
January 10, 2020 I successfully passed my AWS Certified Big Data specialty with the overall score of 82%. Despite the fact that it will be replaced soon (April 2020) by AWS Certified Data Analytics - Specialty, I'd like to share with you my learning process and interesting resources.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
I organized this post same as My journey to AWS Cloud Practitioner. In the first section, I will give you some reasons why it's worth passing this certificate. Later, I will list the most important things I learned. I will terminate with a part listing useful learning resources.
Why is it worth?
Even though I work with AWS for 2017, I haven't used all of its data services. I used to work and feel pretty comfortable with AWS Lambda-based data processing, real-time data on Kinesis Data Streams, batch storage on S3, analyzing data from S3 or Redshift, or still processing it with Apache Spark on top of EMR. But, and I knew that before the exam, there are a lot of other interesting data services like:
- Glue - I did few POCs from the console, nothing prod-ready though
- Athena - I used it for ad-hoc querying but once again, with a lot of manual setup (see previous point)
- Lake Formation - only read blog posts and watch videos about it
- QuickSight - considered to POC it but always had other priorities
- Spectrum - as for Glue
- Kinesis Data Analytics - only saw the pipelines created by other data engineers, never experienced it on production
- Glacier - never needed but always wanted to give a try
- Snowball - well, without a real professional opportunity, it's hard to POC
- ... and many, many others
Thus, my first motivation was to discover the services that I haven't used to work with. Apart from the services, I also wanted to learn other aspects than data processing on AWS, such as data security and data visualization, even for the services I've already known.
My second goal, and I won't hide it, was professional. I believe that a Speciality certificate from AWS will open the doors to many interesting data projects. The time will say whether I'm wrong or not.
Things I learned
The most important lesson for me was about security. Before the exam, my knowledge about security was limited to IAM policies. By analyzing learning resources I learned that data can be secured at different levels. You can still use IAM but also, depending on the service, apply a fine-grained access, even going to row-level access with QuickSight! I will publish a blog post to summarize that security aspect soon.
The second thing is AWS IoT service. When I passed a mock-exam for the first time, I got a few questions about that service and said to myself that I had to at least know a little about it before the real exam. That's what I did. I even prepared a big schema of what parts interact in the service, that you can see in the following image:
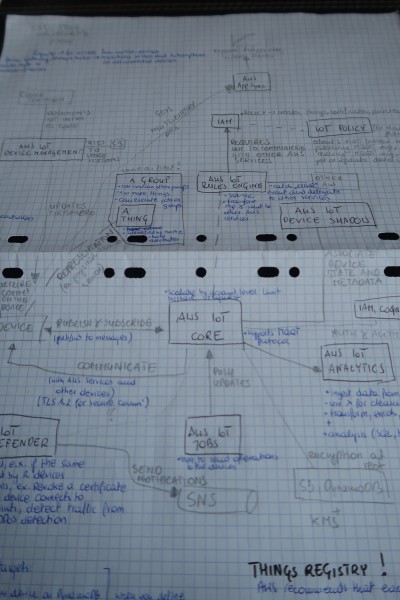
Another point concerns administration. Even though I'm not against ops work, I'm still more attracted by the code and try to prefer it over administrative tasks. The Big Data exam helped me to discover a lot of administration topics, like automatic snapshots (Redshift, RDS), automatic replication (DynamoDB global tables, S3 cross-region replication) and concurrency management at user's level (Redshift Workload Management).
As I mentioned in the first section, the exam also helped me to discover relatively new services in the AWS environment like Lake Formation. Here too, to understand it better, I did a small schema:
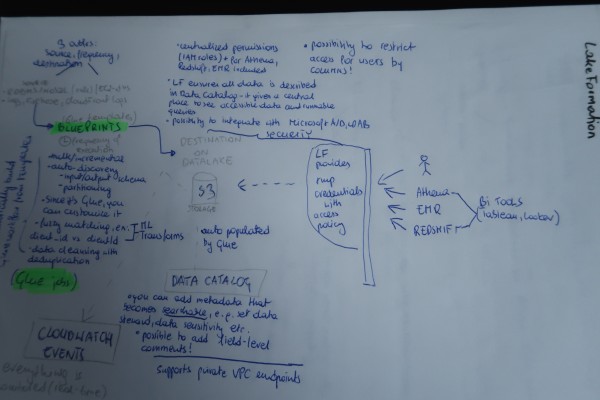
Another new topic was data visualization. I finally assimilated different visualization charts that, in this context, you can use with QuickSight. And here too, some graphical help was very precious:

Last but not least, data migration. I've never had to migrate data from on-premise to the cloud so haven't any idea about possible solutions. Thanks to the exam I discovered the idea of Snowball and its variance Snowball Edge. I also learned how to keep data on-premises and replicate it to the cloud with different Storage Gateways. Finally, I also familiarized myself better with the data migration between data stores with AWS Data Migration service.
My preparation
This time I started my preparation 6 months before the exam. During the first 4 months, I planned 2 schedules of 2 hours for taking notes, solving mock-exams. For the next month I added one more schedule of 2 hours. Finally, 2 weeks before the exams, I added an extra hour per day.
During the first 4 months I was taking notes directly from AWS documentation and white papers. I was adding every new or unclear concept to a kind of backlog I called "Things to learn". During that time I tried to divide my time between discovering new data services and handling these things to learn. From time to time, I was also doing 1 mock-exam per learning session.
For the mock-exams, I stayed with the ones I used for Cloud Practitioner exam, ie. Udemy (AWS Certified Big Data Specialty 2020 Practice Exam Test) and Whizlabs (AWS Certified Big Data - Specialty). Funny fact, I failed them all at the beginning ^_^ ... and felt unsure. The fact to fail helped me to systematize and extend my knowledge because I noted all these things on my "Things to learn" doc and learned about them afterward from available resources (mostly AWS documentation or FAQ). So a small tip to not take these mocks for real. I mean, if you fail, it doesn't mean that you know nothing but simply need to work a little bit harder to get things right. If you succeed for the first try, it simply means that you know the items tested in these specific mocks but cannot be sure that the real exam won't surprise you with something else, like a new service not covered there :P Nonetheless, it worth doing them and myself I prepared a test that should help you to systematize and check what do you know about AWS data services. It's already online and you can find it here AWS data services - 300+ practice questions.
Last two months before the exam I started to vary my learning resources by watching AWS videos about data services. I especially appreciated these ones:
- AWS re:Invent 2018: [REPEAT 1] A Deep Dive into What's New with Amazon EMR (ANT340-R1)
- AWS re:Invent 2018: [REPEAT 2] Best Practices for Amazon S3 and Amazon Glacier (STG203-R2)
- AWS re:Invent 2017: Advanced Design Patterns for Amazon DynamoDB (DAT403-R)
- AWS re:Invent 2017: Best Practices for Data Warehousing with Amazon Redshift & Redsh (ABD304)
- AWS re:Invent 2017: Deploying Business Analytics at Enterprise Scale with Amazon Qui (ABD311)
- AWS re:Invent 2017: Best Practices for Data Warehousing with Amazon Redshift & Redsh (ABD304)
- AWS re:Invent 2017: Analyzing Streaming Data in Real Time with Amazon Kinesis (ABD301)
- AWS Summit SF 2018: IoT Building Blocks: From Edge Devices to Analytics in the Cloud (SRV304)
- AWS re:Invent 2018: Big Data Analytics Architectural Patterns & Best Practices (ANT201-R1)
- AWS re:Invent 2018: Best Practices to Secure Data Lake on AWS (ANT327)
- Analyzing Data Streams in Real Time with Amazon Kinesis: PNNL's Serverless Data Lake Ingestion
- AWS re:Invent 2018: Serverless Video Ingestion & Analytics with Amazon Kinesis Video Streams ANT208
- AWS re:Invent 2019: [REPEAT 1] Serverless stream processing pipeline best practices (SVS317-R1)
- AWS re:Invent 2018: Leadership Session: AWS IoT (IOT218-L)
A tip for AWS videos - if you watch a re:Invent presentation of one specific service from different years, you can watch the first minutes on accelerated mode (2x). Most of the time, these first minutes recall the same basic concepts of the service and therefore, it will be sufficient to watch them at the normal speed only for the first time. I observed that when I watched the presentations of AWS IoT service.
I forgot to add, once again I was taking notes by writing them on the paper. I started to write them on my laptop but I felt less comfortable, especially when you take a look at the schemas I made to assimilate the ideas better. It confirms my experience from Cloud Practitioner preparations where I also have handwritten my notes. Maybe it's not something which works for you but it's worth trying if you don't know what's better.

Regarding the exam strategy, I also had one (well, 2 exactly). I tried first to qualify the question as being "easy", "easy but not sure" and "hard". As you can deduce, for the 2 former categories I answered quickly, within 30 seconds and when I wasn't sure, I was marking the question for review. For the "hard" ones, I was skipping them directly, without trying to do anything. Of course, when I reached the last question, I came back and tried to solve first the "easy but not sure" and "hard" just afterward. My other strategy was about questions. I answered them on batches of 10 and not in order. The exam has 65 questions overall and not be demotivated by keeping in my head that "I've still 50 questions to terminate...", I jumped for opposite batches. First, I took the questions from 1 to 10, later from 40 to 60, 20 to 30 and so forth. It helped to keep my motivation up throughout the whole exam because I had in my head the voice telling that "Good job, you have still 2 hours and you've done 50 questions" (even though, I did only 20 :P). It worked for me but always think if it's appropriate for you.
All of this, but also everyday practice on AWS (despite the limited scope of services), helped me to pass the exam with an overall score of 82%. This score was composed of: processing (100%), storage (100%), analysis (87%), data security (80%), visualization (71%) and collection (50%). I expected to score worse for analysis and visualization and better for collection but to be honest, I don't know why I did the opposite.

To sum-up, it's worth passing the certification unless you have on-field experience with all data services. The exam should not only help you normalize your actual skills but also extend them by forcing you to leave your comfort zone and discover other services.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
As promised last month, today I published a blog post about my journey to #AWS #BigData Specialty where I described the learning process and used learning resources https://t.co/l27T1hvK3J
— Bartosz Konieczny (@waitingforcode) February 16, 2020