
As you know from the last 2020 blog post, one of my new goals is to be proficient at working with AWS, Azure and GCP data services. One of the building blocks of the process is finding some patterns and identifying the differences. And before doing that exercise for BigTable (GCP) and DynamoDB (AWS), I thought both were pretty the same. However, you can't imagine how wrong I was with this assumption!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The article will start by shortly introducing these 2 services with their main use cases. Further sections will list the differences between them, and the final one will summarize their similarities. The goal is not to say which one is better. Rather than that, I wanted to highlight the differences and similarities to share a quick start guide with you.
Short introduction
Why did I think that both are equivalent? Mostly because of the recommended use cases. Both services are often recommended for use cases requiring low latency access. Both also belong to the family of query-driven databases, i.e., where you should define your schemas - and more exactly the primary keys of the tables - according to the query patterns. And finally, both are schemaless and key access-based data stores. But it's only a high-level view, and if we go into the details, we'll see that those are only the appearances.
Architecture
Let's focus first on the underlying architecture, or at least on what we can learn from the documentation. DynamoDB is a fully serverless architecture, i.e. everything you have to can do is to define the read and write capacity of the table. On the other hand, you have a bit more setup to do for BigTable. Not only you need to define an instance. The instance is a container for the clusters that will be responsible for storing the data. For the definition, you can specify the parts like storage type (SSD, HDD) or the application profile to control how the consumers will connect to the instance. From this very first architecture comparison, you can see that DynamoDB relies on the serverless paradigm, and you work at the table scope, i.e., you define the throughput capacity for a table. BigTable is different because you directly work with all tables via the created instances.
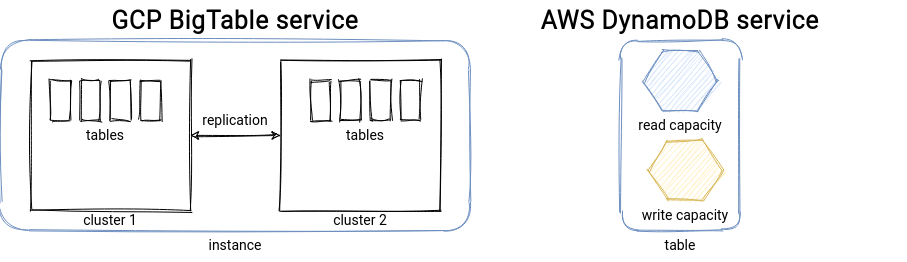
The serverless vs. server-based differences also impact the operational overhead. For BigTable, you have to provision your infrastructure, whereas for DynamoDB, you can use the auto-scaling feature to adapt the throughput to the current workload. But don't get me wrong. BigTable can be scaled as well! The difference is that you'll have to write your scaling application and trigger it in response to the monitored metrics like CPU or requests throughput.
But scaling is not the single concern we could put into this architecture-related section. Another one is about the replication, and more generally, the availability. DynamoDB stores data on SSDs replicated across multiple zones within a single region. In addition to this, it comes with a custom, on-demand backups and continuous backups to bring the Point-In-Time Recovery(PITR) - you can time travel up to 35 days in the past!
Regarding BigTable, the replication is explicit, i.e., it's your responsibility to specify whether you want it or not. But it gives you a bit more flexibility because, with the application profiles, you can delegate the load to a single cluster. Also, the backups are a bit different. They're stored in the cluster, and so they're coupled to its lifecycle. It means that when the cluster zone goes offline, the backup too - and there is no way to export backups elsewhere (e.g., GCS). It doesn't happen for DynamoDB's PITR feature, which keeps the last backup during the 35 days even after the table's removal. But once again, the difference comes from the conceptual difference - the BigTable is a container of tables, DynamoDB is a particular table.
Data storage
Apart from the architectural differences, both data stores have different storage concerns. The access is key-based, but the similarity stops here. The first difference is the support for secondary indexes. DynamoDB provides built-in support for local (same partition key but different sort key) and global (different partition key) indexes. Secondary indices don't exist in BigTable. And since we're talking here about the keys in the tables, it's worth mentioning that BigTable also doesn't support the sort key. The rows are always sorted lexicographically by the row key, meaning that this row key must be unique. It's not true for DynamoDB if the sort key column is defined - you can then store multiple rows sharing the same "main" key of the table.
Even though it looks like a limitation, BigTable compensates it slightly with the big sparse storage. The max size allowed for a BigTable row (recommended max size is 100MB) is much bigger than in DynamoDB (400 KB). You can use this fact to overcome the lack of a secondary index and create wide tables with many events by row. BigTable storage at the cell level is sparse, i.e., a missing attribute doesn't take place. However, please notice that even if it's a technically possible solution, the recommended approach for time-series is to use tall and narrow tables (fewer events per row) and eventually fallback to the wide tables only if it's possible to control the number of columns.
By the way, this brings 2 other topics. The first of them is the storage of the row attributes. In BigTable the columns are grouped into column families and every column family has the columns sorted lexicographically. And it's one of the performance levers because every column family's data is stored and cached together. So if you query it every time, you can unconsciously optimize the reading path. Regarding DynamoDB, I didn't find any mention of the attributes collocation.
And the second thing is the recommendation for dealing with time-series data. If you check DynamoDB's documentation, the recommended practice is to work with time-partitioned tables. It's not the same for BigTable, which advices having less tables, and the general rule of thumb is not to create a new table for the datasets sharing the same schema. Multiple tables can increase the connection overhead and also make the automatic load balancing less efficient.
Reading the data
So, we know already about the data storage, but what to do to query this data? On the BigTable's side, the simplest read operation is the single-row read, i.e. the read using only the primary key. The same operation exists on the DynamoDB side, but you can add additional fetch criteria since it supports the secondary key in the table.
The second type of interesting query type in BigTable is the the read with row key prefix. It doesn't exist in DynamoDB even though an begins_with operation is there. Unlike BigTable, this prefix-based search can only apply on the sort keys.
The final read type where BigTable outperforms DynamoDB is the range read. If you want to get rows included within a row key range, you need to define the start and end of the interval. For example, to get the goals scored by a player between 01/01/2020 and 01/03/2020, you have only to set 2 range keys, like player#20200101 and player#20200301. To query the same data in DynamoDB you would need to generate all dates between these 2 and query the exact keys. The good thing to notice on this occasion is that you can do it with the batch queries to maximize the throughput.
Of course, apart from these main query types, both data stores support scans of the table, and, unsurprisingly, for both of them, they're less optimized than key-based fetches. To optimize this scanning feature - if you don't have the data to process in more scalable and parallelizable storage like an object store - in BigTable you can use application profiles. Yes, I mention it once again, but it's something that doesn't exist in DynamoDB and seems to be a way to optimize a lot of things, scans including.
If you set up multiple clusters in the BigTable's instance, you can create an application profile with the single-cluster routing policy to move all requests coming from the batch consumer using this profile to a specific cluster. This way, you may isolate the real-time workloads from the offline ones. To handle this scenario in DynamoDB you cannot control the reads, but you can always export the table to S3 and query your items from there.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about GCP BigTable or AWS DynamoDB, yet another comparison here:
- Managing Throughput Capacity Automatically with DynamoDB Auto Scaling Programmatically Scaling Cloud Bigtable Patterns for row key design Best Practices for Handling Time Series Data in DynamoDB BigTable and tables design
Related blog posts:
- What's new on the cloud for data engineers - part 12 (10.2023-02.2024)
- Vertical autoscaling for data processing on the cloud
- What's new on the cloud for data engineers - part 11 (06-09.2023)
What's the difference between #AWS DynamoDB and #GCP BigTable ? If you're asking this question too, maybe the new blog post will shed some light on it ? https://t.co/O8I6MYokR2
— Bartosz Konieczny (@waitingforcode) February 21, 2021