
I had a chance to use, for a longer or shorter period of time, 3 different cloud providers. In this post I would like to share with you, how my perfect cloud provider could look like.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this every section of this post I will address one component of a data system and try to explain exactly why this one I preferred. I will probably tend to describe a lot of AWS services but it's simply because I knew them the best. If you see that the same feature is available on other providers and I didn't mention it, drop me a comment and I will integrate your remarks in the article!
Distributed data processing
I'm starting with my favorite topic. One could think that as an Apache Spark enthusiast, my choice was easy. But it wasn't the case. When I discovered Dataflow, GCP's managed service for distributed data processing, I was amazed by all its features I tried so hard to implement during my weekly Apache Spark explorations, like auto-scaling and stragglers management.
Fortunately, I discovered also Databricks and decided to put this service on my list as the distributed data processing layer. The service implements auto-scaling and is based on an Open Source and quite mature technology like Apache Spark. In consequence, you won't only benefit from some *asService features (auto-scaling) but also gain all Open Source community feedback and support. Don't get me wrong, Apache Beam which is an Open Source entry point for Dataflow, also becomes more and more popular but in my eyes, there is still a small gap with the Apache Spark community.
Another reason in favor of Databricks comes from the notebooks and collaborative work. The notebooks exist too on Dataflow (Apache Beam notebooks) but they're still in beta version (as of 11.10.2020).
So for data processing I'm choosing Databricks on Azure since it's natively integrated on this cloud provider.
Streaming broker
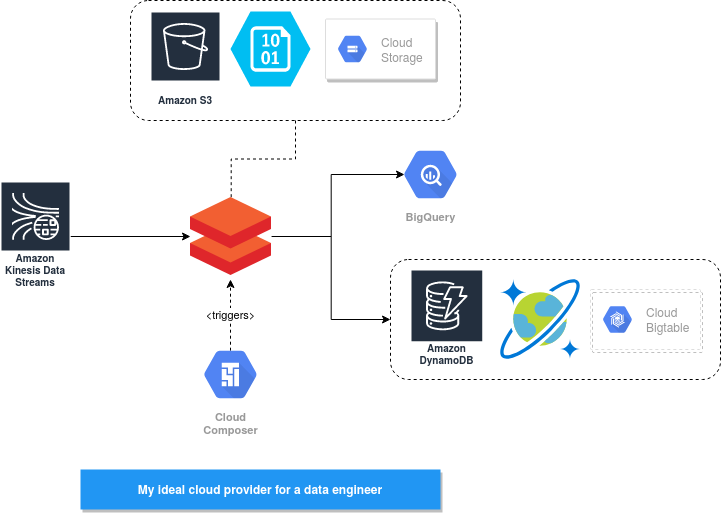
As a streaming broker service, I would like to use AWS Kinesis Data Streams service. Its semantics are very similar to the Kafka's ones (shard = partition, stream = topic), even though it doesn't support Apache Kafka's producers like Azure EventHub.
Another advantage of Kinesis is its scalability, you can scale it up and down, depending on the current workload. This operation is called resharding and can be a good way to have better control over the costs and scalability.
Also, Kinesis is not only a streaming broker but also an ecosystem. Once again, you can have similar thighs on GCP or Azure (eg. Azure EventHub Capture) but what I liked was the possibility to run serverless streaming applications with Kinesis Data Analytics and Apache Flink.
What is missing (IMHO) in Kinesis and is present in the concurrent messaging systems, is the native deduplication support for the Pub/Sub on Dataflow (GCP). Even though the deduplication window is relatively small (10 minutes), it's good to have it and eventually extend to the other mechanism, if the period reveals to be too small.
Data warehouse
In this field I was seduced by GCP's BigQuery service, a serverless data warehouse with flexible pricing (on-demand or flat). Apart from that, it also has good SQL support and some interesting features like partitioned and clustered tables, not mentioning the real-time data ingestion from Pub/Sub 😍
As a serious alternative I was thinking about AWS Redshift but finally, the fully serverless aspect of BigQuery was determinant.
Orchestrator
Here the clear winner is GCP Cloud Composer. As Databricks, it's a managed and enhanced version of an Open Source solution which here is Apache Airflow. So you gain not only a service but also all the community which is behind it! And the community, especially in hard times when you look for solutions or architectural guidelines, it's a resource that you will appreciate very much.
By the past I also tried to work on AWS Data Pipeline but found it quite hard to use. I had a better experience with Azure Data Factory but I'm still wondering why the deployment model is UI-first and not code-first? That being said, you have to write the code to work on the ARM templates but didn't find a lot of materials about alternative, code-only deployment methods. Since this is about "my" ideal cloud provider and I prefer the code-first approach, I decided to keep Cloud Composer for the orchestration layer.
Other components - hard choice
Regarding other important components of data architecture, the choice was harder to make. I couldn't decide which one of object (S3, GCS, Azure Blob) or data lake storages (Azure DataLake) to use for the batch layer. Same for key-value stores where I hesitated between AWS DynamoDB, GCP BigTable and Azure alternatives (CosmosDB and Storage Table). Initially, I wanted to choose the former one because of the streaming processing support with DynamoDB Streams. However, I discovered later that CosmosDB also provides this option with the Azure Change Feed feature. Same dilemma is also valid for the data catalog feature where a dedicated solution exists on every cloud provider, and for the monitoring layer where all of the 3 are quite good.
To sum up, my ideal cloud provider would look like this in this schema. And what's yours?
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about An ideal cloud for a data engineer here:
- Introducing Databricks Optimized Autoscaling on Apache Spark™ Databricks Unified Analytics Platform Developing interactively with Apache Beam notebooks Stream Processing Changes: #Azure #CosmosDB change feed + Apache Spark Efficient deduplication
Related blog posts:
- What's new on the cloud for data engineers - part 12 (10.2023-02.2024)
- Vertical autoscaling for data processing on the cloud
- What's new on the cloud for data engineers - part 11 (06-09.2023)
Today I did an exercise and tried to imagine *my* ideal cloud provider for data engineers. The result is here ? https://t.co/htW3Cq7j3i And what will be yours?
— Bartosz Konieczny (@waitingforcode) October 11, 2020