
The immutability is a precious property of systems dealing with a lot of data. It's especially true when something goes wrong and we must recover quickly. Since the data is immutable, the cleaning step is not executed and with some additional computation power, the data can be regenerated efficiently.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post presents the utility of immutable data in the case of time-series database backed by a key-value data store. The first section shows the context of this imaginary system. The second one provides two possible solutions to show how such data can be stored without the need of cleaning step in the case of errors.
Problem context
For the purpose of our example let's imagine a system generating time-series data stored in a key-value storage. The key is composed of a datetime timestamp truncated to the hours and the id of the user that can query the results. For instance, the user 1 will be able to query the rows corresponding to the keys like 20180101_10_1, 20180101_11_1 but no 20180101_10_2. The queries are executed by a web service and returned to the end-user's interface. The whole logic is summarized in the following schema (technology-agnostic):
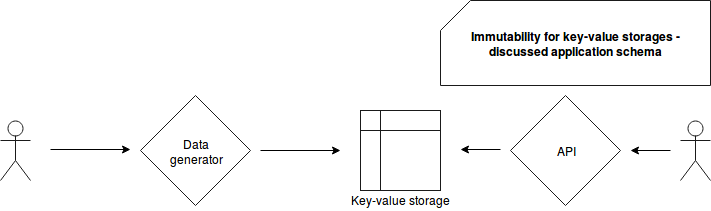
Now let's suppose that somehow a buggy code was pushed to the production branch, deployed and executed during the night when nobody and nothing detected the bug. Next day is coming and somebody finally detects the problem by manually analyzing some entries. To fix the problem, the data from the last 24 hours must be regenerated. The current procedure indicates to drop old data first and launch the regeneration after. Unfortunately, the removal step takes a lot of time and these inconsistencies can't persist during such that time.
After a short brainstorming, the team decides to transform the mutable data to immutable and adapt the reader's code to deal with it. Two possible solutions are possible: versioning and data source overriding. The idea of "do nothing", so well suited for key-value storage (after all, the new data will override the old data for each key) is not accepted. The regeneration can occur either because some bug was introduced to the code or because some data is missing. For this second case the business rules can more or less modify the final output and, for instance, generate different keys with the missing data integrated to the system. It would lead to a half of valid and another half of invalid entries.
Solution#1: versioning
The team unanimously decides to start with the solution using the data versioning. The idea assigns a version for each data generation round. This version number is later appended to the key of the data storage. For instance, the quoted key 20180101_10_1 would look now like 20180101_10_1_v1 where v1 indicates the generation version.
As you can deduce, the API reader must be aware of the most recent versions for the given data ranges. This can be resumed to a "routing" table similar to:
| Range start | Range end | Version |
|---|---|---|
| 2018-01-01 00:00 | 2018-01-10 23:00 | v1 |
| 2018-01-11 00:00 | - | v2 |
According to a table like that, the reader knows the versions to use for each of data ranges. The code dealing with this schema could look like in the following snippet (simplified):
class VersioningDataStoreTest extends FlatSpec with Matchers {
"the data" should "be added for new version" in {
val oldVersion = "v1"
val currentVersion = "v2"
// Some config, let's suppose we need to close v1 because of a bug and open a new version
Configuration.putVersion(1L, 10L, oldVersion)
Configuration.putVersion(11L, Long.MaxValue, currentVersion)
// Add some data for both versions
DataGenerator.generateStats(oldVersion, ("11L_user1", "0"), ("12L_user1", "0"),
("11L_user2", "0"), ("11L_user3", "0"))
DataGenerator.generateStats(currentVersion, ("11L_user1", "100"), ("12L_user1", "110"),
("11L_user2", "200"), ("11L_user3", "300"))
// Now read the data for the day of 11L and user1
val userStatsFor11L = ApiReader.readUserStats("11L_user1", 11L)
userStatsFor11L should equal("100")
}
}
object Configuration {
private val VersionMapping = new scala.collection.mutable.LinkedHashMap[(Long, Long), String]()
private val Data = new scala.collection.mutable.HashMap[String, String]()
def getData(key: String) = Data(key)
def addData(key: String, value: String) = Data.put(key, value)
def getVersion(timestamp: Long): String = {
val versionForDate = VersionMapping.collectFirst({
case (validityRange, value) if timestamp >= validityRange._1 && timestamp < validityRange._2 => value
})
// fail-fast if not found
versionForDate.get
}
def putVersion(from: Long, to: Long, name: String) = VersionMapping.put((from, to), name)
def getVersionedKey(key: String, version: String): String = s"${key}_${version}"
}
object DataGenerator {
def generateStats(version: String, entries: (String, String)*): Unit = {
entries.foreach(entry => {
val versionedKey = Configuration.getVersionedKey(entry._1, version)
Configuration.addData(versionedKey, entry._2)
})
}
}
object ApiReader {
def readUserStats(key: String, timestamp: Long): String = {
val versionToRead = Configuration.getVersion(timestamp)
val versionedKey = Configuration.getVersionedKey(key, versionToRead)
Configuration.getData(versionedKey)
}
}
Solution#2: Data source overriding
Another solution based on the similar concept is the data source overriding. Here, instead of changing the version, the data generator will write the data for some range of time to a different data source (e.g. a table with the suffix of the first stored datetime). And similarly, it could be represented in a table:
| Range start | Range end | Table |
|---|---|---|
| 2018-01-01 00:00 | 2018-01-10 23:00 | user_stats_20180101 |
| 2018-01-11 00:00 | - | user_stats_20180111 |
As in the previously described solution, both the generator and the reader must be synchronized about the data source/sink to use. The code base is quite similar and it's the reason why it's not presented here.
Drawbacks
It works since the need to clean the data is not required anymore. We can leave it expire with TTL mechanism provided with the data storage. However both solutions are not a silver bullet. Because of dealing with data as immutable, we needed to introduce an extra level of complexity in both reading and writing part. Now instead of simple write and read operations we need to make one or more lookups to the "routing" table. The increased complexity is especially true for the catastrophic scenario where the data must be regenerated more than once a day for different intervals.
Another important drawback, mostly for the 2nd solution, is related to the devops work in case of new data source creation. Since it'll be harder to do manually every time, this new part complexifies the deployment part (apart the table update that also has an impact here).
This post shown how immutable data benefits for a key-value data store. The first section presented the problem of times-series application where the values are generated per user-basis highlighting this utility. However as told, the data may need to be regenerated in the case of ingestion problems and that can lead to completely different output. So we can't simply leave it as that and some steps must be accomplished in order to distinguish the invalid from valid data. One of options could be the use of version appended to the key. Another one is the data regeneration for the data store with different name. Both avoid the need to delete already existent rows but they bring some architectural complexity. The generator and the reader must be aware of the places where a valid data resides for each of date ranges. Moreover, in the case of the 2nd option, some devops efforts must be done to create new data stores. Probably there are plenty of other options, maybe most appropriated than the ones described here. After all the goal of this post was to highlight the existence of this kind of problem and to give some basic options to solve it.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Immutability and key-value storage here:
- Temporal Versioning in Coherence General-purpose databases that never delete or update data in-place [closed]
Related blog posts:
An approach to deal with immutable #data stored in a key-value store presented in a short post https://t.co/KpN9GAMevX
— bardev (@waitingforcode) May 20, 2018