
I haven't fully understood it yet, why the story of data architectures is the story of Greek letters. With time, they changed the context and had to adapt from an on-premise environment, often sharing the same main services, to the cloud. In this blog post, I will shortly present data architectures and try to fit them to cloud data services on AWS, Azure and GCP. Spoiler alert, there will be more pictures than usual!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Lambda
Among the architectures present here, the oldest one is the Lambda architecture. To recall, its main components are:
- speed layer - provides fast data insight that can be approximate. It mostly uses streaming technologies here.
- batch layer - as the name indicates, it relies on the batch processing. It has a component called master dataset used to overwrite the results generated by speed layer which, thanks to the batch nature of the processing, tend to be more accurate.
- serving layer - the place exposing data from speed layer (approximate) and batch layer (more accurate).
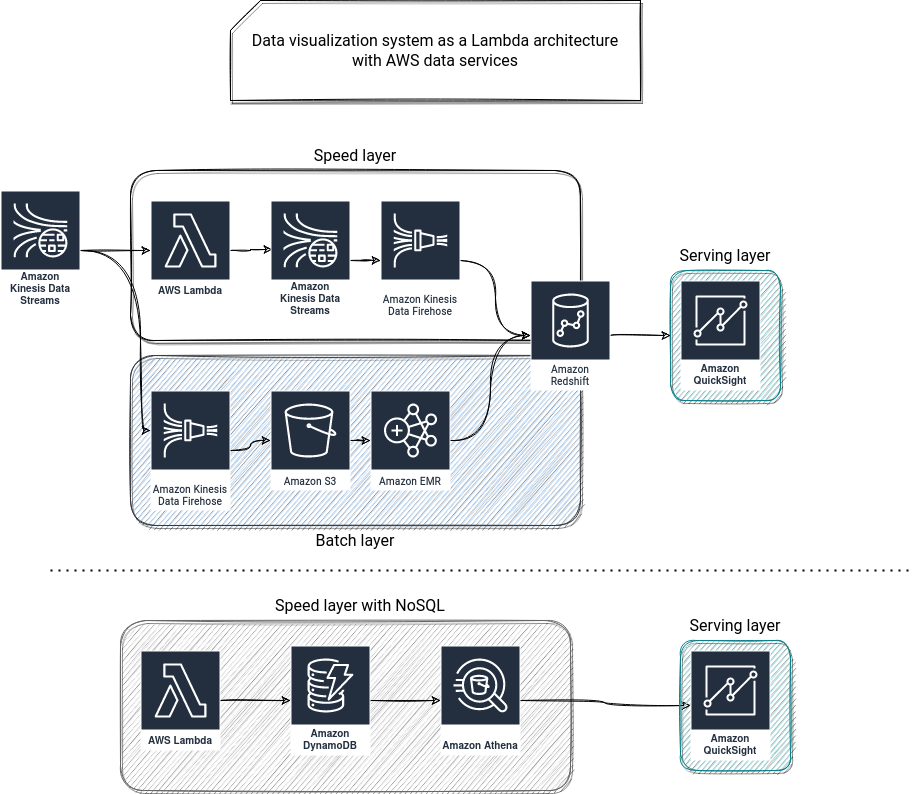
The system I will try to design for every architecture is a data visualization system that relies on fully managed services. For the Lambda use case, many architecture proposals will include a fast NoSQL database as the serving layer for the speed layer. I hesitated to use it because it complexified the data serving from this hot path a lot. That's why in the schemas below, I included a greyed box called "Speed layer NoSQL", representing an alternative approach to the - in my opinion - easier to maintain solution. The processing part is assumed to be not complex, i.e, not involve any complex operations like stateful aggregations.
It could be an RDS, but I preferred to try to make this part elastic and serverless with NoSQL, and it happens that it can be easily fulfilled with natively auto-scaled Lambda and DynamoDB. Unfortunately, as I mentioned before, this trade-off makes the exposition part more sophisticated because DynamoDB can't be directly exposed to QuickSight. But Athena can be and since it can connect to DynamoDB via the federated query, it's the reason for its presence. Also, keep in mind that querying DynamoDB that way can be costly if the query involves full table scan (check the Performance section of the connector) and if speed layer contains a lot of data (may not be the case since, it's there to only store the most recent data view). It could make more sense to add an intermediary, pay-as-you-go query-optimized storage instead of/next to DynamoDB, like partitioned columnar objects on S3. Thank you, Eric, for bringing this point.
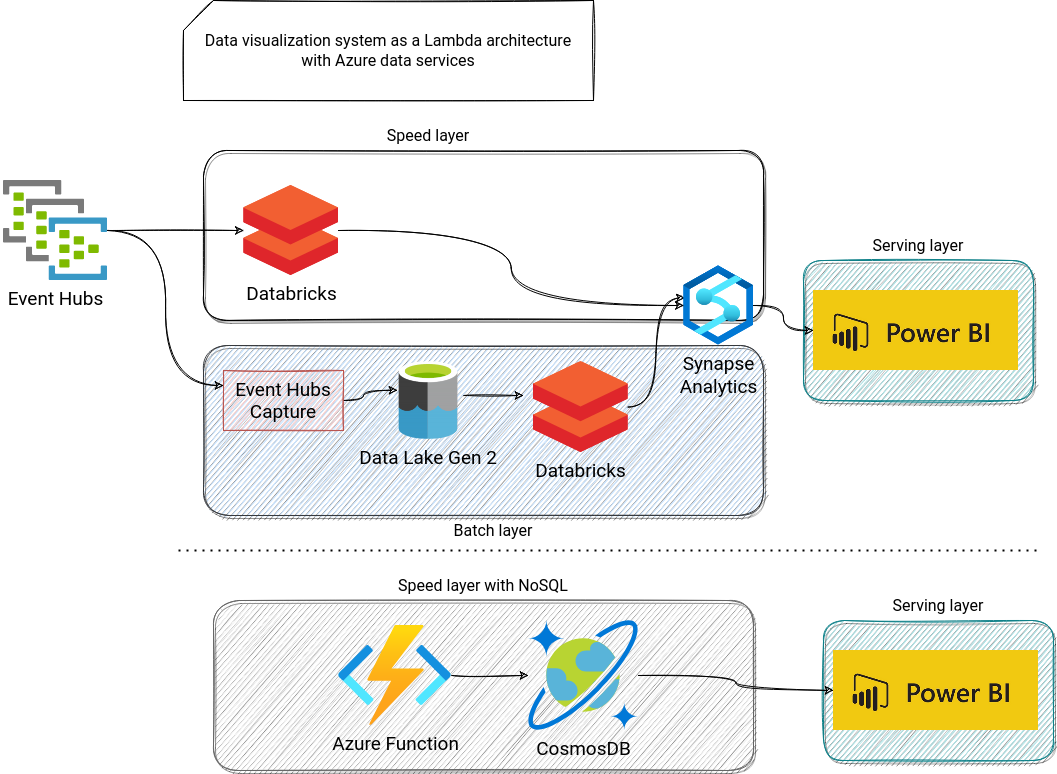
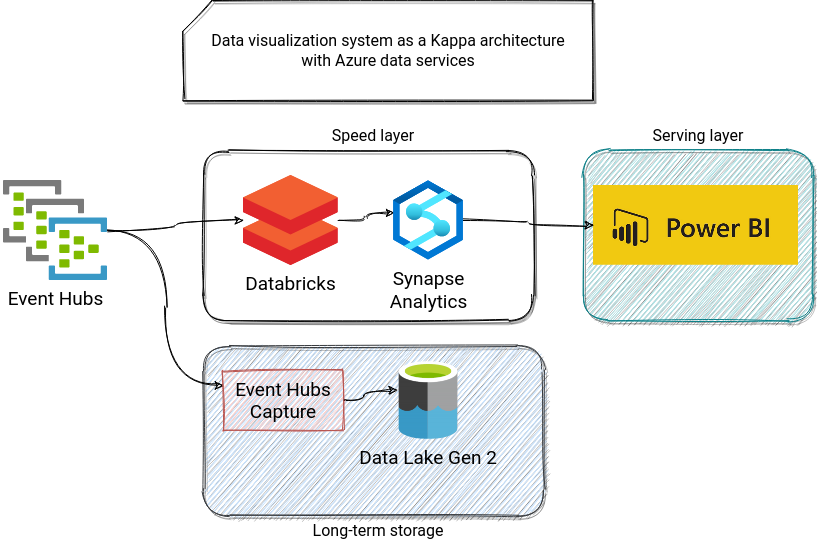
In alphabetical order, let's now see this architecture on Azure. This time, I replaced Lambda and Firehose with Databricks, which comes with a dedicated Synapse connector relying on PolyBase or COPY commands to optimize data loading. As an alternative version, we could use an Azure Function and CosmosDB. This time a CosmosDB connector is natively available for the BI tool, and hence there is no need to use any extra component like Synapse Link for CosmosDB:
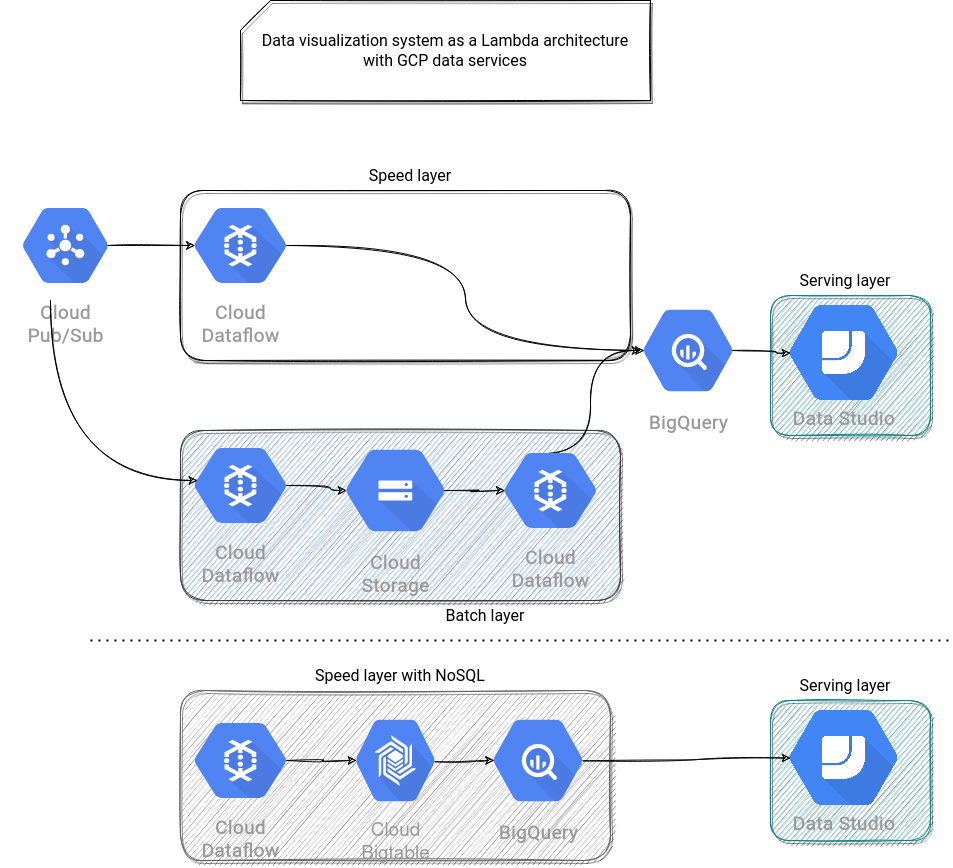
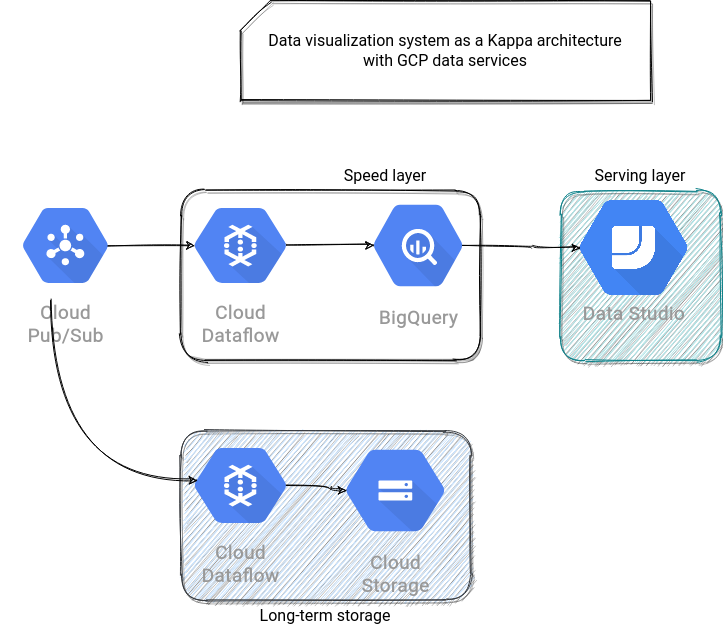
To terminate, let's see GCP. With Dataflow, a serverless data processing service, I could hardly imagine putting Cloud Function instead of the NoSQL Speed Layer. That is why exceptionally, it doesn't fit the same "principle" as 2 previous proposals. From the proposal above you can also see that exposing BigTable data to Data Studio is hard and I didn't find any better idea than using external data sources in BigQuery:
Kappa
One of the drawbacks of Lambda architecture is its complexity, often requiring maintaining 2 separate pipelines for the same functional requirement. Kappa is a simplification for Lambda. It relies on a streaming broker as a central component for the real-time part of the system. Unlike Lambda, it doesn't require linking the handled business part with the batch layer. Put another way, you will have one part of the system exposing data in real-time, with all its advantages and shortcomings, and another part of the system covering batch use cases. Because yes, you can still have the batch part for any computation not requiring real-tile insight. The difference is that this part doesn't interfere with the speed layer.
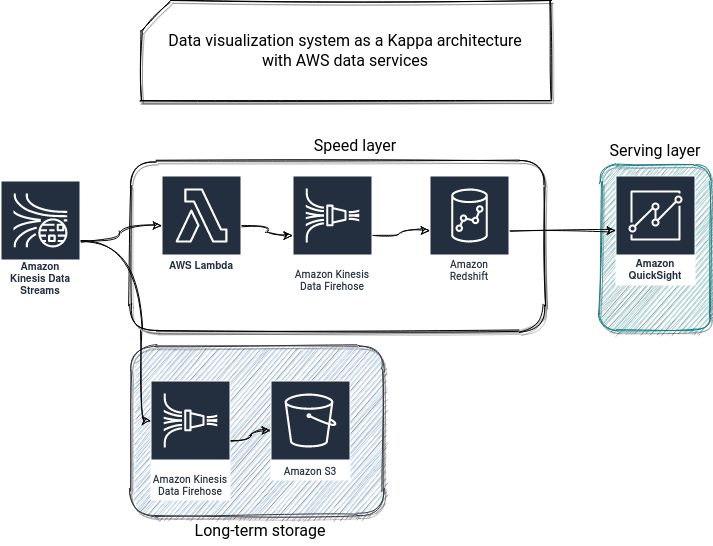
How to represent a Kappa architecture with AWS services? If you check the following schema, you will notice that it's like Lambda architecture but without the crossed arrows from the speed layer and the long-term storage. It means that our dashboarding problem is real-time, and we keep the data synchronized to long-term static storage for other use cases.
You will find a very similar approach in Azure and GCP architectures, presented below:
And for GCP:
Zeta
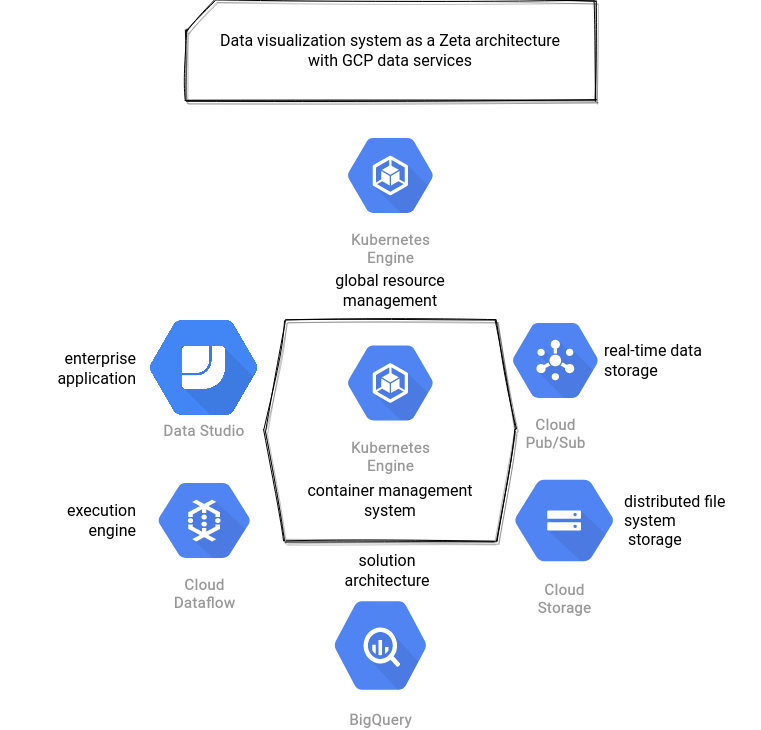
Zeta doesn't share the story of Lambda → Kappa's transition. Its main idea is to provide a holistic view of a data system, with an interesting "Hexagon is the new circle" paradigm. A Zeta system is composed of 6 different layers orchestrated by a container management system like Kubernetes, which can also be used in the Dynamic and Global Resource Management layer. Apart from this layer responsible for auto-scaling of the business applications and data pipelines, you will find the following components:
- distributed file system as the main storage layer
- real-time data storage if the application should cover the real-time use cases
- enterprise application which is the application solving a business problem, like, for example a recommendation system; very often, it will be the synonym of serving layer
- solution architecture which completes the enterprise application; for example, an enterprise application could be a mailing system and a solution architecture a spam detection engine
- execution engine which will be used to process batch or/and streaming data; it should be pluggable, so able to connect with the resource manager and container manager systems
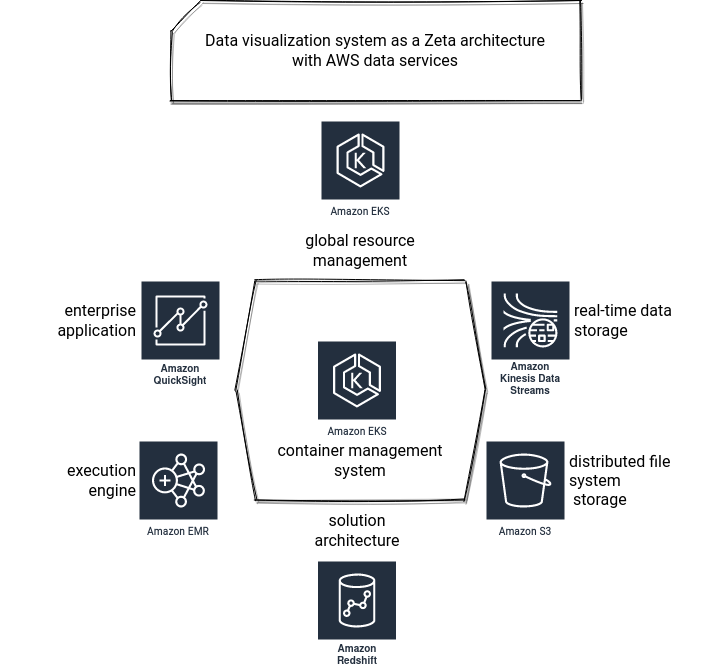
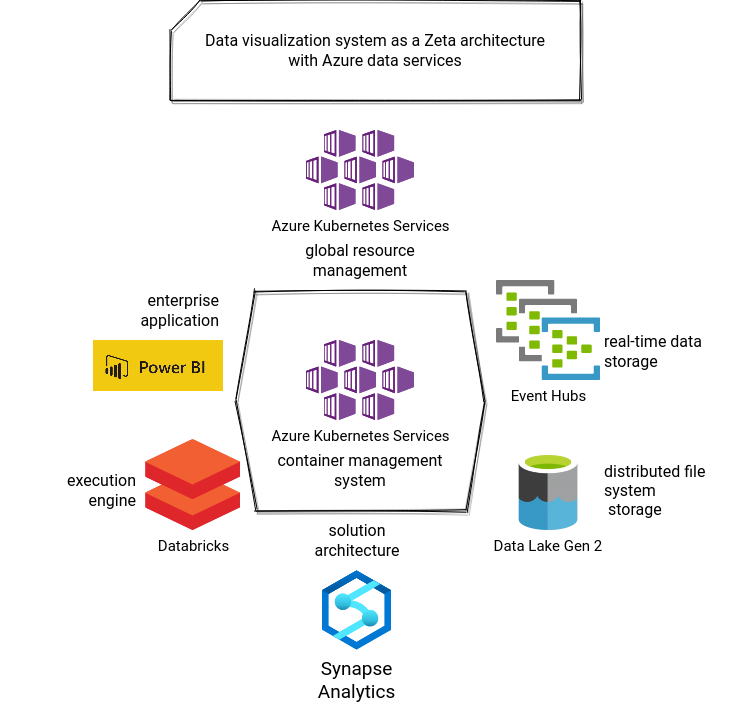
Unlike Lambda and Kappa, Zeta architecture requires much more components that are more heterogeneous and dependent on the application. Nevertheless, to stay in the same spirit, let's see how to implement a data reporting tool in Zeta architecture. One of the main principles of Zeta is to use containers to provide repeatable environments. However, we're working here with cloud services and therefore, there is little room for the "custom" things. That's the reason why the AWS architecture uses EKS only to run EMR jobs. Since other services are fully managed, there is no need to use EKS for them. It's not the case for Azure where Databricks runs under-the-hood on AKS and from what I've seen so far, Dataflow probably also relies on Kubernetes. That explains the link with GKE, even though I didn't find an official mention for that.
Another disturbing thing in applying Zeta architecture to the data visualization application was the role of the data warehouse exposing data directly to the BI tool. Is it an execution engine? A kind of distributed file system storage? Or maybe a solution architecture or an enterprise application? I decided to classify it as a solution architecture following this reasoning. The problem we're trying to solve is a fully managed data visualization tool, so it's the enterprise application. Is it an execution engine? It could be but solution architecture is IMHO more adapted because it provides a part of the solution for the enterprise application which is the data persistence and an optimized data layout.
Just below, a Zeta proposal for AWS...
...Azure:
...and GCP:
Delta
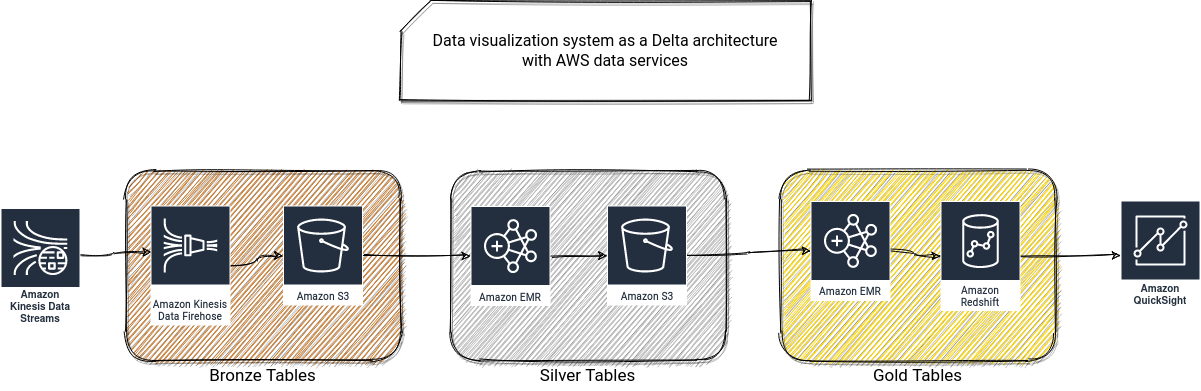
I hesitated to skip Delta and include Data Mesh or SMART instead, but I really liked the idea of representing data architectures with Greek letters :) Anyway, Delta architecture also addresses the complexity of Lambda architecture by exposing a single layer to the batch and streaming applications. This single layer is based on a transactional and streamable data format like Delta Lake. The data lands to tables. Each of them represents a different level of maturity of the data. The Bronze table stores raw data with all its data quality issues and eventually poor content. The Silver table stores enriched and cleaned data that will be the input for the Gold tables that exposes business meaningful data.
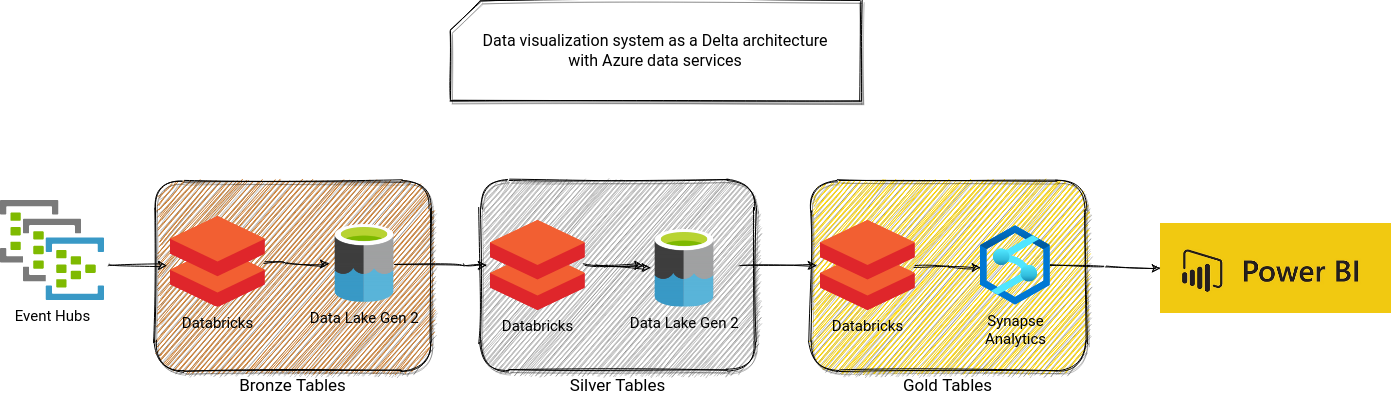
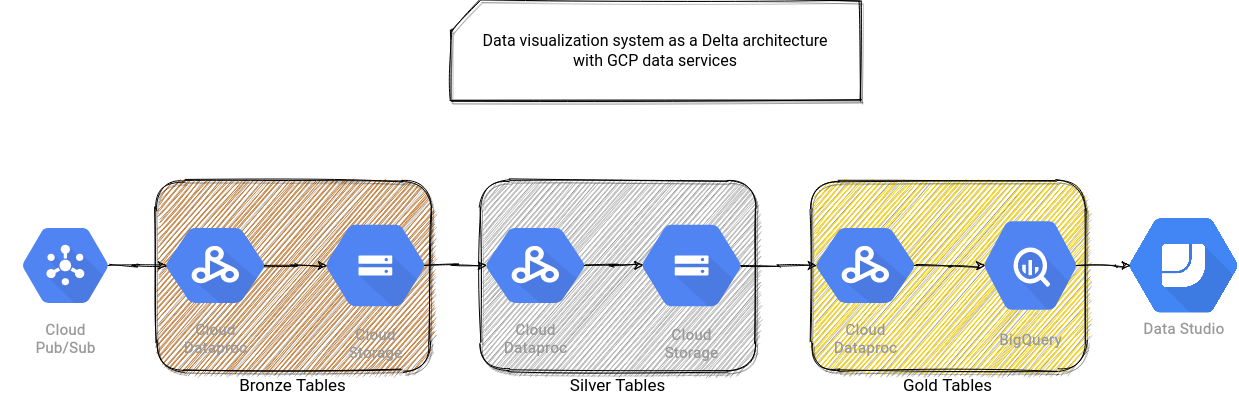
I designed all proposals on top of a managed Apache Spark service because I didn't find a way to deal with the aforementioned transactional and streamable file format differently. Also, for data exposition convenience, I "sacrificed" the streamable character of the Gold table and converted it to a pure static dataset persisted in a data warehouse layer. It was a pure pragmatic motivation since it's often easier to visualize the data from a data warehouse solution. Below you can find the proposals for AWS...
...Azure
...and GCP:
To be honest, I didn't expect some of the difficulties. For example, classifying a data warehouse in the Zeta architecture was not obvious, and maybe my point of view is not fully valid? Also, using the same data store for speed and batch layers in the Lambda architecture was not the obvious choice. Same for the data warehouse in the Gold layer of Delta architecture. All these were more subjective decisions adapted to the data visualization layer designed here.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Data architectures on the cloud here:
- Delta vs. Lambda: Why Simplicity Trumps Complexity for Data Pipelines Zeta Architecture: Hexagon is the new circle Visualize DynamoDB data in AWS Quicksight What is Azure Synapse Link for Azure Cosmos DB? Azure Synapse Analytics Developing solutions with BigQuery and Data Studio - DataVis DevTalk Querying Cloud Bigtable data Push data from AWS lambda to Kinesis Firehose Questioning the Lambda Architecture Understand the architecture of Azure Databricks spark cluster Announcing Azure Databricks Power BI Connector (Public Preview)
Related blog posts:
- What's new on the cloud for data engineers - part 12 (10.2023-02.2024)
- Vertical autoscaling for data processing on the cloud
- What's new on the cloud for data engineers - part 11 (06-09.2023)
What do Greek letters, data architecture and cloud have in common? They're the topic of the new blog post about data architectures on the cloud ? https://t.co/owQjv4w7BY
— Bartosz Konieczny (@waitingforcode) July 25, 2021