
I've already written about watermarks in a few places in the blog but despite that, I still find things to refresh. One of them is the watermark used to filter out the late data, which will be the topic of this blog post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Reminder, watermark in streaming systems has 2 purposes. The first of them is to control how late data can be processed. This property inherently impacts another one which is, when a state should be removed from the state store. The latter is also called a Garbage Collection Watermark.
Even though the definition looks simple, Apache Spark has a specificity about watermarks because they cannot be used without stateful processing. Put another way, if you write a job like that:
val clicksWithWatermark = clicksStream.toDF
.withWatermark("clickTime", "10 minutes")
val query = clicksWithWatermark.writeStream.format("console").option("truncate", false)
.start()
...do not expect your streaming query filtering out records older than the 10 minutes watermark because simply there is no watermark in the execution plan!
== Physical Plan == WriteToDataSourceV2 MicroBatchWrite[epoch: 0, writer: ConsoleWriter[numRows=20, truncate=false]], org.apache.spark.sql.execution.datasources.v2.DataSourceV2Strategy$$Lambda$2062/0x0000000800fcc040@4c443787 +- EventTimeWatermark clickTime#3: timestamp, 10 minutes +- *(1) Project [clickAdId#2, clickTime#3] +- MicroBatchScan[clickAdId#2, clickTime#3] MemoryStreamDataSource
Why so? After all, the EventTimeWatermark node is there. Let's try to understand this in the next section.
Late data filtering
The watermark logical node does have a physical representation, the EventTimeWatermarkExec. However, it has 2 roles:
- Generating the watermark by invoking the internal accumulator at the physical execution:
case class EventTimeWatermarkExec(eventTime: Attribute, delay: CalendarInterval, child: SparkPlan) extends UnaryExecNode { val eventTimeStats = new EventTimeStatsAccum() val delayMs = EventTimeWatermark.getDelayMs(delay) sparkContext.register(eventTimeStats) override protected def doExecute(): RDD[InternalRow] = { child.execute().mapPartitions { iter => val getEventTime = UnsafeProjection.create(eventTime :: Nil, child.output) iter.map { row => eventTimeStats.add(microsToMillis(getEventTime(row).getLong(0))) row } } - Reporting the watermark when the micro-batch finishes. It's the role of the WatermarkTracker's updateWatermark(executedPlan: SparkPlan) method called by the markMicroBatchEnd:
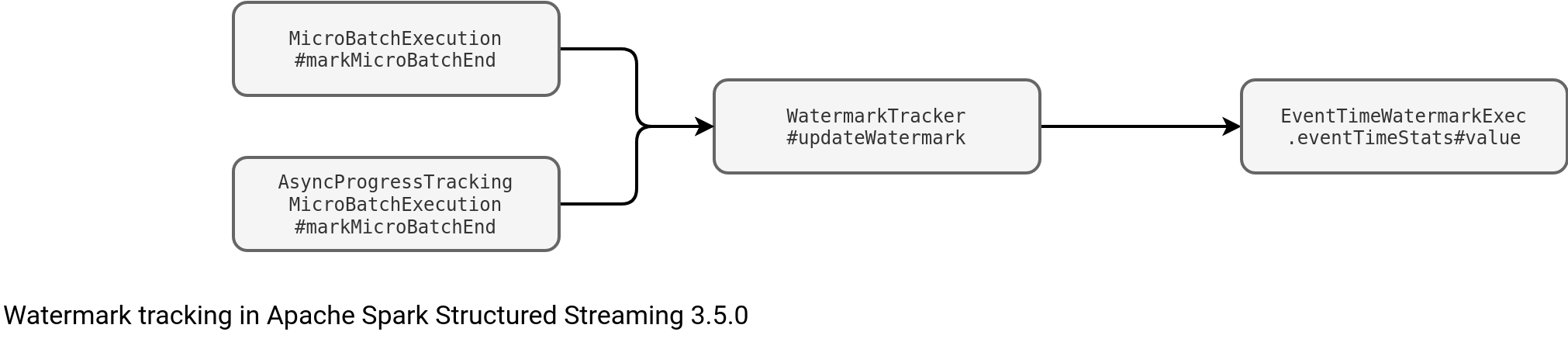
The node is not involved in the late data filtering! The filtering is a side-effect of the watermark tracking because it directly uses the watermark value injected to the stateful processing nodes:
class IncrementalExecution(...)
override val rule: PartialFunction[SparkPlan, SparkPlan] = {
case s: StateStoreSaveExec if s.stateInfo.isDefined =>
s.copy(
eventTimeWatermarkForLateEvents = inputWatermarkForLateEvents(s.stateInfo.get),
eventTimeWatermarkForEviction = inputWatermarkForEviction(s.stateInfo.get)
)
case s: SessionWindowStateStoreSaveExec if s.stateInfo.isDefined =>
s.copy(
eventTimeWatermarkForLateEvents = inputWatermarkForLateEvents(s.stateInfo.get),
eventTimeWatermarkForEviction = inputWatermarkForEviction(s.stateInfo.get)
)
As a result, it's the stateful physical node which is responsible for the state eviction and late data filtering. But it couldn't do this without the information provided by the watermark node.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩