
Compression has a lot of benefits in the data context. It reduces the size of stored data, so you will save some space and also have less data to transfer across the network in the case of a data processing pipeline. And if you use Bzip2, you can process the compressed data in parallel. In this post, I will try to explain how does it happen.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post is the follow-up post of Apache Spark and data compression. If you are interested in other parallelizable compression formats and their management in Apache Spark, I invite you to read it. Otherwise, let's start to talk about Bzip2. In the first section, I will present the basic organization of a Bzip2-compressed file. In the next part, I will focus on the parallel reading of these files in Apache Spark.
Bzip2 format
To recall, Bzip2 is a block-based compression algorithm generating the compression blocks between 100 and 900 kb. The compressed file has a bzip stream composed of a header, 1 or more compression blocks, and a footer. The following image summarizes this:
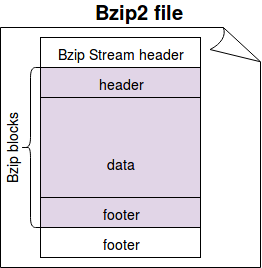
The above image is the result of CBzip2OutputStream class from Hadoop's package. As you can see, every new file starts with a header identifying the file as being compressed with bzip2 algorithm. Later you can find 1 or more Bzip blocks of the size specified before. Each block has a header beginning with the file-format (huffmanised) and the digit indicating the block size (100-900 kb). Next to it, you can retrieve the compressed data and the footer with the CRC of the compressed data. At the end, you can find the final footer with a 48-bit magic number to indicate the end of the last compressed block and a combined checksum (CRC) for all stored blocks.
Different workers can decompress bzip2 files in parallel thanks to the block abstraction to store the compressed data. The blocks are independent - that's not completely true at the reading time which I will show you in the next part - and therefore, parallel reads are more than feasible.
If bzip2 is so good, why it seems less popular than gzip? I don't have the right answer but one of the reasons may be the write and read performance. In the benchmarks, bzip2 is always shown as a slower writer and reader than gzip. Another possible reason is the support of bzip2, or rather its lack. Apache Spark supports it quite well but other libraries and data stores do not. For instance, in BigQuery you can only export the data in gzip format.
But despite that popularity problem, it's worth discovering how a distributed framework is able to read compressed files in parallel. I will give you some details in the next section.
Reading Bzip2 in Apache Spark
I will focus here mainly on the processing of text-based files like multi-line JSONs and so forth. The classes used for other data sources may then be different. In Apache Spark the line-separated records are read by the instance of org.apache.spark.sql.execution.datasources.RecordReaderIterator. Under-the-hood it uses an implementation of RecordReader coming from Hadoop package.
RecordReader has few methods, mainly to access the currently iterated key or value, or simply to check whether there are more rows to process. One of RecordReader's implementation is org.apache.hadoop.mapreduce.lib.input.LineRecordReader. Depending on the input file compression, it either uses a reader for the uncompressed or for the compressed files. We will be interested on the latter one which is represented as an instance of CompressedSplitLineReader class.
CompressedSplitLineReader exposes readLine(Text str, int maxLineLength, int maxBytesToConsume) method. As the name suggests, it reads one line of the input compressed file. However, it's not as simple as it looks because the compressed blocks won't always be only the entire lines. Therefore, the reader must figure out what to do in the following use cases:
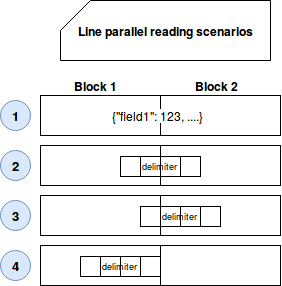
As you can see, 4 different situations may happen. The block can have only a part of the record or only the part of the delimiter. To not duplicate the reads and not lose the data, the consumer of the block 1 can continue the reading and start to process the next block's part until crossing the next delimiter. In this scenario, the initial consumer of the next block will discard its first part not beginning with a complete delimiter. This behavior is exposed by the needAdditionalRecordAfterSplit() method used during the iteration over the lines.
The final part that is worth mentioning concerns blocks reading logic. For this time, it's good to know that the compressed data is read with the help of Bzip2CompressionInputStream created from BZip2Codec#createInputStream(java.io.InputStream, org.apache.hadoop.io.compress.Decompressor, long, long, org.apache.hadoop.io.compress.SplittableCompressionCodec.READ_MODE) method. I will dedicated a different post to parallel input streams.
Thanks to its special block-based structure, Bzip2 files can be read in parallel by different workers. The construction of them ensures that the readers will be able to seek to some specific position and consume the compressed bytes. However, the integration working with the line-based sources shows that it can be sometimes tricky - especially when the block has only a part of the record or the delimiter. Luckily, these scenarios are managed with the special policy telling either to continue or to ignore the read block.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Bzip2 compression in Apache Spark here:
Related blog posts:
- Rolling history logs in Spark History UI
- What's new in Apache Spark 3.4.0 - shuffle changes
- What's new in Apache Spark 3.4.0 - Spark Connect
A small focus on the bzip2 files processing in #ApacheSpark https://t.co/ZHhYsFllRX
— Bartosz Konieczny (@waitingforcode) March 22, 2019