
Data ingestion is the starting point for all data systems. It can work in batch or streaming mode. I've recently covered the batch ingestion pretty much already with previous blog posts but I haven't done anything for the streaming, yet. Until today when you can read a few words about HTTP-based data ingestion to cloud streaming brokers.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Data ingestion aspects
Ingesting data from an HTTP endpoint is not only a matter of exposing a web service accepting POST requests. The architecture brings several challenging points with regard to the endpoint and the destination store, such as:
- Reliability. What to do if the endpoint doesn't succeed in delivering the data in the first request?
- Fault-tolerance. What happens with the data if the API client or the endpoint fails?
- Throughput. How to optimize the throughput and scale accordingly to the changing traffic?
- Security. How to manage the authorized applications?
Reliability and fault-tolerance
Let me start with the first 2 points that can be fully addressed on the application side. The first solution uses synchronous communication between the client and the endpoint. In the first step, the client sends one or multiple events to the ingestion API and waits for the confirmation of the successful delivery which is also synchronous. You can find the example in the following schema:
This solution is relatively easy to implement, but the synchronous character brings extra latency. The client is obliged to buffer the new events as long as the endpoint doesn't confirm the delivery. Additionally, the client buffers the data and in case of a failure, it can lose it. Can we do better? Yes but let me solve one problem at a time:
- Latency. The easiest solution is to replace synchronous communication with asynchronous:
- Data loss. The protection relies on data persistence. The client is often a web or a mobile application. Both have a way to persist data locally, for example, with Web Storage API or internal storage. The endpoint can have a persistent disk to checkpoint all in-flight writes.
Unfortunately, these improvements also negatively impact the interaction. First, writing things on a disk is slower than keeping them in memory. Secondly, the solution has an at-least-once delivery guarantee. Despite a correct delivery to the streaming broker, the endpoint can still fail before notifying the client about it.
However, as with many other solutions, the one designed here is also based on trade-offs. If you have to ensure all messages are delivered only once, the synchronous approach looks best. On the other hand, if you favor the performance over the exactly-once delivery, the asynchronous code without the local checkpoint sounds better. And if you do care about reducing the data loss, you can think about extending the approach by checkpointing.
Data ingestion infrastructure
AWS, Azure and GCP have a dedicated API management service. It doesn't provide the compute capacity, though. The service acts more as a proxy between the client and the cloud resources responsible for executing the HTTP request:
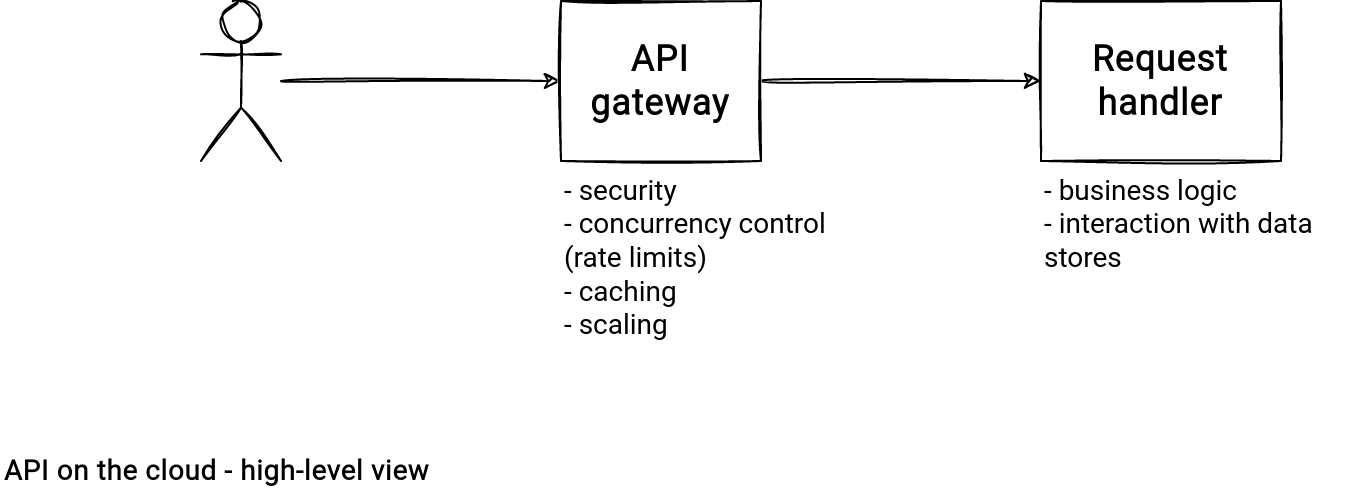
Each component from the schema has its own implementation and responsibilities:
- Client. It can be anything able to make an HTTP request, so a mobile app, a web app, or a backend without User Interface. The client doesn't need to use a cloud SDK because the communication relies on the HTTP protocol. Instead, it should have a good and easy-to-use HTTP library. However, it's also possible to use the SDK which very often has additional features, such as retrying throttled requests.
- API Gateway. This component is the API entrypoint, providing the implementation for the security, scalability, and backpressure mechanism of the API. The services implementing the gateway are named in a similar way. On AWS and GCP you'll find an API Gateway while on Azure, you'll rather work with API Management.
- Request handler. It's the component where the real request handling happens. Very often, the implementation will use here serverless functions which are cheaper, easier to manage and to scale than the VM-based solutions.
I've already covered pretty much the Request handler in the previous section by presenting the synchronous and asynchronous data writing. The remaining component to explain is the gateway. I summarized the answers in the following table:
| AWS API Gateway | Azure API Management | GCP API Gateway | |
|---|---|---|---|
| Backpressure (throttling) | Yes. The service supports rate limit configuration. The configuration works at various levels: client (different limit for each API key), method (different limit for each API method), or API (common for all API methods). | Yes. The service supports the feature with Inbound processing policies. The mechanism has a fine-grained configuration that can define special throttling rules for a key, like the request IP address, or a header. | Yes. However, it's not easy to find in the documentation. I've only discovered how to configure this part in this Beranger Natanelic's blog post. The rate limits implementation uses Open API specification passed to the gateway configuration during the setup. |
| Authentication | The service implements various authentication mechanisms: Lambda Authorizers (token-based or request-basted), resource policies (defines access rules for IPs and VPCs), IAM (roles, policies and tags), endpoint policies for interface VPC endpoints, and Amazon Cognito user pools. | The authentication uses one of the available policies: HTTP Basic (Authorization header in the request), client certificate, managed identity. | The service has 3 main authentication mechanisms: API keys, service accounts, and JSON Web Tokens (JWT), also called Google ID tokens. |
| Networking | API Gateway can be public and open to internet access, or private, hence accessible only from a VPC. Resource policies can provide even finer-grained access and reduce the accessibility from select VPC, not necessarily located in the same AWS account. | An API Management instance can operate inside a VNet. It makes the API private and enables the communication with other resources present in this hidden network space. | I didn't find a way to implement the private connectivity inside a VPC. |
| Data encryption in transit | The APIs exposed by the service work only with HTTPS protocol. The gateway supports 2 versions of the TLS protocol, 1.0 and 1.2. You can customize them in the security policy. | The API Management supports multiple TLS protocols for the client and backend sides. Moreover, you can enforce the HTTPS access with an appropriate Azure Policy definition. | The service supports HTTPS access with the SSL certifications managed by GCP. |
| Scaling | If the gateway doesn't have a throttling configuration, it passes the incoming requests with the respect of service quotas, to the backend service. For example, a Lambda backend will use the auto-scaling capabilities of the Lambda service, still limited by quotas, though. | The scaling consists of manipulating units. They represent the compute capability of the service. Except for changing the tier from/to Developer, units change doesn't involve downtime. Additionally, the service supports auto-scaling. The Standard and Premium tiers use Azure Monitor rules for that while the Consumption tier scales automatically, without any configuration required. | The GCP implementation is described as a scale-to-zero service. It means that the service will adapt the number of instances to the traffic, respecting the service quotas. As for AWS, the backend also impacts the scaling capabilities. |
Even though your data engineering responsibility should end with the reliability and fault-tolerance, it's good to be aware of what happens with the runtime environment presented in the last section. It has a significant impact on the concurrency and can drive some of your implementation decisions.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about HTTP-based data ingestion to streaming brokers here:
- Creating and using usage plans with API keys Rate limit Google Cloud Functions with API Gateway Operating Lambda: Application design – Scaling and concurrency: Part 2 What is the difference between API Gateway provided by Azure API Management and Azure Application Gateway? Use Azure Policy to enforce HTTPS in Azure API Management
Related blog posts:
- What's new on the cloud for data engineers - part 12 (10.2023-02.2024)
- Vertical autoscaling for data processing on the cloud
- What's new on the cloud for data engineers - part 11 (06-09.2023)
Recently I've covered offline data ingestion to the cloud data architecture. Today it's time to catch up on online ingestion. The blog post with client and cloud services part is just here ? https://t.co/vnoAXVNMWC
— Bartosz Konieczny (@waitingforcode) April 24, 2022