
Some time ago I've started the series of posts about immutability in data-oriented applications. One of approaches helping to deal with it was based on version flags. But fortunately it's not the only solution - especially for the ones who don't like to mix valid and invalid data in a single place.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post talks about another solution helping to deal with data immutability. It' called aliasing and takes Elasticsearch as example. The first section explains the general idea of the approach. The second part talks shortly about alias in Elasticsearch. The final section recaps all characteristics in a list of advantages and drawback points.
Aliasing to serve immutability
David Wheeler said in its famous aphorism that "all problems in computer science can be solved by another level of indirection". It's true for a lot of cases and our immutability solution based on aliases belongs to them. In a nutshell, an alias is an abstract concept of indirection pointing to something else. A good example of its implementation is web apps router mechanism that matches URL paths to the methods responsible for rendering the content to the user. It's especially useful for instance in canary deployment testing of new rendered page. With router mechanism we can simply change the destination script for given path and observe the changes, rollbacking in case of errors to previous version.
The analogy with webapp router helps to understand the aliases role in data-oriented applications. There are no a lot of differences. We also have a layer of indirection (URL mapping rules) telling where given dataset can be really found. Thus, we retrieve the concept of key (URL path) and value (render script) where the former one means the value that can be read by a client (app, person, ...) and the latter represents physical place where corresponding data is stored. The following schema summarizes the idea for the case of a S3 bucket:
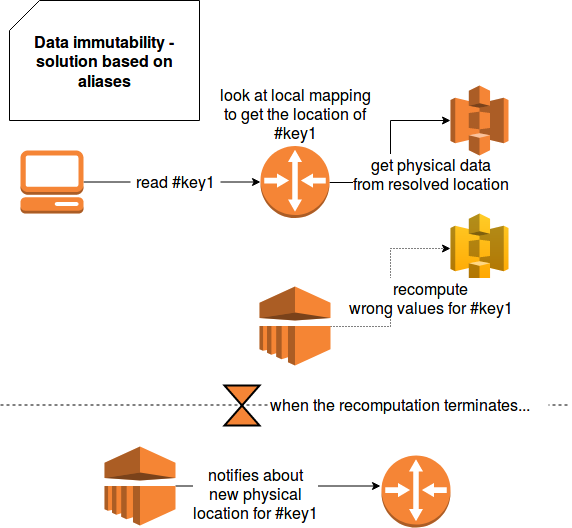
But after all, why we should use an extra layer on indirection to access our data ? Let's imagine the case we're generating the analytics for a service having 500 millions active users per day. In the case of any generation error (e.g. business rule bug, data not complete and so forth) we can simply fix the problem, regenerate data to new physical place and at the end switch physical location in the router part. We don't need here to modify all client apps or even worse, to notify all human users to change their location for the data.
Elasticsearch aliases
One of data storage engines using alias mechanism is Elasticsearch. As in the example mentioned previously, Elaticsearch alias is an intermediary layer between index and user. It has 3 main advantages:
- transparent switch in the case of index recreation
- the ability to group multiple indexes and query them in a single pass, e.g. daily-based indexes can be aggregated together by bigger granularity (week, month, ...)
- filtered aliases are a way to create views. They take a group of indexes and create different views for them. For instance, for the case of e-commerce orders, one of such views can represent most valuable purchases (e.g. more than $1000), while the other one less valuable purchases. With that we can simply plug our client application to one of them, depending on the action context
This mechanism of aliases was more exactly presented in the post about aliases in Elasticsearch.
Advantages and drawbacks
Aliases appear as a great solution for data-oriented applications. They enhance data immutability by making the switch between valid and invalid values pretty easily. After all, it's only the change in one single place called in here a router. Moreover, it's pretty easy to automatize all processes. The data regeneration is summarized in 3 simple steps: fix error (probably human intervention), launch data regeneration and change the mapping in the router.
However the approach still has some drawbacks that mostly are common with other data immutability strategies. One of them is complicated way to deal with partially valid value. Let's imagine that our dataset is partitioned by day and only 1/4 of values for 18:00-24:00 are invalid. To handle the case we need to regenerate whole day since otherwise the router won't be able to simply detect which ones are valid and which one are not. To solve that we should add it an extra logic handling user queries and executing them on the parts of only correct datasets.
Another problem with this solution is temporal data invalidity. Unless we remove the alias pointing to invalid values, we have no other choice than dealing with incorrect results during some time (time of recompute). This situation is sometimes acceptable (e.g. internal system where users are aware of incorrectness or a system that sends the data to external systems once a day) but sometimes is not (e.g. public system working with money). At worse we can always switch the alias to an empty storage but it depends if not having a data is better than having it wrong.
Moreover, aliasing is not adapted to the systems storing data unpartitioned. This solution is also more difficult to implement in on-premise architectures, especially if TBs of data must be recomputed and storage place is very limited. Also the idea of using a router is a little bit risky because it's the central piece of the architecture and, at the same time, the single point of failure.
Data immutability is a pretty interesting concept to avoid removal of big volumes of data. And it can be solved with different approaches, as the one using aliases presented in the post. The idea is to use an intermediary layer between client and data, called here a router, to read queried values. Such mechanism is implemented in Elasticsearch and it helps to switch the execution of user queries smoothly. However this solution has also some drawbacks, such as complexity with partially valid dataset (regenerate all or complexify router logic?) and temporary invalid data. Obviously, it can't be used in all contexts (private vs public) and its implementation may depend on that.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Big Data immutability approaches - aliasing here:
Related blog posts:
The first of the today posts is about data immutability in #BigData . It presents one of possible solutions to do it - aliasing https://t.co/RyXII6Aiho
— bardev (@waitingforcode) September 2, 2018