
Spark has a lot of interesting features and one of them is the speculative execution of tasks.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post describes speculative tasks in Spark. The first part explains how tasks are chosen to speculative execution. The second part shows how they are integrated to job execution. The last part simulates the use of speculation task.
Speculative tasks control
Shortly explained, speculative tasks (aka task strugglers) are launched for the tasks that are running slower than other tasks in a given stage. We can also tell that these slow tasks are lagging behind the other tasks.
Spark determines lagging tasks thanks to configuration entries prefixed by spark.speculation. More concretely it means the following properties:
- spark.speculation: when turned to true it enables speculative task execution. It's deactivated by default.
- spark.speculation.interval: in ms, it defines how often Spark will check for tasks to speculate.
- spark.speculation.multiplier: task slowness is checked against the median time of execution of all launched tasks. This entry defines how many times slower a task must be to be considered for speculation. The default value is 1.5. It means that tasks running 1.5 times slower than the median will be taken into account for speculation.
- spark.speculation.quantile: it specifies how many tasks must finish before enabling the speculation for given stage. It's expressed by the fraction and by default the value is 0.75 (75%).
How all of these properties are used internally by Spark ? When a job is not executed locally and spark.speculation is set to true, org.apache.spark.scheduler.TaskSchedulerImpl schedules the execution of the following method at fixed rate (= to spark.speculation.interval):
def checkSpeculatableTasks() {
var shouldRevive = false
synchronized {
shouldRevive = rootPool.checkSpeculatableTasks(MIN_TIME_TO_SPECULATION)
}
if (shouldRevive) {
backend.reviveOffers()
}
}
The execution is redirected to org.apache.spark.scheduler.TaskSetManager#checkSpeculatableTasks(minTimeToSpeculation: Int) that uses 2 remaining properties (spark.speculation.multiplier and spark.speculation.quantile) to:
- control the speculation execution:
val minFinishedForSpeculation = (SPECULATION_QUANTILE * numTasks).floor.toInt logDebug("Checking for speculative tasks: minFinished = " + minFinishedForSpeculation) if (tasksSuccessful >= minFinishedForSpeculation && tasksSuccessful > 0) { // speculation starts here - and select slow tasks:
val durations = taskInfos.values.filter(_.successful).map(_.duration).toArray Arrays.sort(durations) val medianDuration = durations(min((0.5 * tasksSuccessful).round.toInt, durations.length - 1)) val threshold = max(SPECULATION_MULTIPLIER * medianDuration, minTimeToSpeculation) for ((tid, info) <- taskInfos) { val index = info.index if (!successful(index) && copiesRunning(index) == 1 && info.timeRunning(time) > threshold && !speculatableTasks.contains(index)) { // [BK]: speculatableTask is an instance field : // val speculatableTasks = new HashSet[Int] speculatableTasks += index foundTasks = true } }
Speculative task execution
Speculative tasks are scheduled as normal tasks, through org.apache.spark.scheduler.TaskSetManager#dequeueTask, called by resourceOffer(execId: String, host: String, maxLocality: TaskLocality.TaskLocality) of the same class. An important point presented here is that speculated task can't be executed on particular node more than once.
When the speculative task finishes before the original one, the second task is killed and in Spark UI we can see its as annotated with killed intentionally. The opposite can also happen, i.e. the original task can finish before the speculative one. The behavior is the same - the speculative task is annotated with "killed intentionally". This second situation (the first is presented in next section) can be observed in logs with the following entries:
# Task 3.1 is the speculative one INFO TaskSetManager: Task 3.1 in stage 0.0 (TID 5) failed, but another instance of the task has already succeeded, so not re-queuing the task to be re-executed. INFO TaskSetManager: Killing attempt 1 for task 3.1 in stage 0.0 (TID 5) on spark-slave-3 as the attempt 0 succeeded on spark-slave-1 INFO TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 120091 ms on spark-slave-1 (executor 2) (5/5) WARN TaskSetManager: Lost task 3.1 in stage 0.0 (TID 5, spark-slave-3, executor 1): TaskKilled (killed intentionally) INFO Executor: Executor is trying to kill task 3.1 in stage 0.0 (TID 5) INFO Executor: Executor interrupted and killed task 3.1 in stage 0.0 (TID 5)
Speculative task example
After some theoretical information, let's pass to the practical part and try to make Spark to launch speculative task for a slow processing. The tested code is pretty simple and it looks like in the following snippet:
object Main {
@transient lazy val Logger = LoggerFactory.getLogger(this.getClass)
private val SlowHostName = "spark-slave-1"
def main(args: Array[String]): Unit = {
// Activate speculative task
val conf = new SparkConf().setAppName("Spark speculative task")
.set("spark.speculation", "true")
.set("spark.speculation.interval", "1000")
.set("spark.speculation.multiplier", "1.5")
.set("spark.speculation.quantile", "0.10") // Activates speculation after 10% of finished tasks
val sparkContext = new SparkContext(conf)
Logger.info("Starting processing")
sparkContext.parallelize(0 to 50, 5)
.foreach(item => {
val executionHost = InetAddress.getLocalHost.getHostName
if (executionHost == SlowHostName) {
Thread.sleep(120000)
}
Logger.info(s"Read number ${item} on host ${executionHost}")
})
Logger.info("Terminating processing")
}
}
Once compiled, the JAR is moved to master server and submitted through spark-submit tool:
spark-submit --deploy-mode cluster --master yarn --jars ./shared/spark-speculative-task_2.11-1.0.jar --num-executors 3 ./shared/spark-speculative-task_2.11-1.0.jar --class com.waitingforcode.Main
After some time we can observe in the logs the creation of speculative tasks:
17/06/20 19:17:30 INFO scheduler.TaskSetManager: Marking task 1 in stage 0.0 (on spark-slave-1) as speculatable because it ran more than 1773 ms 17/06/20 19:17:30 INFO scheduler.TaskSetManager: Starting task 1.1 in stage 0.0 (TID 5, spark-slave-2, executor 3, partition 1, PROCESS_LOCAL, 5970 bytes) 17/06/20 19:17:30 INFO scheduler.TaskSetManager: Killing attempt 0 for task 1.0 in stage 0.0 (TID 1) on spark-slave-1 as the attempt 1 succeeded on spark-slave-2
In Spark UI the result of executed code looks like in the following picture:
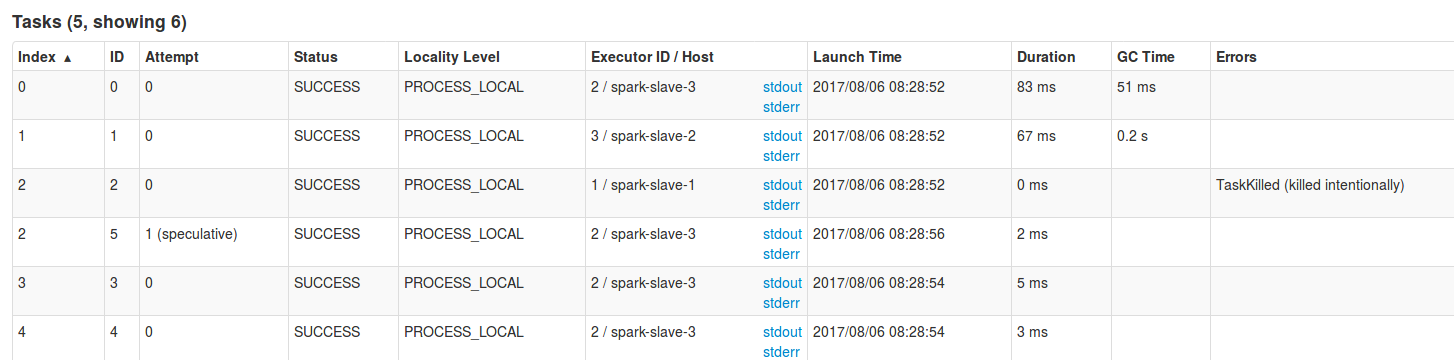
As we saw through this post, speculative tasks are nothing else that "normal" tasks launched on different executors only once. They can be useful in some cases when particular executor performs worse than the others. However, it doesn't come without any cost and should be configured carefully to not overload the workers. For instance, too small threshold of "slowness" can produce a lot of extra work that can uselessly charge worker nodes that, especially in the case of jobs with a lot of tasks dealing with a lot of data, can slow down whole processing because of scheduling overhead.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩