
Broadcast variables send object to executors only once and can be easily used to reduce network transfer and thus are precious in terms of distributed computing.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The first part of this post describes some points about broadcast variables. It makes an insight of their purposes. The second part shows how these variables are sent through the network. The last part, with usual learning tests, gives some use cases of broadcast variables.
Broadcast variables explained
Broadcast variables are read-only data sent to executors only once. They are a good solution to store some immutable reference data, for instance small dictionary shared among all executors. The data is sent lazily, i.e. only when it's needed by executors. Thus, if a broadcast variable is sent and it's never used, it won't be physically transfered.
Among data sent as broadcast variables we can distinguish explicitly defined broadcast objects and Spark-related objects. The first ones are easy to understand. They represent all objects wrapped by SparkContext's broadcast method. The 2nd category of the broadcasted objects represents the ones used internally by Spark. We can find there:
- binary representation of task - sent by DAGScheduler, it represents either the function to execute or the shuffle operation. This use case can be found in org.apache.spark.scheduler.DAGScheduler#submitMissingTasks(stage: Stage, jobId: Int) method. It explains why the information about broadcast is present in the logs even if we don't explicitly sent any broadcast variable, as in the following snippet:
INFO Block broadcast_1_piece0 stored as bytes in memory (estimated size 870.0 B, free 1412.7 MB) (org.apache.spark.storage.memory.MemoryStore:54) INFO Added broadcast_1_piece0 in memory on 192.168.0.12:44906 (size: 870.0 B, free: 1412.7 MB) (org.apache.spark.storage.BlockManagerInfo:54) DEBUG Updated info of block broadcast_1_piece0 (org.apache.spark.storage.BlockManagerMaster:58) DEBUG Told master about block broadcast_1_piece0 (org.apache.spark.storage.BlockManager:58) DEBUG Put block broadcast_1_piece0 locally took 4 ms (org.apache.spark.storage.BlockManager:58) TRACE Task -1024 releasing lock for broadcast_1_piece0 (org.apache.spark.storage.BlockInfoManager:62) DEBUG Putting block broadcast_1_piece0 without replication took 5 ms (org.apache.spark.storage.BlockManager:58) INFO Created broadcast 1 from broadcast at DAGScheduler.scala:996 (org.apache.spark.SparkContext:54) INFO Submitting 1 missing tasks from ResultStage 1 (ParallelCollectionRDD[1] at makeRDD at BroadcastTest.scala:77) (org.apache.spark.scheduler.DAGScheduler:54) INFO Running task 0.0 in stage 1.0 (TID 1) (org.apache.spark.executor.Executor:54) DEBUG Task 1's epoch is 0 (org.apache.spark.executor.Executor:58) DEBUG Getting local block broadcast_1 (org.apache.spark.storage.BlockManager:58) TRACE Task 1 trying to acquire read lock for broadcast_1 (org.apache.spark.storage.BlockInfoManager:62) TRACE Task 1 acquired read lock for broadcast_1 (org.apache.spark.storage.BlockInfoManager:62) DEBUG Level for block broadcast_1 is StorageLevel(disk, memory, deserialized, 1 replicas) (org.apache.spark.storage.BlockManager:58) TRACE Task 1 releasing lock for broadcast_1 (org.apache.spark.storage.BlockInfoManager:62) INFO Finished task 0.0 in stage 1.0 (TID 1). 1050 bytes result sent to driver (org.apache.spark.executor.Executor:54)
- serializable Hadoop configuration - this feature is used specifically in Spark SQL. For many formats (JSON, CSV, text), a special configuration object is sent as broadcast variable to org.apache.spark.sql.execution.datasources.HadoopFileLinesReader.
BitTorrent protocol
The data stored in broadcast variables is sent through BitTorrent-like protocol. It's a Peer to Peer protocol, well known by the users of illegal programs used several years ago to download music, movies and other copy righted files. And the similarity is justified. In the case of these programs, one user publishes a file that can be downloaded by other users (Users#2). Once downloaded, yet another users (Users#3) are able to download the file but not only from the original publisher but also from the ones who downloaded it initially (Users#2). The following schema shows this example:
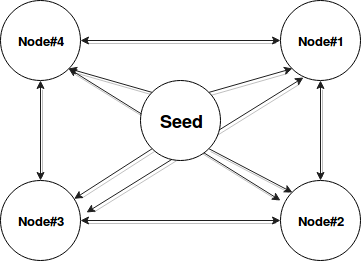
In Spark, torrent protocol works exactly in the same manner. Every broadcasted object is first serialized. After it's divided on smaller chunks by the driver. Chunks size corresponds to the spark.broadcast.blockSize configuration property and by default is of 4MB. The object responsible for this operation is org.apache.spark.storage.BlockManagerMaster. In addition to the information about blocks of broadcast object, this manager also communicates with exposed HTTP endpoints to discover which executors store given block or to indicate block removal. It's visible in the logs with following entries:
TRACE Task -1024 trying to remove block broadcast_14 (org.apache.spark.storage.BlockInfoManager:62) DEBUG Done removing broadcast 14, response is 0 (org.apache.spark.storage.BlockManagerSlaveEndpoint:58)
When an executor needs the broadcasted object, it will first check if it already has the object's chunks locally. If it's the case, it will assembly them and deserialize the object. But when it's not the case, the executor will first fetch the chunks from the driver and/or other executors. Once all chunks are retrieved, they are saved locally and used as if they were there from the beginning. The order of fetching blocks is not guaranteed, i.e. they can be retrieved in order (ex: 1, 2, 3, 4 for 4 blocks) but also in misorder (4, 2, 1, 3). After fetching, they're ordered internally. The org.apache.spark.broadcast.TorrentBroadcast#readBlocks() method shows that:
val blocks = new Array[ChunkedByteBuffer](numBlocks)
// shuffle "Returns a new collection of the same type
// in a randomly chosen order"
for (pid <- Random.shuffle(Seq.range(0, numBlocks))) {
// some code ommitted for brevity
bm.getLocalBytes(pieceId) match {
case Some(block) =>
blocks(pid) = block
// ...
case None =>
bm.getRemoteBytes(pieceId) match {
case Some(b) =>
// ...
blocks(pid) = b
}
}
}
blocks
Broadcast variable example
The following tests show simple use case of broadcast variable and some important specificity - without implemented equality, at every stage the broadcasted object will always be different:
val dataQueue: mutable.Queue[RDD[Int]] = new mutable.Queue[RDD[Int]]()
"dictionary map" should "be broadcasted to executors" in {
for (i <- 1 to 10) {
dataQueue += streamingContext.sparkContext.makeRDD(Seq(i), 1)
}
val seenInstancesAccumulator = streamingContext.sparkContext.collectionAccumulator[Int]("seen instances")
val queueStream = streamingContext.queueStream(dataQueue, true)
val dictionary = Map("A" -> 1, "B" -> 2, "C" -> 3, "D" -> 4)
val broadcastedDictionary = streamingContext.sparkContext.broadcast(dictionary)
queueStream.foreachRDD((rdd, time) => {
val dictionaryFromBroadcast = broadcastedDictionary.value
seenInstancesAccumulator.add(dictionaryFromBroadcast.hashCode)
rdd.foreachPartition(data => {
seenInstancesAccumulator.add(dictionaryFromBroadcast.hashCode)
})
})
streamingContext.start()
//streamingContext.awaitTermination()
streamingContext.awaitTerminationOrTimeout(5000)
val seenClassesHashes = seenInstancesAccumulator.value.stream().collect(Collectors.toSet())
seenClassesHashes.size() shouldEqual(1)
}
"class instance" should "be broadcaster but different instances should be found in different actions" in {
for (i <- 1 to 10) {
dataQueue += streamingContext.sparkContext.makeRDD(Seq(i), 1)
}
val seenInstancesAccumulator = streamingContext.sparkContext.collectionAccumulator[Int]("seen instances")
val queueStream = streamingContext.queueStream(dataQueue, true)
val notEqualityObject = new NoEqualityImplementedObject(3)
val broadcatedObjectWithoutEquality = streamingContext.sparkContext.broadcast(notEqualityObject)
queueStream.foreachRDD((rdd, time) => {
val objectWithoutEquality = broadcatedObjectWithoutEquality.value
seenInstancesAccumulator.add(objectWithoutEquality.hashCode)
rdd.foreachPartition(data => {
seenInstancesAccumulator.add(objectWithoutEquality.hashCode)
})
})
streamingContext.start()
streamingContext.awaitTerminationOrTimeout(5000)
val seenClassesHashes = seenInstancesAccumulator.value.stream().collect(Collectors.toSet())
seenClassesHashes.size() should be > 1
}
class NoEqualityImplementedObject(val someIdentifier: Int) extends Serializable {}
To understand by the object broadcasted in the second test is never the same, you can have a read of the post about Spark's Singleton to be or not to be dilemma.
Through this post we've discovered some facts about broadcast variables. As shown in the first part, they're omnipresent read-only objects in Spark programs. They move the objects shared among executors in chunks that are later fetched and assembled by executors. The communication is guaranteed by BitTorrent-like protocol. The last part illustrated broadcast variables use through 2 simple learning tests.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Zoom at broadcast variables here:
Related blog posts:
- Rolling history logs in Spark History UI
- What's new in Apache Spark 3.4.0 - shuffle changes
- What's new in Apache Spark 3.4.0 - Spark Connect