
Initially I wanted to include the session windows in the blog post about Structured Streaming changes. But I changed my mind when I saw how many things it involves!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Session windows 101
Working with sessions in Apache Spark before the 3.2 release was possible with the arbitrary stateful processing. Although technically doable, this solution has some drawbacks. It uses a low-latency API and this API is not yet available in PySpark. It also requires a bit effort to cover the multiple sessions use case. Those are the main reasons why Jungtaek Lim and Liang-Chi Hsieh worked on sessions windows.
A session window is the window of a special, session type. It means that instead of working on a time column, it operates on one or multiple columns of any type. The time is still involved, though. It has a time-based parameter is called gap duration which serves to define the session end time. From that standpoint, a window session is dynamic because the end time changes with every new event integrated to the window.
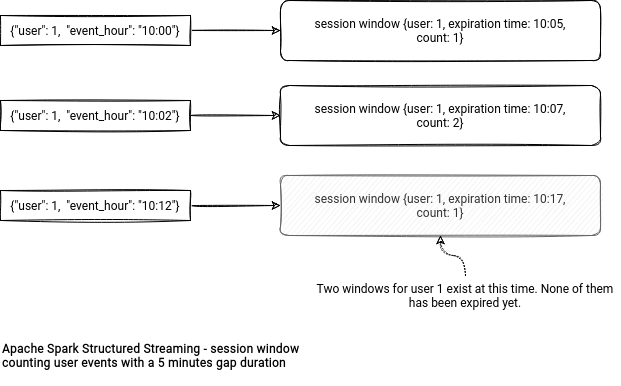
Session window - aggregation
In the API, the window session looks like in the following snippet:
.groupBy(session_window($"event_time", "10 seconds") as 'session, 'id)
.agg(functions.count("*").as("numEvents"))
At a glance, the session window looks exactly like an aggregation. And indeed, it is an aggregation! To see that, let's analyze the execution flow. When Apache Spark meets the session window in the code, it first adds a new column to the projected expression. The column is of a struct type and has 2 attributes called start and end. As you can deduce, this struct is the session window representation of every row. Just below you can find an example for a session window bounded by an event_time column, a 10 seconds gap duration, and a 25 minutes watermark (T1500000ms):
+- Project [named_struct(start, precisetimestampconversion(precisetimestampconversion(event_time#25-T1500000ms, TimestampType, LongType), LongType, TimestampType), end, precisetimestampconversion(precisetimestampconversion(event_time#25-T1500000ms + 10 seconds, TimestampType, LongType), LongType, TimestampType)) AS session_window#36-T1500000ms, id#26]
The logical rule responsible for creating this node is SessionWindowing. An interesting thing here is the usage of metadata! The window has a spark.sessionWindow attribute set to true which is used in some places during the physical planning.
During the physical planning, Apache Spark uses a rule from the StatefulAggregationStrategy and delegates the plan creation to the AggUtils.planStreamingAggregationForSession. The names are quite self-explanatory, don't they? Let's see what's inside!
Physical planning
The planning starts with a creation of the partial aggregation for the windows. In other words, Apache Spark will run the specified aggregation locally, before doing the shuffle. After that, the engine will check the value for the spark.sql.streaming.sessionWindow.merge.sessions.in.local.partition configuration entry (false by default). When set to true, Apache Spark merges the session windows before the shuffle (= a kind of partial aggregation of the windows). This operation uses the same node as the final windows merge, so let me skip it here. The physical plan described here looks then like:
+- *(1) HashAggregate(keys=[session_window#36-T1500000ms, id#26], functions=[partial_count(1)], output=[session_window#36-T1500000ms, id#26, count#64L])
+- *(1) Project [named_struct(start, precisetimestampconversion(precisetimestampconversion(event_time#25-T1500000ms, TimestampType, LongType), LongType, TimestampType), end, precisetimestampconversion(precisetimestampconversion(event_time#25-T1500000ms + 10 seconds, TimestampType, LongType), LongType, TimestampType)) AS session_window#36-T1500000ms, id#26]
+- *(1) Filter (isnotnull(event_time#25-T1500000ms) AND (precisetimestampconversion(precisetimestampconversion(event_time#25-T1500000ms + 10 seconds, TimestampType, LongType), LongType, TimestampType) > precisetimestampconversion(precisetimestampconversion(event_time#25-T1500000ms, TimestampType, LongType), LongType, TimestampType)))
+- EventTimeWatermark event_time#25: timestamp, 25 minutes
+- Project [from_json(StructField(event_time,TimestampType,true), cast(value#8 as string), Some(Europe/Paris)).event_time AS event_time#25, from_json(StructField(id,IntegerType,true), cast(value#8 as string), Some(Europe/Paris)).id AS id#26]
+- StreamingRelation kafka, [key#7, value#8, topic#9, partition#10, offset#11L, timestamp#12, timestampType#13]
Once thes local operations are done, it's time for shuffling the data. The shuffle is followed by a SessionWindowStateStoreRestoreExec physical node. An interesting point about it is the required input data ordering:
override def requiredChildOrdering: Seq[Seq[SortOrder]] = {
Seq((keyWithoutSessionExpressions ++ Seq(sessionExpression)).map(SortOrder(_, Ascending)))
}
This operation dynamically adds a sort node to the plan so that Apache Spark can sort the shuffled rows by the grouping column(s) and the session window:
+- *(2) Sort [id#26 ASC NULLS FIRST, session_window#36-T1500000ms ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(id#26, 2), ENSURE_REQUIREMENTS, [id=#50]
State store restore interaction
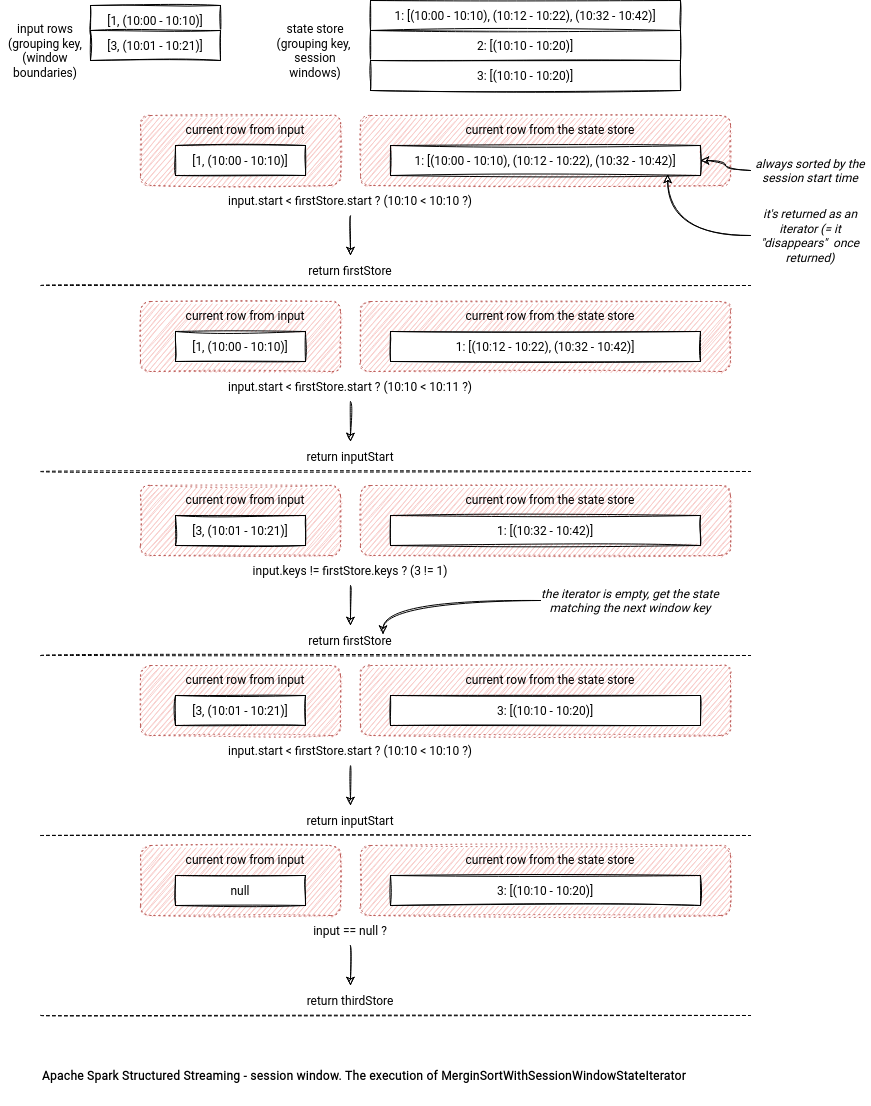
The sorted rows are required for an efficient execution of the SessionWindowStateStoreRestore operation. Under-the-hood it uses a MergingSortWithSessionWindowStateIterator iterator to return the sorted input and existing session window rows. The result of the operation is sorted by the grouping keys and the session start time.
To get the existing sessions, the iterator interacts with the state store and uses the prefix scan feature explained in the last section. The iterator doesn't communicate with the state store directly. Instead, it uses an intermediary state manager from the StreamingSessionWindowStateManager class.
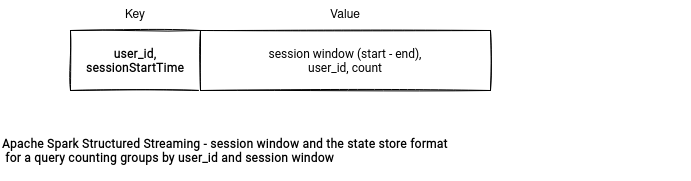
During the iteration, the process uses a mutable state where it stores the current session read either from the state store or from the input. Whichever is returned, Apache Spark resets the state variable, so that the iterator can read the next input row or the next session window from the state store. Does it mean the restore operation returns all the windows from the state store? No. The algorithm always gets the session corresponding to the input rows. Let's see the execution details in the following schema:
Merging
In the next step Apache Spark combines the shuffled windows with the ones opened from the state store. It happens inside the MergingSessionsExec which also exposes the data from an iterator using a mutable local state. The iterator is called MergingSessionsIterator and since it's the main abstraction of this physical node, let's focus exclusively on it here.
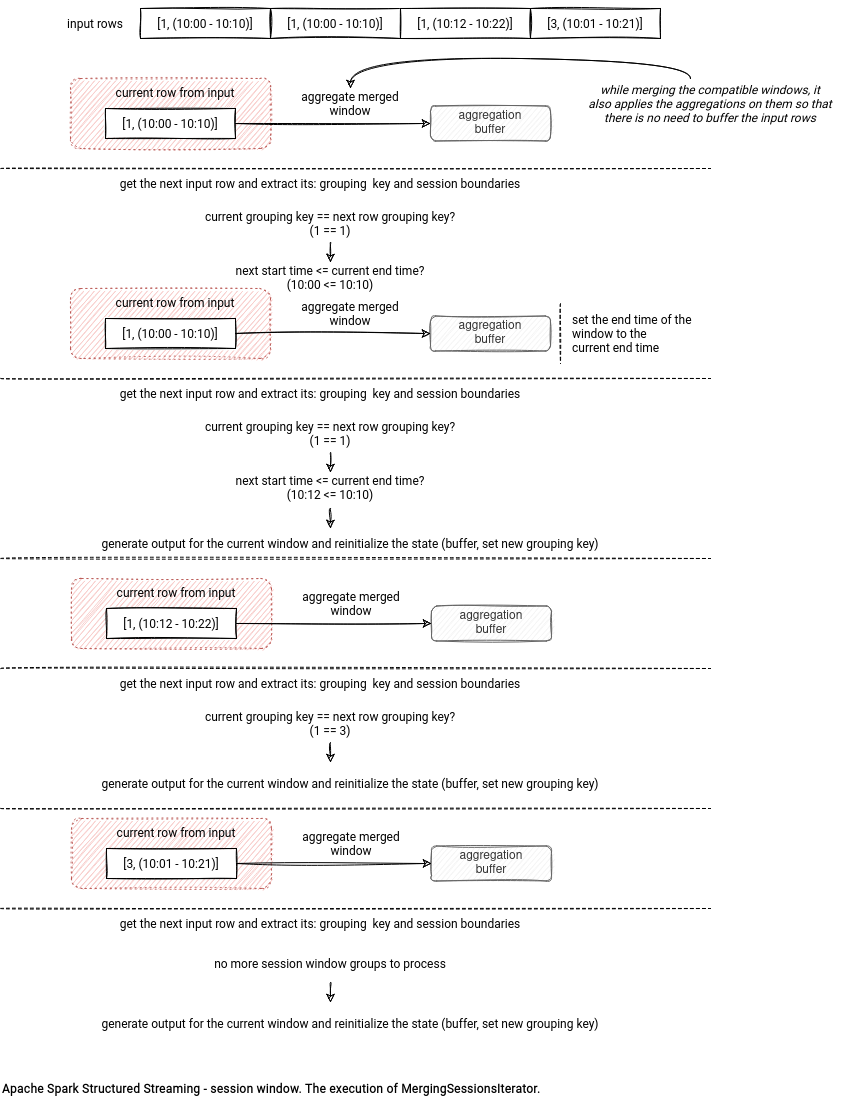
The iterator processes the sorted session windows generated in the previous step. Each processing step consists of:
- comparing the grouping keys; if different, it considers a new session should start
- if the grouping keys are the same, the iterator starts by checking the sorting condition:
if (sessionStart < getSessionStart(currentSession)) { errorOnIterator = true throw new IllegalStateException("Input iterator is not sorted based on session!") } - when the input data is correctly sorted, the current input row can either be included in the current session or not - the former happens if its start time is smaller than the current session's end time. In that case, the current session's end time gets expanded and the input processed. Otherwise it means that we're dealing with a new session for the same group. The algorithm will then append the existing session to the sessions buffer and set a new current session to the iteration context.
The input processing consists of applying the aggregation function to the input and so far accumulated results for the window. The following schema should shed some light on the used algorithm:
The final state store interaction
Finally, after performing the aggregation, the session window saves all results to the state store from the SessionWindowStateStoreSaveExec. What happens inside depends on the configured output mode. For the Complete mode, the state store manager returns all rows:
case Some(Complete) =>
allUpdatesTimeMs += timeTakenMs {
putToStore(iter, store)
}
commitTimeMs += timeTakenMs {
stateManager.commit(store)
}
setStoreMetrics(store)
stateManager.iterator(store).map { row =>
numOutputRows += 1
row
}
The Append mode only returns the expired windows regarding the watermark condition:
case Some(Append) =>
allUpdatesTimeMs += timeTakenMs {
putToStore(iter, store)
}
val removalStartTimeNs = System.nanoTime
new NextIterator[InternalRow] {
private val removedIter = stateManager.removeByValueCondition(
store, watermarkPredicateForData.get.eval)
override protected def getNext(): InternalRow = {
if (!removedIter.hasNext) {
finished = true
null
} else {
numRemovedStateRows += 1
numOutputRows += 1
removedIter.next()
}
}
override protected def close(): Unit = {
allRemovalsTimeMs += NANOSECONDS.toMillis(System.nanoTime - removalStartTimeNs)
commitTimeMs += timeTakenMs { store.commit() }
setStoreMetrics(store)
setOperatorMetrics()
}
}
Prefix scan
And before I terminate this blog post, I would like to shortly introduce a new state store feature added to comply with the session window scan requirement. At first glance, it's "only" a new function in the StateStore API with the following signature:
def prefixScan(prefixKey: UnsafeRow): Iterator[UnsafeRowPair]
However, it has some interesting details. First, it won't be used all the time. The usage is conditioned by the presence of the numColsPrefixKey parameter in the StateStoreProvider's init method. For example, if it's present for RocksDB, the state store backed will use a different underlying storage format storing the splitted key (prefix + suffix, more in RocksDB state store blog post). So, the prefix scan implementation will naturally depend on the used backend. RocksDB will rely on its prefix scan native feature whereas HDFS-backed store will use a dedicated map structure for that:
class PrefixScannableHDFSBackedStateStoreMap(
keySchema: StructType,
numColsPrefixKey: Int) extends HDFSBackedStateStoreMap {
private val map = new HDFSBackedStateStoreMap.MapType()
private val prefixKeyToKeysMap = new java.util.concurrent.ConcurrentHashMap[
UnsafeRow, mutable.Set[UnsafeRow]]()
// …
override def prefixScan(prefixKey: UnsafeRow): Iterator[UnsafeRowPair] = {
val unsafeRowPair = new UnsafeRowPair()
prefixKeyToKeysMap.getOrDefault(prefixKey, mutable.Set.empty[UnsafeRow])
.iterator
.map { key => unsafeRowPair.withRows(key, map.get(key)) }
}
override def put(key: UnsafeRow, value: UnsafeRow): UnsafeRow = {
val ret = map.put(key, value)
val prefixKey = prefixKeyProjection(key).copy()
prefixKeyToKeysMap.compute(prefixKey, (_, v) => {
if (v == null) {
val set = new mutable.HashSet[UnsafeRow]()
set.add(key)
set
} else {
v.add(key)
v
}
})
ret
}
What is the link between the prefix scan and the session windows? The StreamingSessionWindowStateManagerImplV1 uses them in the read from state store operation:
class MergingSortWithSessionWindowStateIterator(
// ...
) {
private def mayFillCurrentStateRow(): Unit = {
// ...
if (currentRowFromInput != null && currentRowFromInput.keys != currentSessionKey) {
// We expect a small number of sessions per group key, so materializing them
// and sorting wouldn't hurt much. The important thing is that we shouldn't buffer input
// rows to sort with existing sessions.
val unsortedIter = stateManager.getSessions(store, currentRowFromInput.keys)
val unsortedList = unsortedIter.map(_.copy()).toList
}
class StreamingSessionWindowStateManagerImplV1(
keyWithoutSessionExpressions: Seq[Attribute],
sessionExpression: Attribute,
valueAttributes: Seq[Attribute])
extends StreamingSessionWindowStateManager with Logging {
// ...
override def getSessions(store: ReadStateStore, key: UnsafeRow): Iterator[UnsafeRow] =
getSessionsWithKeys(store, key).map(_.value)
private def getSessionsWithKeys(
store: ReadStateStore,
key: UnsafeRow): Iterator[UnsafeRowPair] = {
store.prefixScan(key)
}
The window session is a powerful addition to the already existing windows in Apache Spark. And it supports both streaming and batch use cases! It's then a good high-level alternative to any session-based aggregation.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.2.0 - session windows here:
- EventTime based sessionization (session window) Native Support of Session Window in Spark Structured Streaming
Related blog posts:
It's time to discover the 2nd interesting feature of #StructuredStreaming, the window sessions! More details in the new blog post ? https://t.co/uIjRg3tELG
— Bartosz Konieczny (@waitingforcode) October 30, 2021