
Streaming jobs are supposed to run continuously but it applies to the data processing logic. After all, sometimes you may need to release a new job package with upgraded dependencies or improved business logic. What happens then?
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The key thing to understand is how a query runs. In the blog post we're going to focus on the micro-batch runner as the continuous one is still experimental. The MicroBatchExecution is responsible for running a micro-batch. It inherits several behavior from its parent, the StreamExecution, such as starting and running the streaming query. But the inheritance doesn't apply to the stop action declared in the MicroBatchExecution, as illustrated below:
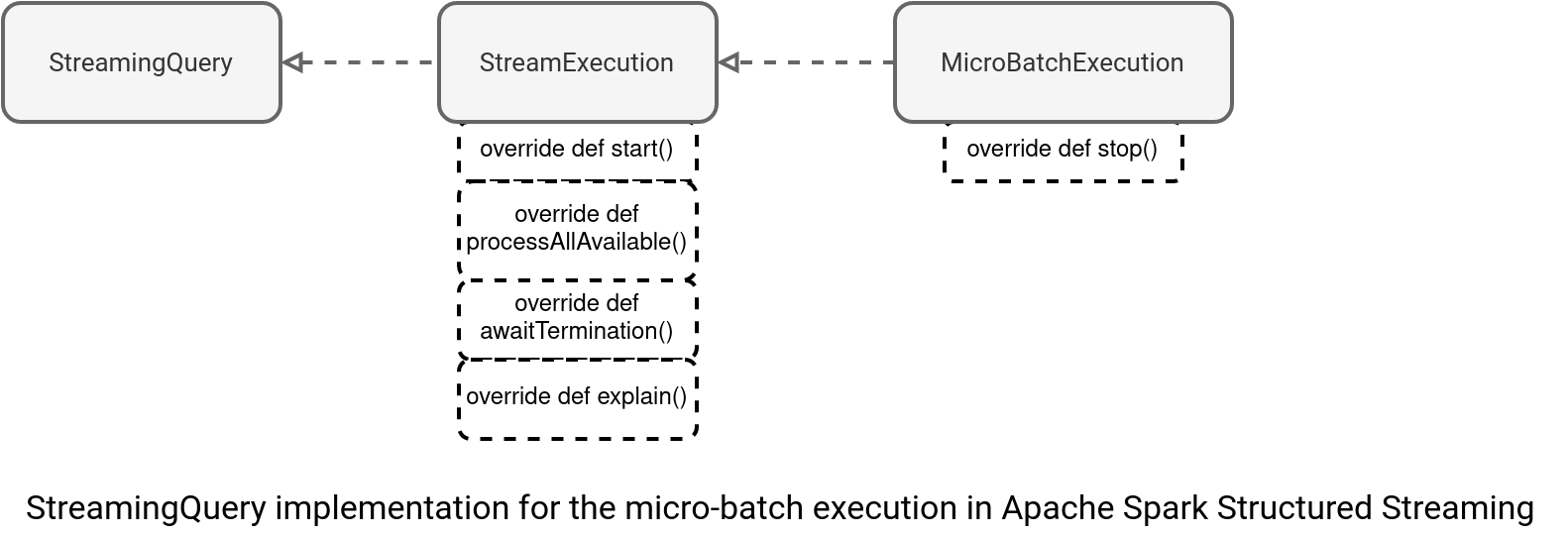
I know, these names are pretty mystic if you have never taken a look at the source code. Let's understand them better with a deep dive.
Query execution thread
A Structured Streaming query runs as a part of a QueryExecutionThread defined in StreamExecution as follows:
val queryExecutionThread: QueryExecutionThread = new QueryExecutionThread(s"stream execution thread for $prettyIdString") {
override def run(): Unit = {
// To fix call site like "run at <unknown>:0", we bridge the call site from the caller
// thread to this micro batch thread
sparkSession.sparkContext.setCallSite(callSite)
JobArtifactSet.withActiveJobArtifactState(jobArtifactState) {
runStream()
}
}
}
As you can see, it triggers a micro-batch execution in the runStream() method that calls a runActivatedStream of the MicroBatchExecution. It's where the real data processing happens. Although it doesn't stop the query, the stop action automatically impacts the QueryExecutionThread, and especially the catch case:
private def isInterruptedByStop(e: Throwable, sc: SparkContext): Boolean = {
if (state.get == TERMINATED) {
StreamExecution.isInterruptionException(e, sc)
} else {
false
}
}
def isInterruptionException(e: Throwable, sc: SparkContext): Boolean = e match {
// InterruptedIOException - thrown when an I/O operation is interrupted
// ClosedByInterruptException - thrown when an I/O operation upon a channel is interrupted
case _: InterruptedException | _: InterruptedIOException | _: ClosedByInterruptException =>
true
// ...
}
} catch {
case e if isInterruptedByStop(e, sparkSession.sparkContext) =>
// interrupted by stop()
updateStatusMessage("Stopped")
case e: Throwable =>
From that you can deduce the first thing. There might be something that throws an exception while stopping the QueryExecutionThread. To understand what, let's take a step back and see what can stop the query.
The stop method
Unsurprisingly, it's the stop() method form the MicroBatchExecution that interrupts the thread. But it's not the single action that happens here. First, the function updates the query state to TERMINATED. The state marks the streaming job as being intentionally interrupted by the stop() method.
Next the stop method cancels the job group, i.e. all jobs related to the given micro-batch. Currently, it does it twice, just in case some jobs would have been triggered meantime:
if (queryExecutionThread.isAlive) {
sparkSession.sparkContext.cancelJobGroup(runId.toString)
interruptAndAwaitExecutionThreadTermination()
// microBatchThread may spawn new jobs, so we need to cancel again to prevent a leak
sparkSession.sparkContext.cancelJobGroup(runId.toString)
}
Stopping the execution thread consists of relying on the Java Thread API, more particularly on the interrupt() and join() method. At this moment it's worth mentioning that the join waits some time for the thread to die. By default, Apache Spark will wait forever but you can configure this behavior with the spark.sql.streaming.stopTimeout property.
If after asking to stop the query, the thread is still alive, Apache Spark throws a TimeoutException:
if (queryExecutionThread.isAlive) {
val stackTraceException = new SparkException("The stream thread was last executing:")
stackTraceException.setStackTrace(queryExecutionThread.getStackTrace)
val timeoutException = new TimeoutException(
s"Stream Execution thread for stream $prettyIdString failed to stop within $timeout " +
s"milliseconds (specified by ${SQLConf.STREAMING_STOP_TIMEOUT.key}). See the cause on " +
s"what was being executed in the streaming query thread.")
timeoutException.initCause(stackTraceException)
throw timeoutException
}
Stopping from outside
The question is, how to stop the query. Normally, you can kill a Spark application via the spark-submit --kill command. However, it doesn't interact with the aforementioned stop query. I mean, it does indeed kill the application but more by the interaction with the resource manager rather than by the interaction with the stop() method. For example, the Kubernetes operator does the following when you involve the kill argument:
private class KillApplication extends K8sSubmitOp {
override def executeOnPod(pName: String, namespace: Option[String], sparkConf: SparkConf)
(implicit client: KubernetesClient): Unit = {
val podToDelete = getPod(namespace, pName)
if (Option(podToDelete).isDefined) {
getGracePeriod(sparkConf) match {
case Some(period) => podToDelete.withGracePeriod(period).delete()
case _ => podToDelete.delete()
}
} else {
printMessage("Application not found.")
}
As you can see, it interacts directly with Kubernetes primitives (pod) rather than Spark's classes. Therefore, you may opt for another approach. A common solution here is to rely on an external signal to stop the job, ideally, gracefully. Let's see the snippet:
new Thread(() => {
val consumerProperties = new Properties()
consumerProperties.put("bootstrap.servers", "localhost:9094")
val kafkaConsumer = new KafkaConsumer[String, String](consumerProperties)
kafkaConsumer.subscribe(util.Arrays.asList("markers"))
while (true) {
val messages = kafkaConsumer.poll(Duration.ofSeconds(5))
val shouldStopTheJob = messages.records("markers").iterator().hasNext
if (shouldStopTheJob) {
println(s"Received a marker, stopping the query now...${startedAggregationQuery.id}")
while (startedAggregationQuery.status.isTriggerActive) {}
startedAggregationQuery.stop()
Thread.currentThread().interrupt()
Thread.currentThread().join(TimeUnit.SECONDS.toMillis(5))
} else {
println(s"Empty record ${messages.count()}")
}
}
}).start()
Put differently, whenever the micro-batch is processing the data, do nothing. But as soon as there is nothing left in the micro-batch, initiate the stop. However, there is still a tiny chance that Spark triggers the next micro-batch and completes the first task before you initialize the stop action and Spark sends the job group cancel request. If you want to see the full snippet, you can check the Github repo.
Why not stopping with a shutdown hook?
That's a good question. As a reminder, shutdown hook is a way of asking the JVM to do run the code defined in the hook before exiting. As a result, you could run the graceful shutdown directly from the job kill command just by adding this simple snippet:
sys.addShutdownHook {
println(s"SHUTDOWN!!!!!!!! ==> ${startedAggregationQuery.status}")
while (startedAggregationQuery.status.isTriggerActive) {}
startedAggregationQuery.stop()
}
Unfortunately, it's not that simple as it may involve race conditions between Apache Spark's hook that stops the SparkContext and yours. After running this code in my local example, I couldn't make it work because of this exception:
SHUTDOWN!!!!!!!! ==> {
"message" : "Processing new data",
"isDataAvailable" : true,
"isTriggerActive" : true
}
Exception in thread "shutdownHook1" java.lang.IllegalStateException: Cannot call methods on a stopped SparkContext.
This stopped SparkContext was created at:
org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:1093)
com.waitingforcode.VisitsCounterInWindows$.main(VisitsCounterInWindows.scala:17)
com.waitingforcode.VisitsCounterInWindows.main(VisitsCounterInWindows.scala)
The currently active SparkContext was created at:
org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:1093)
com.waitingforcode.VisitsCounterInWindows$.main(VisitsCounterInWindows.scala:17)
com.waitingforcode.VisitsCounterInWindows.main(VisitsCounterInWindows.scala)
at org.apache.spark.SparkContext.assertNotStopped(SparkContext.scala:122)
at org.apache.spark.SparkContext.cancelJobGroup(SparkContext.scala:2577)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution.stop(MicroBatchExecution.scala:207)
at org.apache.spark.sql.execution.streaming.StreamingQueryWrapper.stop(StreamingQueryWrapper.scala:61)
As you can see, the print worked but the stop() invocation led to the IllegalStateException. Why? Because Apache Spark registers hooks on its own. The problematic one for us here is the SparkContext shutdown hook added at the SparkContext's creation time:
class SparkContext(config: SparkConf) extends Logging {
// Make sure the context is stopped if the user forgets about it. This avoids leaving
// unfinished event logs around after the JVM exits cleanly. It doesn't help if the JVM
// is killed, though.
logDebug("Adding shutdown hook") // force eager creation of logger
_shutdownHookRef = ShutdownHookManager.addShutdownHook(
ShutdownHookManager.SPARK_CONTEXT_SHUTDOWN_PRIORITY) { () =>
logInfo("Invoking stop() from shutdown hook")
try {
stop()
} catch {
case e: Throwable =>
logWarning("Ignoring Exception while stopping SparkContext from shutdown hook", e)
}
As you can see, the hook stops the SparkContext and obviously, without the context we lose the ability to manipulate our streaming job.
Starting the query is definitively an easier task than stopping it. The difficulty comes from the asynchronous model. Even within the stop method you saw this duplicated cancel job group, just in case there are some unexpected job planned after the stop initialization. For that reason, it's not easy to have a clean query stopping mechanism. But with the external marker, you should be able to implement the best effort graceful shutdown.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩