
It's difficult to see all the use cases of a framework. Back in time, when I was a backend engineer, I never succeeded to see all applications of Spring framework. Now, when I'm a data engineer, I feel the same for Apache Spark. Fortunately, the community is there to show me some outstanding features!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Point-in-time join
The first of them is the Point-in-Time join. What does it mean? Of course, it's a join, so imagine 2 datasets. Both have a join key column and a temporal column. The relationship of a join can be 0:n, meaning that each left side element can be matched with 0 or more rows from the right dataset. But thanks to the temporal column, there will always be 0 or only a single matching row on the right side.
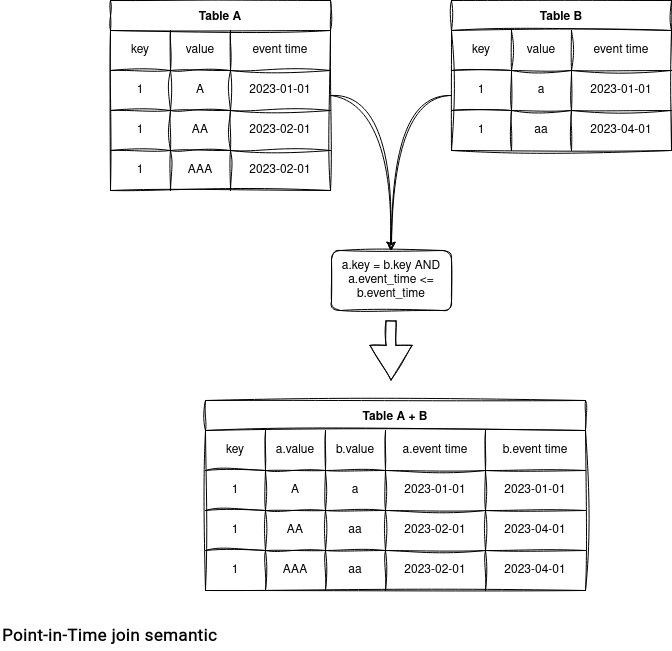
I learned about this specific join type from Jim Dowling. His company,Hopsworks, Open-Sourced a utility library called spark-pit where this specific Point-in-Time join is implemented.
Range join
From the same join category there is also a Range join type. It consists of combining the datasets with a range condition. The condition can be for example a BETWEEN operation, like in the following example:
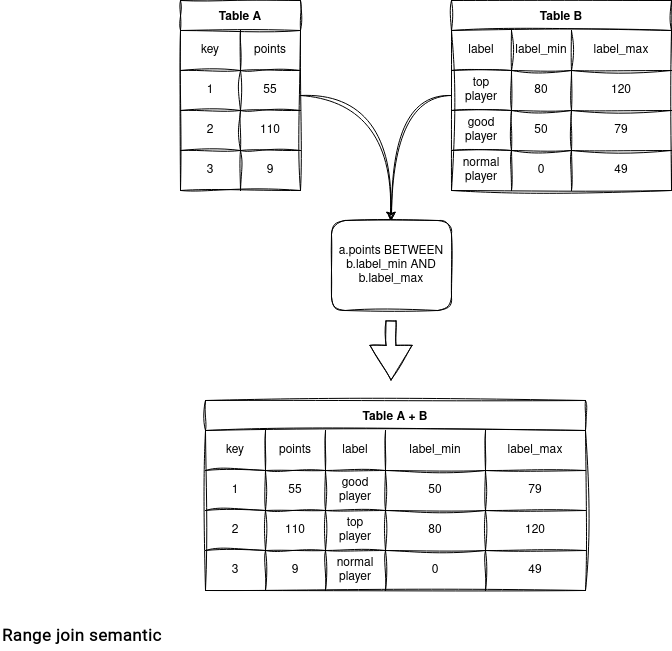
There is an Open Source implementation for that type of join in the utility library called Spark-DataFu. And if you use Databricks, you can even benefit from some runtime optimizations with the Range join optimization.
Multi-dimensional indexes
Apache Iceberg and Delta Lake have already proven that Apache Spark can be much more than a compute layer and hence, it can also integrate with file formats. Qbeast is an index layer on top of Delta Lake. Its specialty? Multi-dimensional indexes! You can create a table and define multiple columns to index.
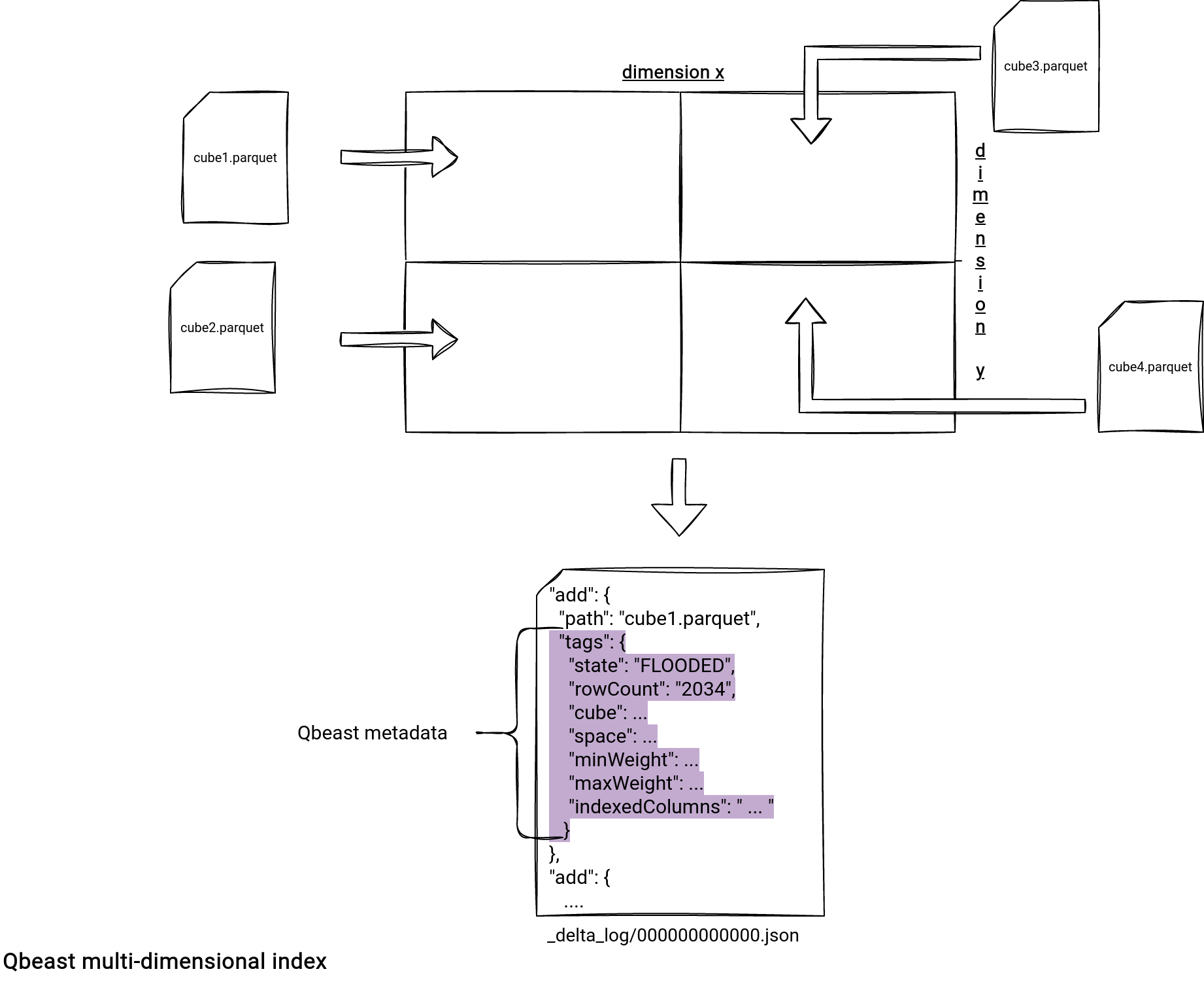
How does it work? The implementation is based on a OTree index that defines non-overlapping spaces in a spatial index which is n-dimensional (n = number of index columns). These non-overlapping spaces are called cubes.
At the code level Qbeast adds a metadata management component responsible for:
- Writing cube files, so to put related records regarding the spatial index together.
- Referencing the cube files in the Delta Lake commit log under the tags attribute.
- Analyzing the index content to find the cubes matching the filter predicates at reading.
Below you can find the visual representation of the Qbeast building blocks:
All of these 3 great features are proof that Apache Spark is a way more than the "T" doing some mapping and filtering in the ETL batch pipelines. I'm sure there are more and going to continue the observation of the landscape to find and share the other ones!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Apache Spark as you don't know it here:
- A Spark Join Operator for Point-in-Time Correct Joins Introducing DataFu-Spark Range join optimization Experience building an index in a Data Lakehouse, with Paola Pardo
Related blog posts:
- Rolling history logs in Spark History UI
- What's new in Apache Spark 3.4.0 - shuffle changes
- What's new in Apache Spark 3.4.0 - Spark Connect
Most of us certainly know broadcast and anti/semi joins or buckets. Besides these interesting native features, #ApacheSpark has other interesting community-based extensions, such as point-in-time and range joins, or multidimensional indexes ? https://t.co/pf47Eogqym
— Bartosz Konieczny (@waitingforcode) February 3, 2023