
It's big news for Apache Spark Structured Streaming users. RocksDB is now available as a Vanilla Spark-backed state store backend!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Initialization
To use the RocksDB state store, you have to explicitly define a provider class in the Apache Spark configuration: .config("spark.sql.streaming.stateStore.providerClass", "org.apache.spark.sql.execution.streaming.state.RocksDBStateStoreProvider"). The StateStore companion object's createAndInit method will later initialize the provider instance and call the RocksDBStateStoreProvider's init method, where the provider :
- memorizes the schemas for key and value of the state
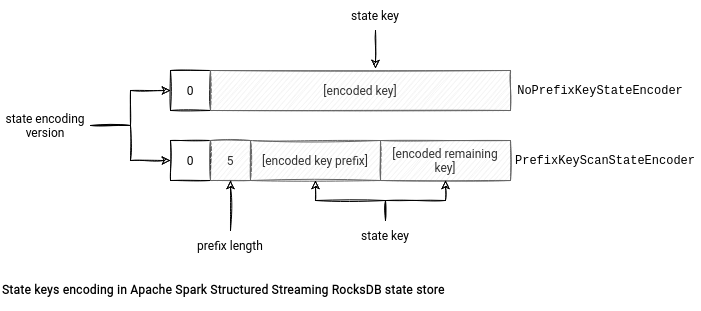
- creates appropriate RocksDBStateEncoder - currently there are 2 encoders called PrefixKeyScanStateEncoder and NoPrefixKeyStateEncoder. Why 2? Because Apache Spark 3.2.0 got another interesting feature called prefix scan that optimizes scanning a specific range of keys (more about that next weeks). The feature is optional and only one of the encoders supports it. Under-the-hood the support or lack of it relies on a different storage format. The NoPrefixKeyStateEncoder stores the key flatten while the PrefixKeyScanStateEncoder splits it into 2 parts, the prefix and the rest. The format also stores the prefix key length but doesn't store the total key length since it's dynamically generated at deserialization as a result of keyBytes.length - 4 - prefixKeyEncodedLen.
- returns a lazily evaluated instance of the RocksDB database; it'll be really created after the first call
And that's all for the init step. But much more things happen later when Apache Spark uses the state store in a stateful operation.
CRUD operations
RocksDB state store shares the same read-write API as the HDFS-backed version. In the beginning, an appropriate store version gets loaded from the load(version: Long) method. The version corresponds to the micro-batch number, and the function starts by comparing the version to load with the current version of the application. If they're different, it means that the execution context probably concerns the reprocessing, and there is no local information. Hence, the state store will recover the database from the checkpoint location with the help of RocksDBFileManager. Because I'll cover this recovery aspect in the next section, let's move directly to the read/write actions.
Naturally, Apache Spark relies on RocksDB API to perform them. In the state store definition you will find the RocksDB classes like:
- ReadOptions - uses all defaults to read data from a RocksDB instance. Surprisingly, Apache Spark uses them not only while returning the state to the caller but also writing them in put and remove methods. Why? To track the number of keys in the given version. So, the put operation increments the counter and the remove decrements it:
def put(key: Array[Byte], value: Array[Byte]): Array[Byte] = { val oldValue = writeBatch.getFromBatchAndDB(db, readOptions, key) writeBatch.put(key, value) if (oldValue == null) { numKeysOnWritingVersion += 1 } oldValue } def remove(key: Array[Byte]): Array[Byte] = { val value = writeBatch.getFromBatchAndDB(db, readOptions, key) if (value != null) { writeBatch.remove(key) numKeysOnWritingVersion -= 1 } value } - WriteOptions - sets the sync flag to true meaning that the writes will be flushed from the OS buffer cache before considering the write operation complete. It slows down the writing process but ensures no data loss in case of the machine failure. Apache Spark uses them in the state store commit operation.
- FlushOptions - enables the waitForFlush to block the flush operation until it terminates. Also used in the state store commit operation.
- WriteBatchWithIndex - configured with the overwriteKey enabled to replace any existing keys in the database. It's the writer interface for RocksDB but since it's searchable, it's also involved in the get operations including the ones mentioned above in the writing context.
- BloomFilter - used as a filter policy to reduce disk reads for the key lookups.
Compared to the default state store, the RocksDB implementation looks similar for the CRUD operations. Except for one difference. To recall, the remove operation of the default state store materializes that fact in the checkpointed delta file. It's not the case of RocksDB, which simply removes the state from the database. The difference is also related to the checkpointed elements presented just below.
Storage
In the following schema you can see the files managed by RocksDB state store:
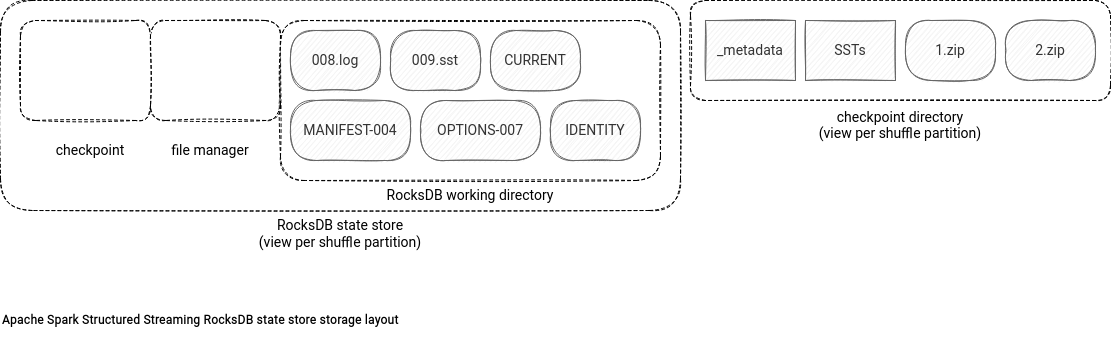
There are 2 "spaces". The leftmost part stores all files used by the live instance of the RocksDB database. The working directory is where the data files of the instance, called SSTables and logs, live. The checkpoint space is the directory created by Apache Spark while committing the micro-batch version (see below). It stores all files that are going to be checkpointed. Finally, the file manager space is the directory reserved to the RocksDBFileManager activity. The manager uses it mostly in the clean-up stage to store the uncompressed content of the checkpointed files.
Regarding the checkpoint location, you'll find there the RocksDB files (logs, SSTs, archived logs directory), some metadata with the state store schema, and zip files storing other files necessary for the restore process, such as RocksDB options or the mapping between the checkpointed files and their local names.
Fault tolerance
The commit function of the state store API runs after processing all input rows for the shuffle partition to materialize the state store for the current micro-batch version. In RocksDB this operation involves the following steps:
- an empty and temporary checkpoint directory creation in the RocksDB space
- writing all the updates of the version to RocksDB database - this step calls the write method of the RocksDB API. But wait a minute, the CRUD part uses put and remove functions of the API. What's then the difference? The state store uses a Write Batch With Index mode where the write operations are serialized into the WriteBatch instead of acting directly on the database. The write call guarantees their atomic write to the database.
- flushing all memory data - the writes go first to an in-memory structure called memtable. When the memtable is full, RocksDB flushes its content to sstfiles stored on disk. Thanks to that, the checkpointing process will take the complete dataset.
- compacting the state store if enabled - the process consists of removing deleted or overwritten key-value bindings to organize the data for query efficiency. It also merges small files with the flushed data into bigger ones.
- stopping all background ongoing operations to avoid files inconsistencies during committing due to the concurrent actions on the same files
- creating a RocksDB checkpoint - it's a native RocksDB capability to take a snapshot of the running instance in a separate directory. If the checkpoint and the database share the same file system - which is the case in Apache Spark - the checkpoint will only create hard links to the database SSTable files.
- the RocksDBFileManager instance takes all checkpoint files and copies them to the checkpoint location. The copy has some tricky points. To start, there are 2 types of files, the not zippable and zippable ones. The former category concerns the archived log and live sst files. The checkpointing process copies them alone to the checkpoint location. This brings another interesting fact. RocksDB may reuse the sst files from the previous micro-batch. When it happens and these files are the same as the ones already checkpointed, the checkpointing won't copy them. Instead, it'll only reference them in the metadata file listing all sst files relevant for the given micro-batch. You can find the content of that file below:
v1 {"sstFiles":[{"localFileName":"000009.sst","dfsSstFileName":"000009-1295c3cd-c504-4c1b-8405-61e15cdd3841.sst","sizeBytes":1080}],"numKeys":2}In addition to these sst and log files, the checkpointing process will take metadata (MANIFEST, CURRENT, OPTIONS), log file, and the aforementioned Spark-managed metadata file, and compress them in a single zip archive. You will find a summary of the process in the schema below: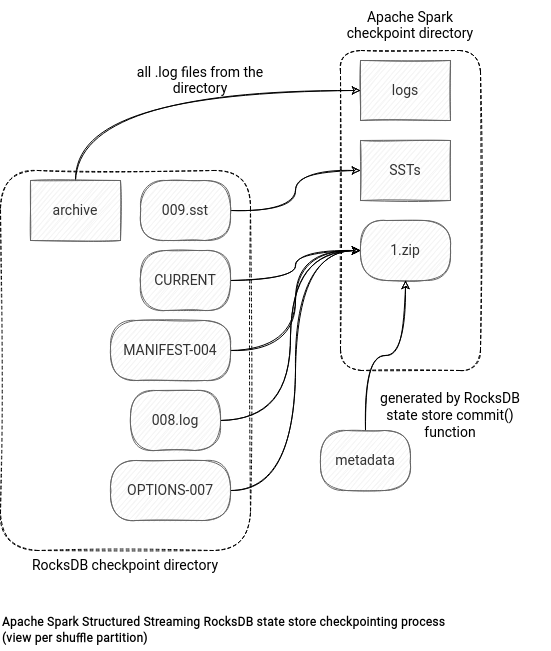
When it comes to the state store recovery in the load method, RocksDB state store delegates this action to the RocksDBFileManager. During the restore, the manager downloads the zipped file and unzips it to the local RocksDB working directory. It later iterates the list of the sstFiles from the metadata and brings them back from the checkpoint location to the RocksDB directory. It's worth noticing that all the copied files are locally stored with the correct names, i.e. the UUID-like name is replaced with the localFileName attribute.
Once this copy operation completes, Apache Spark has all necessary files to restart the previous RocksDB instance. It does that by referencing the working directory in the initialization call: NativeRocksDB.open(dbOptions, workingDir.toString).
RocksDB is an interesting alternative to the default on-heap-based state store implementation, optimized for large state usage. However, understanding it was a bit more challenging since it requires discovering new technology. Thankfully, as an end-user, you may not need to know all these details, but if you do, I hope the blog post can help to take a few shortcuts!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.2.0 - RocksDB state store here:
- Add RocksDB StateStore implementation RocksDB Overview Write Batch With Index Use Checkpoints for Efficient Snapshots
Related blog posts:
Today I covered the first #ApacheSpark 3.2.0 feature. If you want to learn about RocksDB state store backend in #StructuredStreaming, the blog post is just there ? https://t.co/4DtQEbTDp5
— Bartosz Konieczny (@waitingforcode) October 23, 2021