
Guess what topic I was afraid of at the beginning of my cloud journey as a data engineer? Networking! VPC, VPN, firewalls, ... I thought I would be able to live without the network lessons from school, but how wrong I was! IMO, as a data engineer, you should know a bit about networking since it's often related to the security part of the architectures you'll design. And in this article, I'll share with you some networking points I would like to know before starting to work on the cloud.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Network resource isolation
The first mysterious thing you may encounter is the virtual private cloud, on Azure, also known as virtual network. The "virtual" is a keyword here because the network separation is logical; i.e, you're still on the cloud provider network but have a way to isolate it from the others. The isolation here means inaccessibility to this part of the cloud unless you configure your logical network otherwise.
In addition to the virtual network, you will need to manage subnetworks. They will help to distinguish between public and private resources. A very good example illustrating these visibility concepts is the web application diagram. The application should be accessible from the internet, but it's not necessarily the case of the database. You don't want other users to connect to it directly from anywhere, do you? Thanks to the subnetworks with different visibility, you can expose only the application part, like shown in the following cloud-agnostic diagram:
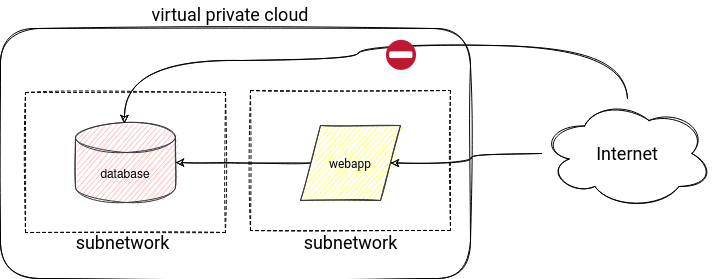
You can apply this approach to other cloud data services. For example, you could put the data warehouse inside a virtual network to allow access only from a restricted area like your office network, a specific IP range, or a subnet where you run the Apache Spark jobs.
Access filtering
The last sentence introduced another "good to know" concept. It's access filtering, so the control over the incoming and outgoing requests on top of your virtual network, like you can do with a firewall.
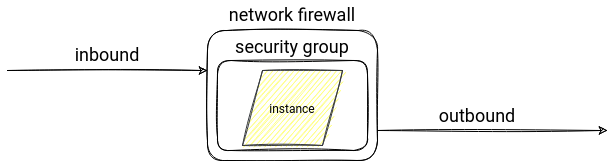
On AWS you can set this security with VPC security groups and Network ACL (NACL) features. What's the difference? The first is that the NACL operates at the subnet level and the security groups only at the EC2 instance level. So you can use the NACLS as the first filter layer before the request reaches the security group rule. Another difference is the type of the configured rules. NACL supports both deny and allow rules, whereas the security group only supports the latter ones. It means that the security group denies all traffic, and the NACLs allow it by default. Finally, the NACL is stateless, so you can only allow an inbound connection for a specific port. The security groups are stateful, which means that every allowed inbound connection automatically allows the outbound one (e.g. web server accepting requests at port 80 automatically will send the responses to the client).
On Azure, you will find a similar component called Network Security Groups (NSG) that applies at the subnet and the network interface level. The rules are also stateful, and they support deny or access configuration. It's also valid for GCP, where you can configure network security with Firewall Rules. They are also stateful, configured as an allow or deny action. They're associated with a VPC network but are enforced at the virtual machine level.
Each of these services has some extra features. GCP Firewall Rules can use tags or Service Account names to apply the rules to only specific instances. Azure has service tags that are aliases for different Azure services.
Internal traffic
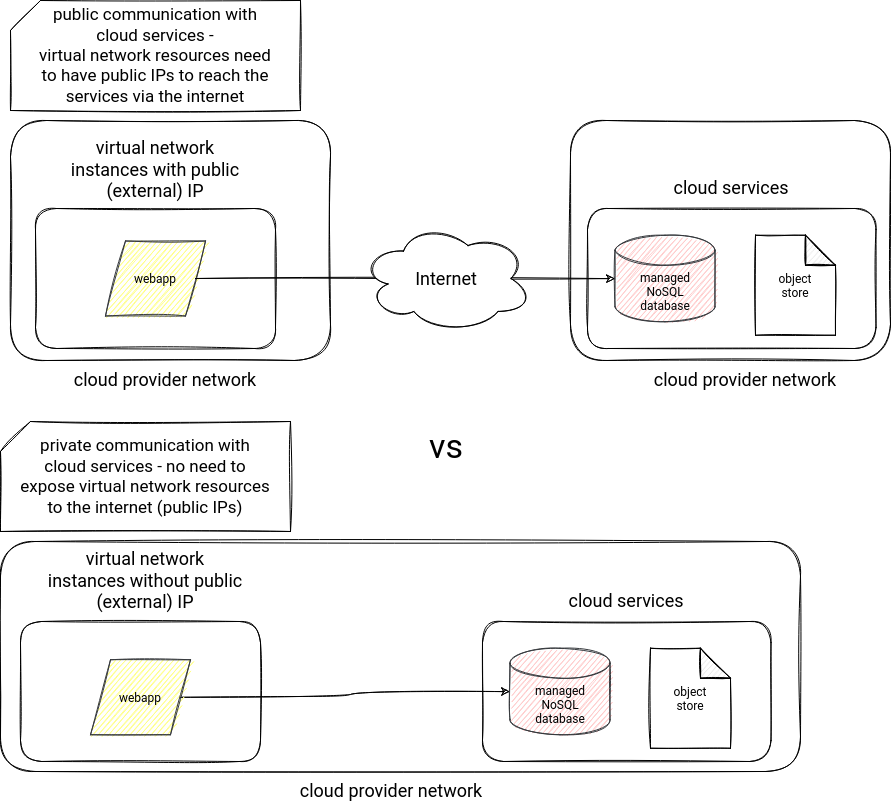
Another security point related to your network concerns the connection to the cloud services. It means that the traffic between your virtual network and other cloud services can be either public or private. The public traffic is the default one, and the connection is based on the service public IP, so it goes over the internet network (hence public). However, you can also configure it so that it'll stay within the cloud provider network! In that scenario, the connection will use the private IPs of your virtual network.
AWS supports this feature with VPC Endpoints. It helps to keep the traffic private with the help of an interface or a gateway endpoint. Azure implements similar concept with Private Endpoint. Thanks to it, private IP addresses in the virtual network can reach Azure services endpoints without requiring public IPs, hence without going across the public internet. On GCP, you will also find this feature. It's called Private Service Connect. You can find a common schema for all of them below:
Data exfiltration
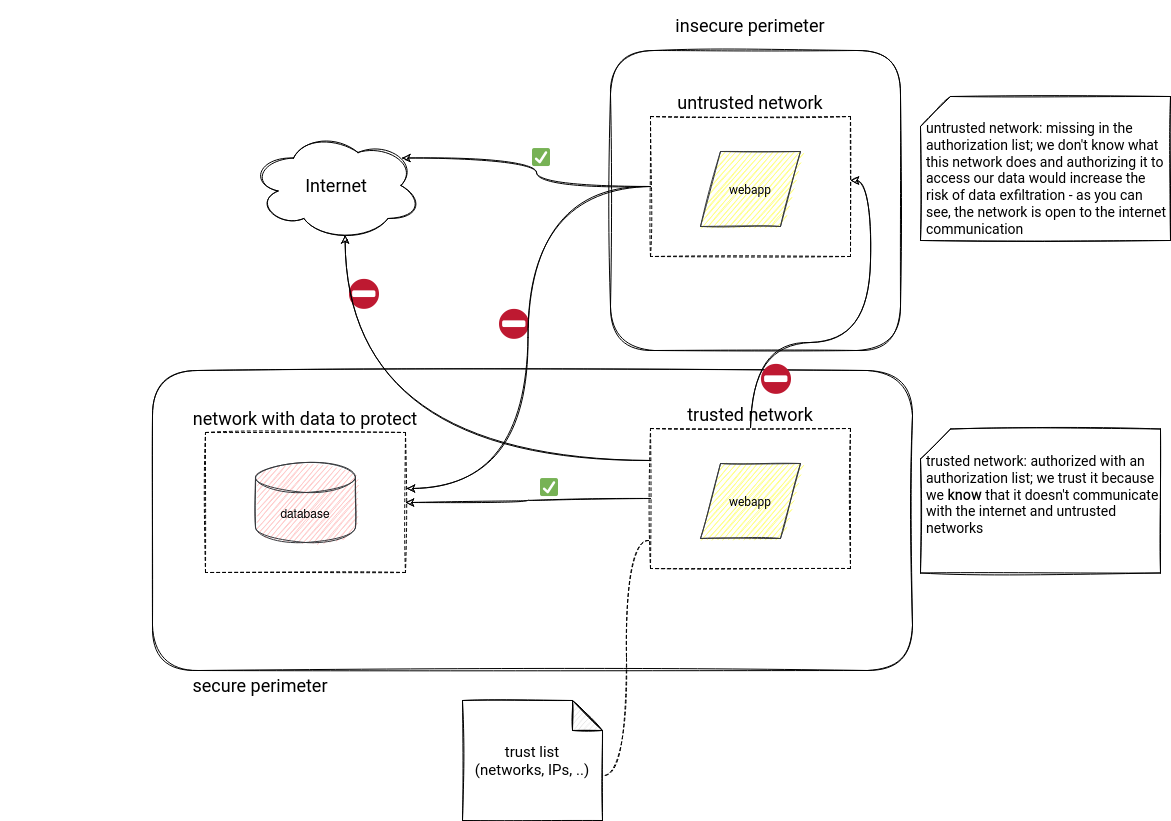
Another security layer you can implement thanks to the network services is data exfiltration protection. Data exfiltration happens when an authorized user transfers private data to other places. For example, you could imagine an external consultant who extracts your customers' database and shares it with 3rd parties.
Finding the protection strategy for GCP was an easy task. GCP networking has a feature called VPC Service Controls that creates a
Data exfiltration strategy on AWS and Azure was less obvious to define. Azure gives some ideas how to implement it in the Synapse documentation. The protection consists of creating a virtual network managed by Synapse to ensure that only the resources located in the approved AD tenant can connect to it. Put another way, there will be a list of trusted AD tenants, and only they will be able to access the deployed Synapse service.
A similar strategy exists on AWS where the authorization list is managed as a VPC Endpoint policy. The idea is twofold. First, in the policy attached to the VPC accessing a resource like S3, you have to define a list of allowed resources. They can be all your buckets the VPC resources can access to. It protects against copying data from the VPC to other buckets, not necessarily in your possession. The second part of the strategy uses S3 Bucket Policies where you can define the list of VPC endpoints authorized to access the data. It protects against extracting the objects with the help of stolen credentials via the internet.
I tried to summarize all these 3 strategies in the following high-level schema:
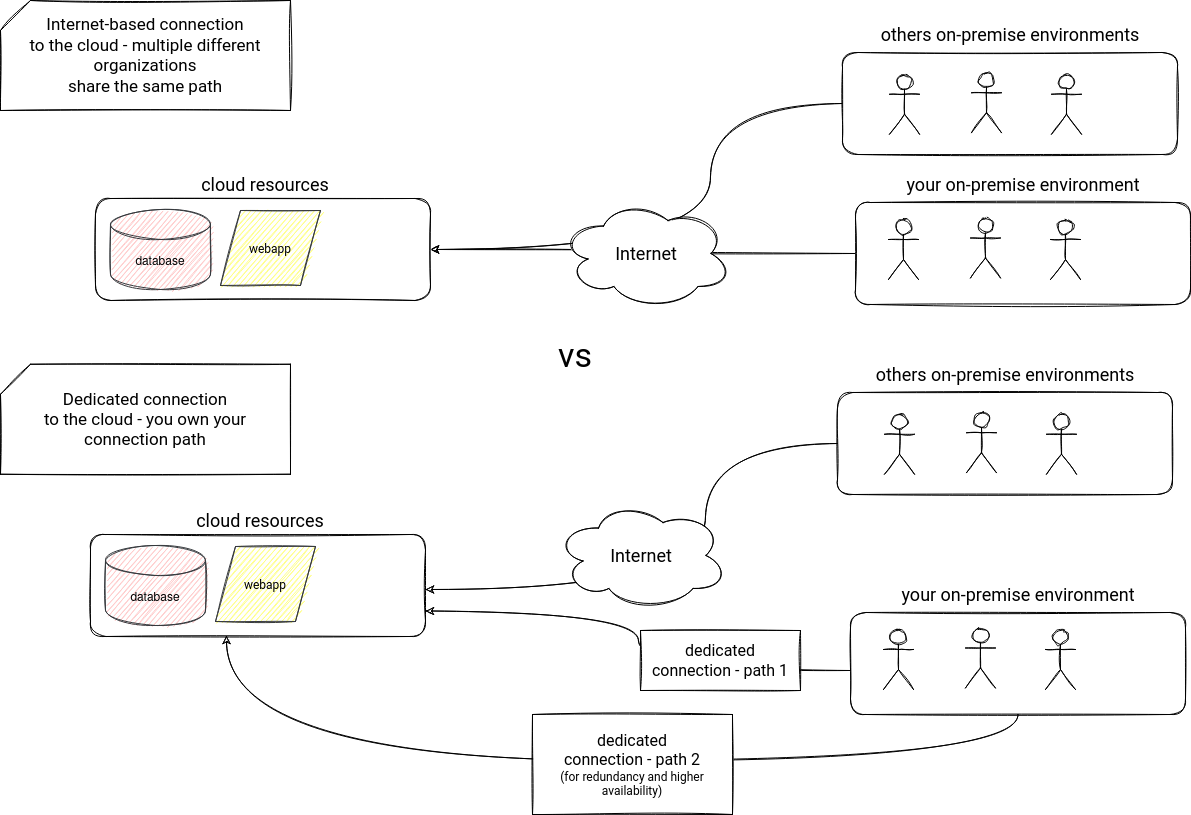
On-premise connection
The final part of the list concerns on-premise-to-cloud connection. As you learned in previous sections, you can access cloud services from a public internet network. But you can also set up a dedicated connection between your facility and the cloud provider. This approach has multiple advantages: private communication, throughput gain, and more consistent network experience.
AWS service responsible for this dedicated connectivity is Direct Connect. Azure offers the similar feature with a service called ExpressRoute. In GCP, it's called Interconnect.
Networking on the cloud is not an easy concept to approach, and as a data engineer, you will probably work with more network-skilled people like DevSecOps or DevOps. Nonetheless, I hope that thanks to this blog post, you understood some of - in my eyes - important networking concepts on the cloud and will be able to find a common vocabulary with them!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Cloud networking aspects for data engineers here:
- Do AWS Security Group and Azure Network Security Group work the same way? Network Security Groups in AWS and Azure – A Brief Overview Alternative to AWS's Security groups in GCP? Private Google Access Preventing Data Exfiltration Practical, Proactive Amazon S3 Security How to deny all outbound traffic from an AWS EC2 Instance using a Security Group? AWS, Azure, GCP: Virtual Networking Concepts Configuring Private Service Connect to access Google APIs Cloud Network Security 101: AWS Security Groups vs NACLs
Related blog posts:
- What's new on the cloud for data engineers - part 12 (10.2023-02.2024)
- Vertical autoscaling for data processing on the cloud
- What's new on the cloud for data engineers - part 11 (06-09.2023)
Networking aspects are maybe not the most appealing and/or the easiest in a data engineering cloud journey. In the new blog post, you'll find 5 cloud network aspects I would like to know when I started my cloud journey (hoping they can help you too!) ? https://t.co/vnHVOdWdao
— Bartosz Konieczny (@waitingforcode) August 22, 2021