
During my exploration of Apache Spark configuration options, I found an entry called spark.scheduler.mode. After looking for its possible values, I ended up with a pretty intriguing concept called FAIR scheduling that I will detail in this post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The post has 3 sections. The first one introduces the default scheduler mode in Apache Spark called FIFO. The second section focuses on the FAIR scheduler whereas the last part compares both of them through 2 simple test cases.
FIFO scheduling in Apache Spark
In Apache Spark, a job is the unit of work represented by the transformation(s) ending by an action. By default, the framework allocates the resources in FIFO manner. This means that the first defined job will get the priority for all available resources. If this first job doesn't need all resources, that's fine because other jobs can use them too. But if it's not the case, the remaining jobs must wait until the first job frees them. It can be problematic especially when the first job is a long-running one and the remaining execute much faster. The following image shows the problem:
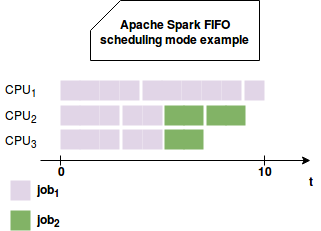
As you can see, despite the fact of submitting the jobs from 2 different threads, the first triggered job starts and reserves all resources. To mitigate that issue, Apache Spark proposes a scheduling mode called FAIR.
FAIR scheduling in Apache Spark
FAIR scheduling mode works in round-robin manner, like in the following schema:
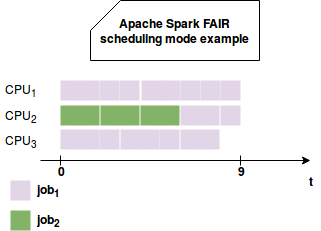
As you can see, the engine schedules tasks of different jobs. That's why the job number 2 doesn't need to wait the long job number 1 to terminate and it can start as soon as possible. Thus, the final goal of the FAIR scheduling mode is to share the resources between different jobs and thanks to that, not penalize the execution time of the shorter ones.
FAIR scheduling method brings also the concept of pools. The pool is a concept used to group different jobs inside the same logical unit. Each pool can have different properties, like weight which is a kind of importance notion, minShare to define the minimum reserved capacity and schedulingMode to say whether the jobs within given pool are scheduled in FIFO or FAIR manner.
Hence, pools are a great way to separate the resources between different clients. If one of the executed jobs is more important than the others, you can increase its weight and minimum capacity in order to guarantee its quick termination.
Both concepts, FAIR mode and pools, are configurable. The scheduling method is set in spark.scheduler.mode option whereas the pools are defined with sparkContext.setLocalProperty("spark.scheduler.pool", poolName) method inside the thread invoking given job.
FIFO and FAIR scheduling comparison
To see FAIR scheduling mode in action we have different choices. In the local mode, the easiest one though is to see the order of scheduled and executed tasks in the logs. The 2 following tests prove that in FIFO mode, the jobs are scheduled one after another whereas in FAIR mode, the tasks of different jobs are mixed:
"FIFO scheduling mode" should "run the tasks of one job in sequential manner" in {
val logAppender = InMemoryLogAppender.createLogAppender(Seq("Running task"),
(event) => LogMessage(s"${event.getTimeStamp}; ${event.getMessage}", event.getLoggerName))
val conf = new SparkConf().setAppName("Spark FIFO scheduling modes").setMaster("local[2]")
conf.set("spark.scheduler.mode", "FIFO")
val sparkContext = new SparkContext(conf)
val latch = new CountDownLatch(2)
new Thread(new Runnable() {
override def run(): Unit = {
val input1 = sparkContext.parallelize(1 to 1000000, 5)
val evenNumbers = input1.filter(nr => {
val isEven = nr % 2 == 0
if (nr == 180000) {
Thread.sleep(3000L)
}
isEven
})
evenNumbers.count()
latch.countDown()
}
}).start()
Thread.sleep(100L)
new Thread(new Runnable() {
override def run(): Unit = {
val input2 = sparkContext.parallelize(1000000 to 2000000, 5)
val oddNumbers = input2.filter(nr => {
val isOdd = nr % 1000000 != 0
if (nr == 1050000) {
Thread.sleep(3000L)
}
isOdd
})
oddNumbers.count()
latch.countDown()
}
}).start()
latch.await(5, TimeUnit.MINUTES)
sparkContext.stop()
val timeOrderedStages = getSortedStages(logAppender.getMessagesText())
val notSeqentualStages = timeOrderedStages.sliding(3).find(stages => {
val allDifferentStages = stages.sliding(2).forall {
case Seq(stage1, stage2) => stage1 != stage2
}
allDifferentStages
})
notSeqentualStages shouldBe empty
// It's empty because the tasks stages are always submitted in sequential order. Locally, the result I had
// the most often was:
// ListBuffer(0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0, 1.0)
// (but of course it will depend on the threads starting order)
print(s"${timeOrderedStages}")
}
"FAIR scheduling mode" should "run stages from 2 jobs in round-robin manner" in {
val logAppender = InMemoryLogAppender.createLogAppender(Seq("Running task"),
(event) => LogMessage(s"${event.getTimeStamp}; ${event.getMessage}", event.getLoggerName))
val conf = new SparkConf().setAppName("Spark FAIR scheduling modes").setMaster("local[2]")
conf.set("spark.scheduler.mode", "FAIR")
val sparkContext = new SparkContext(conf)
val latch = new CountDownLatch(2)
new Thread(new Runnable() {
override def run(): Unit = {
sparkContext.setLocalProperty("spark.scheduler.pool", "pool1")
val input1 = sparkContext.parallelize(1 to 1000000, 5)
val evenNumbers = input1.filter(nr => {
val isEven = nr % 2 == 0
if (nr == 180000) {
Thread.sleep(3000L)
}
isEven
})
evenNumbers.count()
latch.countDown()
}
}).start()
new Thread(new Runnable() {
override def run(): Unit = {
sparkContext.setLocalProperty("spark.scheduler.pool", "pool12")
val input2 = sparkContext.parallelize(1000000 to 2000000, 5)
val oddNumbers = input2.filter(nr => {
val isOdd = nr % 1000000 != 0
if (nr == 1050000) {
Thread.sleep(3000L)
}
isOdd
})
oddNumbers.count()
latch.countDown()
}
}).start()
latch.await(5, TimeUnit.MINUTES)
sparkContext.stop()
val timeOrderedStages = getSortedStages(logAppender.getMessagesText())
val notSeqentualStages = timeOrderedStages.sliding(3).find(stages => {
val allDifferentStages = stages.sliding(2).forall {
case Seq(stage1, stage2) => stage1 != stage2
}
allDifferentStages
})
notSeqentualStages shouldBe defined
// It will depend on the thread starting time but locally the most often I had the
// Some(ListBuffer("0.0", "1.0", "0.0")) result
println(s"${notSeqentualStages}")
}
private def getSortedStages(loggedMessages: Seq[String]): Seq[String] = {
loggedMessages.map(timestampWithMessage => timestampWithMessage.split(";"))
.sortBy(timestampAndMessage => timestampAndMessage(0))
.map(timestampAndMessage => {
val stageWithTID = timestampAndMessage(1).takeRight(12).trim
val stageId = stageWithTID.split(" ")(0)
stageId
})
}
FAIR scheduler mode is a good way to optimize the execution time of multiple jobs inside one Apache Spark program. Unlike FIFO mode, it shares the resources between tasks and therefore, do not penalize short jobs by the resources lock caused by the long-running jobs.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about FAIR jobs scheduling in Apache Spark here:
- Scheduling Within an Application Spark Schedule: FIFO or FAIR? Scheduling Mode — spark.scheduler.mode Spark Property
Related blog posts:
- Rolling history logs in Spark History UI
- What's new in Apache Spark 3.4.0 - shuffle changes
- What's new in Apache Spark 3.4.0 - Spark Connect
Some weeks ago during my usual #ApacheSpark configuration analysis I discovered spark.scheduler.mode that can be FIFO (default) or FAIR. I've just published some notes about this property https://t.co/lg8kpFvX09
Some weeks ago during my usual #ApacheSpark configuration analysis I discovered spark.scheduler.mode that can be FIFO (default) or FAIR. I've just published some notes about this property https://t.co/lg8kpFvX09
— Bartosz Konieczny (@waitingforcode) April 4, 2019