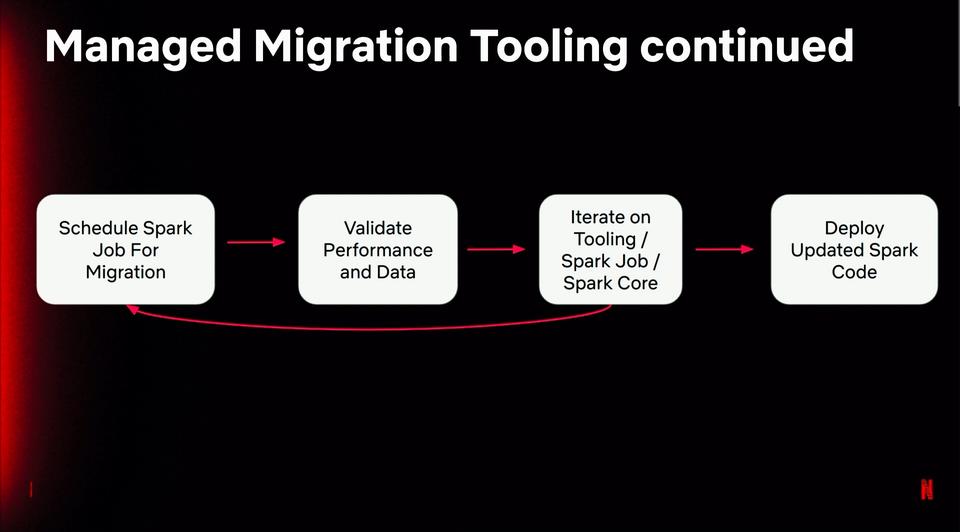
- Later in the talk, Robert defined what it means to migrate a job to a newer version. Unfortunately, the way is not straightforward and might require multiple iteration:
- And not only the process itself may be challenging. The Managed Migration Tooling is also an advanced piece of architecture relying on multiple layers. The Apache Spark jobs for the migration and validation are only a part of the solution. Another part, equally important, is more user-centric and it provides observability capabilities.
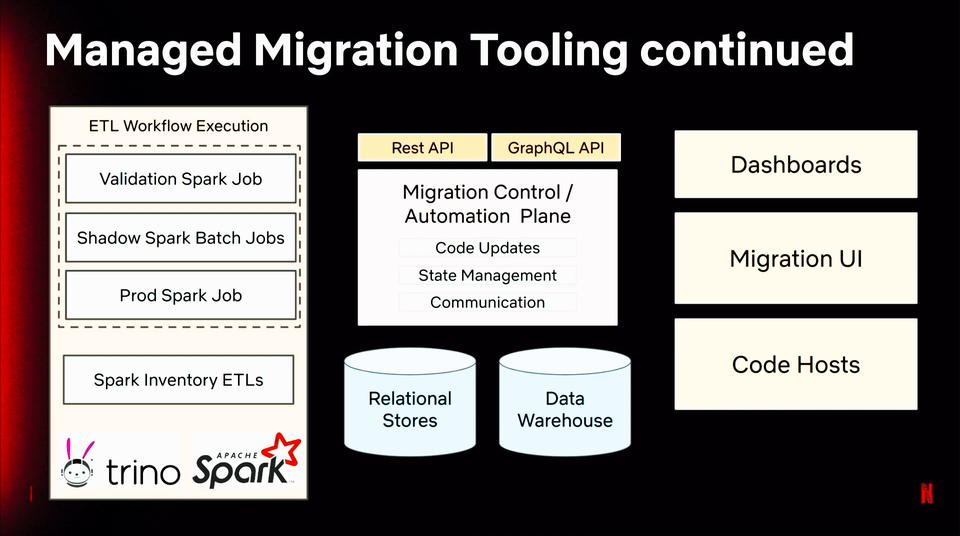
- Pro tip: if you consider analyzing the code, prefer Abstract Syntax Tree perspective. There are not only available Open Source libraries for them but also they are more easily manageable than complex Regular Expressions.
 How to use them? There are 2 big steps: analyzing Apache Spark release notes and migration manager to catch some rules, and trying to run Apache Spark shadow job with the new version on the migrated jobs to detect all missed breaking changes.
How to use them? There are 2 big steps: analyzing Apache Spark release notes and migration manager to catch some rules, and trying to run Apache Spark shadow job with the new version on the migrated jobs to detect all missed breaking changes.
- But the migration is not only about changing the version of your jobs. It is also about ensuring the new job performs as well as the old one. Hope is definitively a plan here (:D), unit tests are not always present, ...the best remaining choice is the data. To validate the migration, the migration tool schedules three jobs and performs a Migrate-Audit-Discard pattern that either promotes the upgrade to production, or discards it. BTW, why running three jobs and not two? It helps spot issues on non-deterministic jobs or jobs with side effects without involving end users.

- Despite all these efforts, the tools has still few things to improve

- The scale of the migration was massive!
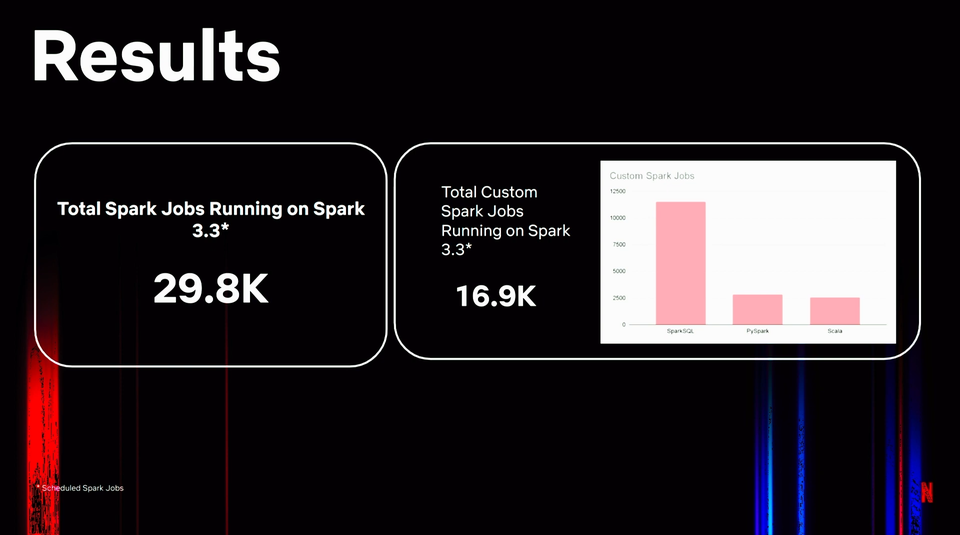
Connect with speakers and watch the talk online:
Uber's Batch Analytics Evolution from Hive to Spark
At similar scale that in the Spark upgrades, Kumudini Kakwani and Akshayaprakash Sharma performed batch jobs migrations from Apache Hive to Apache Spark at Uber! Also, in an automated way.
Notes from the talk:
- Uber was a big user of Hive. There were nearly 18k ETLs and 5 millions monthly scheduled queries. These numbers only prove the challenge Kumudini and Akshayaprakash had to face while migrating them to Apache Spark. By the way, the migration was motivated by the following reasons:

- The migration process was based on 2 steps. The first was the automated migration that was translating HiveQL to Spark SQL, and validating the outcome. The second step was the source code update. Overall, the process looks like this:
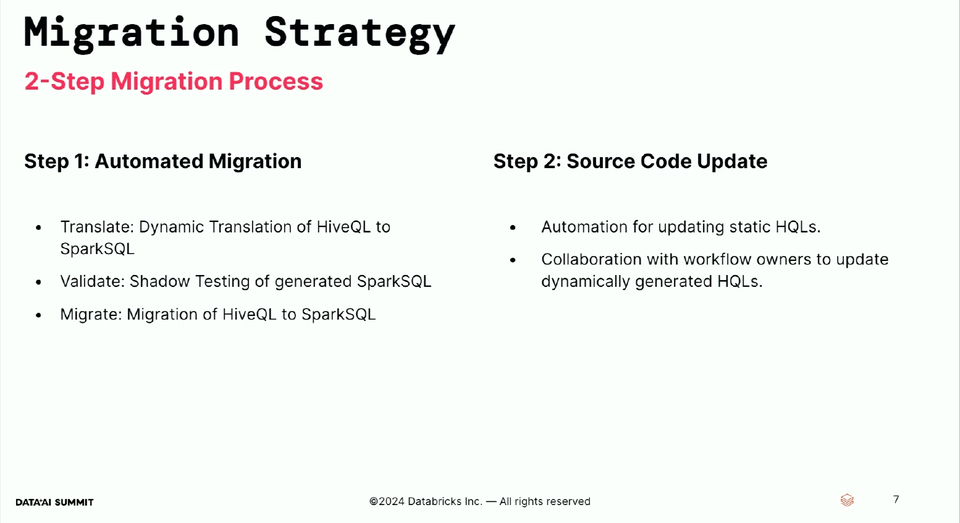 The architecture relies on a Shadow Testing Framework that intercepts the Hive QL queries, translates them to Apache Spark SQL, and executes on top of the same input data. The overall workflow includes also a validation step that compares the outcome of the migrated queries, for the data part, as well as for the performance.
The architecture relies on a Shadow Testing Framework that intercepts the Hive QL queries, translates them to Apache Spark SQL, and executes on top of the same input data. The overall workflow includes also a validation step that compares the outcome of the migrated queries, for the data part, as well as for the performance.

- Despite the automated nature, the framework also has some limitations, such as:
- Race conditions when the input table was missing while the shadow testing was executing.
- Moved files from original location; the mitigation consists of copying all files to load to a load data location before making it available for Hive tables.
- Schema mismatches when the shadow tables was created with an outdated schema. Solution was to configure the correct schema within the shadow framework
- Non-deterministic functions for data validation. The solution was to identify and exclude them from the validation.
- Floating point arithmetics leading to rounding errors and false positives. The solution was to round the columns and add tolerance of 1% in the tests.
- Stringified JSON had to be transformed into ordered JSON before computing the validation checksum.
- Frequently updated datasets leading to inconsistencies between Hive and Spark results. The solution was to snapshot them and run both Hive and Spark queries before performing the validation.
- If you plan to migrate Hive queries, there are some serious differences with Apache Spark that you should consider:

Connect with speakers and watch the talk online:
Apache Spark was only one of Open Source libraries present in the Summit. Another one is Delta Lake that I'm going to focus on in the next blog post of the series.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- DAIS 2024: Unit tests - configuration and declaration
- DAIS 2024: Orchestrating and scoping assertions in Apache Spark Structured Streaming
- DAIS 2024: Testing framework from the Dataflow model for Apache Spark Structured Streaming
- Data+AI Summit 2024 - Retrospective - Streaming
- Data+AI Summit 2023, retrospective part 2