
That's often a dilemma, whether we should put multiple sinks working on the same data source in the same or in different Apache Spark Structured Streaming applications? Both solutions may be valid depending on your use case but let's focus here on the former one including multiple sinks together.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
.foreachBatch
If you are looking for writing the same dataset to many different sinks, you should consider the foreachBatch sink.
Multiple sinks - example
The example we're going to use is rather simple. There are some files with numbers in each new line. Our application takes them as soon as they arrive and multiples them by 2 and 3 in 2 different transformations. In the end it writes the results in separate sinks. Although we can avoid using 2 sinks here with a foreachBatch construct, for the sake of exercise, we're using the 2 sinks versions:
val filesWithNumbers = sparkSession.readStream.text(s"${basePath}/data").as[Int]
val multipliedBy2 = filesWithNumbers.map(nr => nr * 2)
val multipliedBy2Writer = multipliedBy2.writeStream.format("json")
.option("path", s"${basePath}/output/sink-1")
.option("checkpointLocation", s"${basePath}/checkpoint/sink-1")
.start()
val multipliedBy3 = filesWithNumbers.map(nr => nr * 3)
val multipliedBy3Writer = multipliedBy3.writeStream.format("json")
.option("path", s"${basePath}/output/sink-2")
.option("checkpointLocation", s"${basePath}/checkpoint/sink-2")
.start()
sparkSession.streams.awaitAnyTermination()
There are few things you already see from the code and the UI:
- There are 2 checkpoint locations. A checkpoint is associated with the sink and not the data source [even though it represents the latter!], so you have 2 places to take care of in case of any maintenance or restart.
- The application creates 2 separate jobs that you can see in the UI:
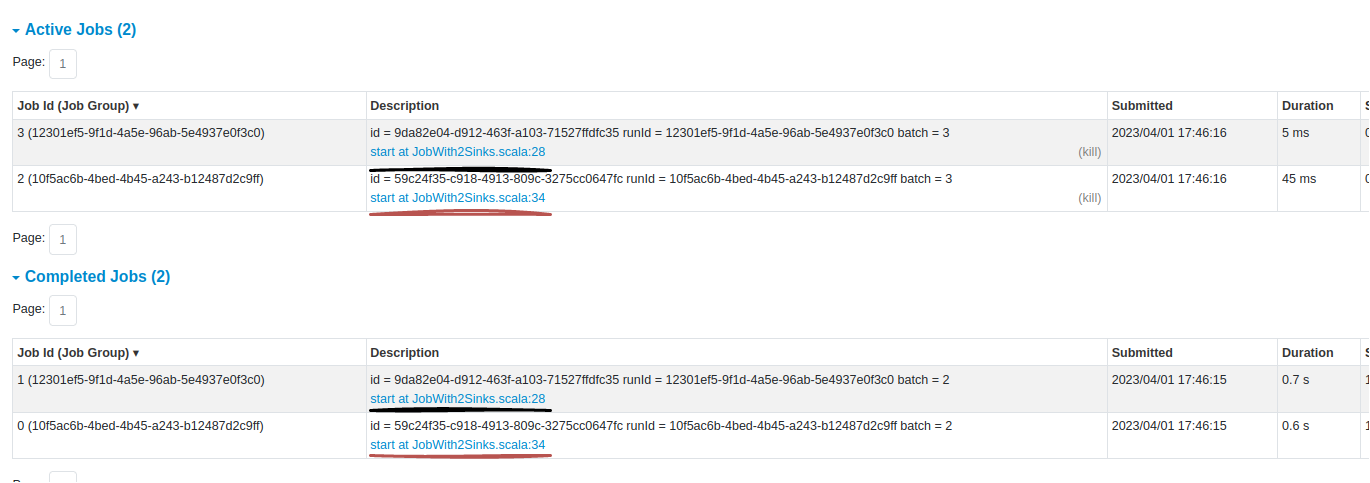
- Both jobs run in the same execution context, so they share the compute resources.
- The jobs are interdependent. The call of the sparkSession.streams.awaitAnyTermination() stops all jobs whenever one of them fails or finishes.
That's all we can see from the appearance. But as you know, the appearance can be deceptive and it definitely is for our 2-sinks job. Why?
Deeping delve...
A closer look at the Spark UI already shows the point of having 2 streaming sinks:
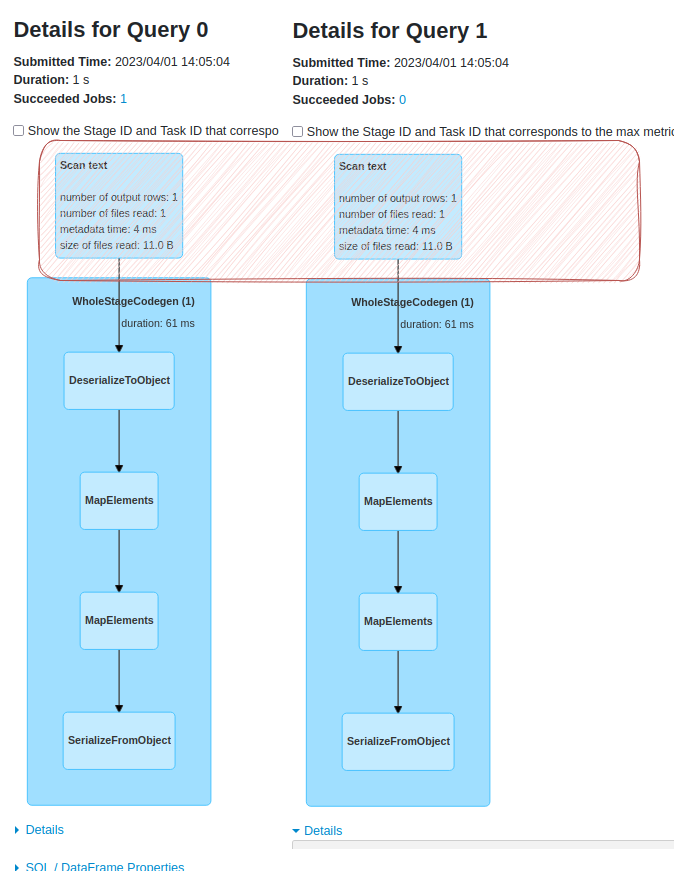
Indeed, the data source is read twice, once for each sink! "We should cache it" - you may be thinking right now. Yes, we should but the cache is not supported on the Structured Streaming DataFrames. When you call it, you'll get this a little bit misleading, error message:
Exception in thread "main" org.apache.spark.sql.AnalysisException: Queries with streaming sources must be executed with writeStream.start();
FileSource[/tmp/wfc/structured-streaming-2-sinks//data]
at org.apache.spark.sql.catalyst.analysis.UnsupportedOperationChecker$.throwError(UnsupportedOperationChecker.scala:447)
at org.apache.spark.sql.catalyst.analysis.UnsupportedOperationChecker$.$anonfun$checkForBatch$1(UnsupportedOperationChecker.scala:38)
at org.apache.spark.sql.catalyst.analysis.UnsupportedOperationChecker$.$anonfun$checkForBatch$1$adapted(UnsupportedOperationChecker.scala:36)
Why is that double reading? Each data sink creates a DataStreamWriter that initializes the Sink implementation corresponding to the job method and starts a query. Starting the query involves creating a new instance of StreamingQueryWrapper and inherently, the StreamExecution (MicroBatchExecution or ContinuousExecution, depending on the query mode). The queries are independent and both generate dedicated physical execution plans, hence separate data reading processes.

Reading consistency
Does it mean the 2 queries in the same application can process separate data? After all, the checkpoints are different, so technically both track different offsets. Let's change the data source to the rate stream with some randomness added by the sleep:
val filesWithNumbers = sparkSession
.readStream
.format("rate")
.option("rowsPerSecond", 1)
.load
.select("value").as[Long]
.map(nrAsString => {
Thread.sleep(Random.nextInt(3000))
println(s"Converting $nrAsString")
nrAsString.toInt
})
//
// Replaced to the same transformation to compare the output size
val multipliedBy2 = filesWithNumbers.map(nr => nr * 3)
If you run the code, you'll see the first jobs processing the same volume of data. But these numbers will change with time:
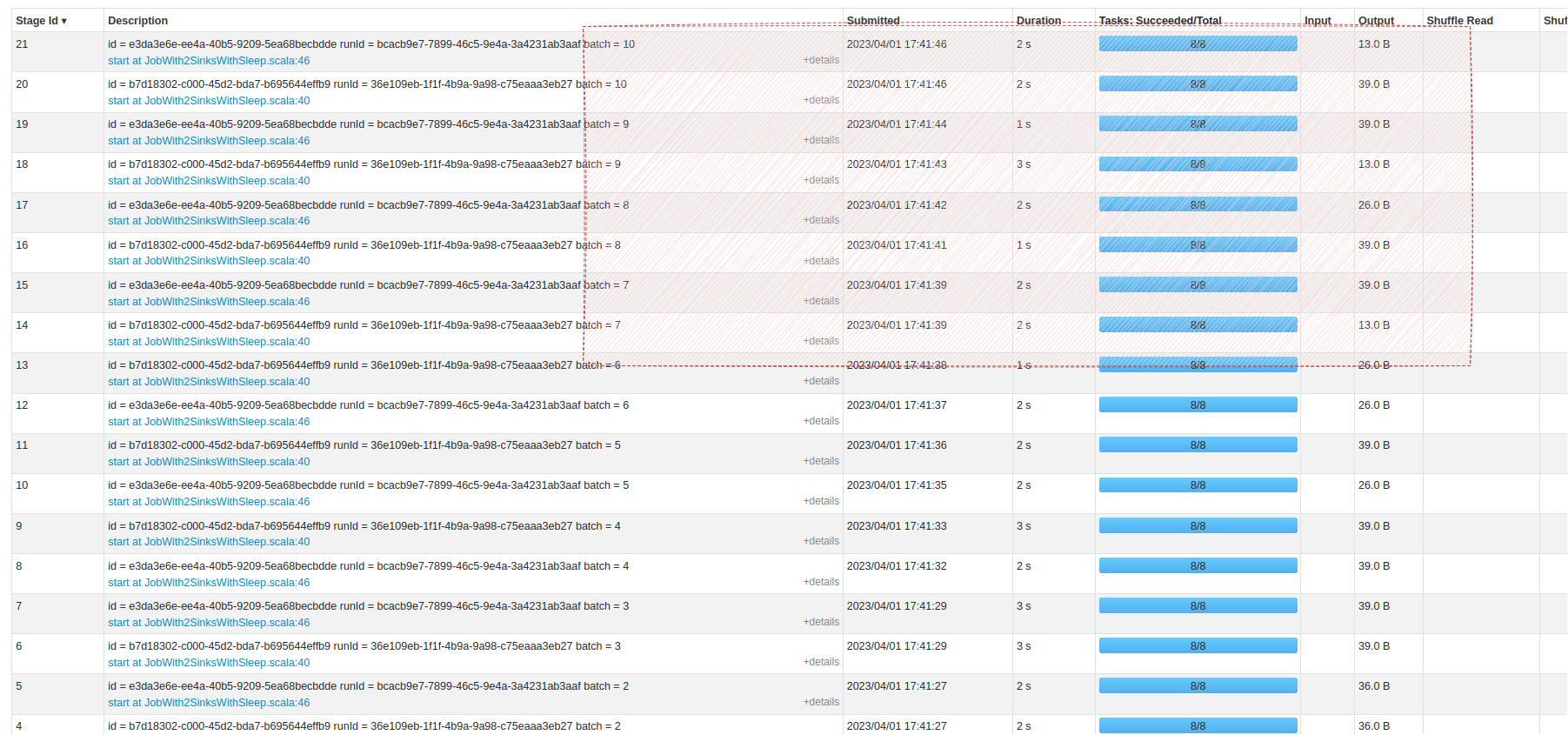
You can see that despite this open possibility of declaring multiple Structured Streaming queries in the same application, there are some important consequences. The queries are separate, so they have different lifecycles.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Multiple queries running in Apache Spark Structured Streaming here:
Related blog posts:
- Spark Declarative Pipelines internals
- Spark Declarative Pipelines, going further
- Spark Declarative Pipelines 101
Have you ever ran multiple queries in the same #ApacheSpark Structured Streaming job? If no, you should know several implications that I summarized in the new blog post ? https://t.co/tJuAOtmn9J
— Bartosz Konieczny (@waitingforcode) July 7, 2023