
Unexpected things happen and sooner or later, any pipeline can fail. Hopefully, sometimes the errors may be temporary and automatically recovered after some retries. What if the job is a streaming one? Let's see here how Apache Spark Structured Streaming handles task retries in micro-batch and continuous modes!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Task scheduling
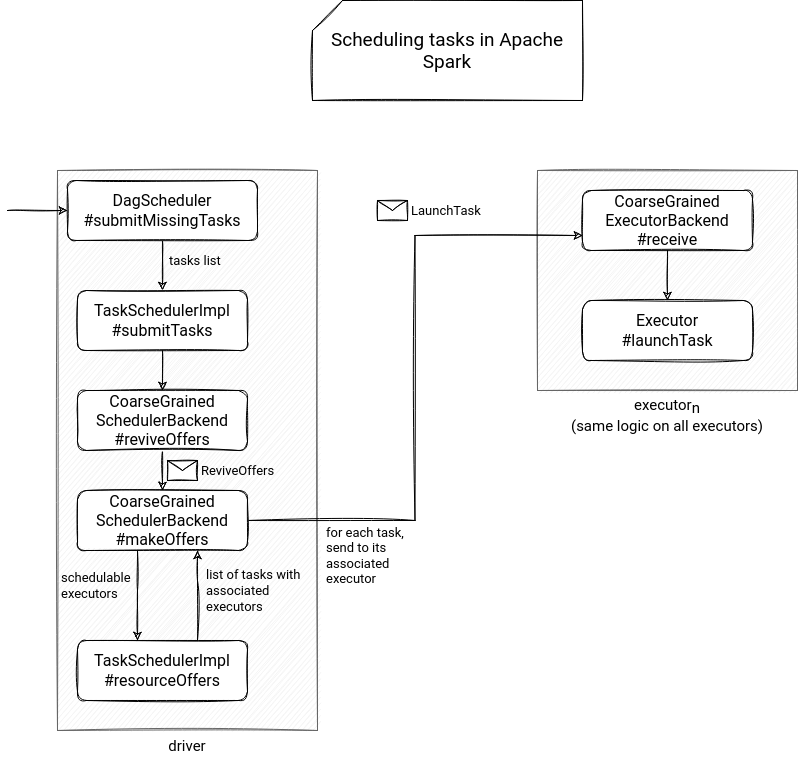
To understand the retry mechanism, it's good to explain the task scheduling logic first. Everything starts when the DAGScheduler defines the stage to compute. It first checks whether the stage has some missing tasks and no missing parent stages. If yes, it passes the list of stage tasks from the submitMissingTasks to the TaskSchedulerImpl#submitTasks method.
Of course, the operation runs on the driver. Inside the submitTasks, the TaskSchedulerImpl instance does some setup work and calls the SchedulerBackend#reviveOffers() method. Since there are 3 backends depending on the runtime environment (LocalSchedulerBackend, StandaloneSchedulerBackend, CoarseGrainedSchedulerBackend), I will focus here on the one you will certainly use on production, the CoarseGrainedSchedulerBackend.
Inside the reviveOffers, the backend - everything still happens on the driver - sends a ReviveOffers message to itself. And that's the moment when the real scheduling begins! Upon receiving this message, the driver backend calls a makeOffers method which under-the-hood, does the following:
- prepares a list of executors that can run the stage tasks
- passes the list of executors to TaskSchedulerImpl#resourceOffers methods which returns a list of tasks having an executor associated
- the scheduler backend takes the list and sends a LaunchTask message to the executor associated with the task instance
The executor backend intercepts the message and calls the Executor#launchTask method. This method creates a Runnable task instance and adds it to the worker thread pool. At this moment, the task can start if the executor has enough compute capacity.
Handling failures in micro-batch
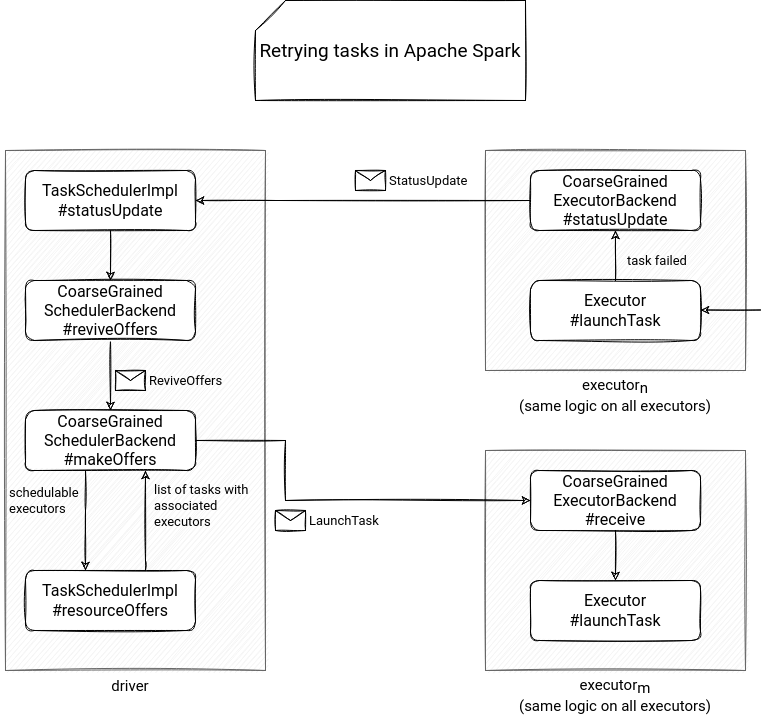
The previous section introduced the main classes involved in the task scheduling. They should help find out what happens with the retries, because the flow is quite similar. The Runnable instance of the task introduced in the previous part runs in a try-catch block. If any exception happens, the catch block handles it and communicates the failure to the executor by calling the CoarseGrainedExecutorBackend#statusUpdate method.
Inside this method, the executor builds a StatusUpdate message and sends it to the driver. The message arrives to the CoarseGrainedSchedulerBackend instance and the driver can now update the task state in the TaskSchedulerImpl#statusUpdate. Depending on the task outcome, the scheduler either marks it as successfully executed or enqueues it for a retry:
private[spark] class TaskSchedulerImpl(
val sc: SparkContext,
val maxTaskFailures: Int,
isLocal: Boolean = false,
clock: Clock = new SystemClock)
extends TaskScheduler with Logging {
// ...
def statusUpdate(tid: Long, state: TaskState, serializedData: ByteBuffer): Unit = {
// ...
if (state == TaskState.FINISHED) {
taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData)
} else if (Set(TaskState.FAILED, TaskState.KILLED, TaskState.LOST).contains(state)) {
taskResultGetter.enqueueFailedTask(taskSet, tid, state, serializedData)
}
The enqueueFailedTask calls the CoarseGrainedSchedulerBackend#reviveOffers() method and the task gets scheduled to an executor. Also, the failed task executor status gets updated CoarseGrainedSchedulerBackend#makeOffers(executorId: String) is called to schedule tasks on the executor. TODO: maybe reformulate + show that in DEMO!
Handling failures in continuous trigger
The retry semantic presented above works for Apache Spark SQL batch and Structured Streaming micro-batch pipelines, but what about the Structured Streaming continuous trigger? Well, you won't see any changes - at least in the task scheduling part. So in the logs you should see things like "Task 1 in stage 0.0 failed 6 times, most recent failure: Lost task 1.5 in stage 0.0 (TID 6) (192.168.0.55 executor driver): org.apache.spark.sql.execution.streaming.continuous.ContinuousTaskRetryException: Continuous execution does not support task retry" but actually the retry won't be real!
Everything because of the ContinuousDataSourceRDD#compute running the continuous streaming query:
override def compute(split: Partition, context: TaskContext): Iterator[InternalRow] = {
// If attempt number isn't 0, this is a task retry, which we don't support.
if (context.attemptNumber() != 0) {
throw new ContinuousTaskRetryException()
}
The difference with the micro-batch comes from a different semantic. Continuous processing creates one long-running task for each input partition, avoiding the micro-batch scheduling overhead. Because of that, several points are more difficult to implement. Even the simple retries counter is not obvious since each task lives through the continuous query and not the micro-batch! An alternative discussed in the Task level retry for continuous processing Pull Request was a global retry mechanism. In this solution, all the tasks are restarted from the last committed epoch of one of the long-running processes that failed. However, it's not implemented yet, and as you know, the continuous engine remains marked as "experimental", so there should be many things going on in the new releases!
If you want to see some of the presented points in action, I prepared a short demo using the LocalSchedulerBackend for the presentation simplicity:
To sum up, two things to remember. Micro-batch supports task retries through the same mechanism as the batch pipelines. On the other hand, the continuous mode, which by the way is still (3.2.0) marked as experimental, doesn't support task retries due to a different execution semantic. Unlike batch and micro-batch, it runs one long-running task per partition.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Task retries in Apache Spark Structured Streaming here:
- How to explain SchedulerBackend.reviveOffers()? [SPARK-23033][SS][Follow Up] Task level retry for continuous processing DriverEndpoint CoarseGrainedSchedulerBackend
Related blog posts:
- Spark Declarative Pipelines internals
- Spark Declarative Pipelines, going further
- Spark Declarative Pipelines 101
How does Apache Spark handle task retries in #StructuredStreaming? That's the question I tried to answer in the new blog post ? https://t.co/D3ZjqHGsIt
— Bartosz Konieczny (@waitingforcode) January 15, 2022