
Streaming broker is one of very common entry points for modern data systems. Since they're running on the cloud, and that one of my goals for this year is to acquire a multi-cloud vision, it's a moment to see what AWS, Azure and GCP propose in this field!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Even though AWS, Azure and GCP extended their streaming services offerings with managed Kafka clusters, I will focus on the major and native streaming offerings in this blog post. It will be then Kinesis Data Streams for AWS, Event Hubs for Azure and Pub/Sub for GCP. After this blog post, you should better understand their similarities and differences in architecture, consumers, and producers.
Architecture
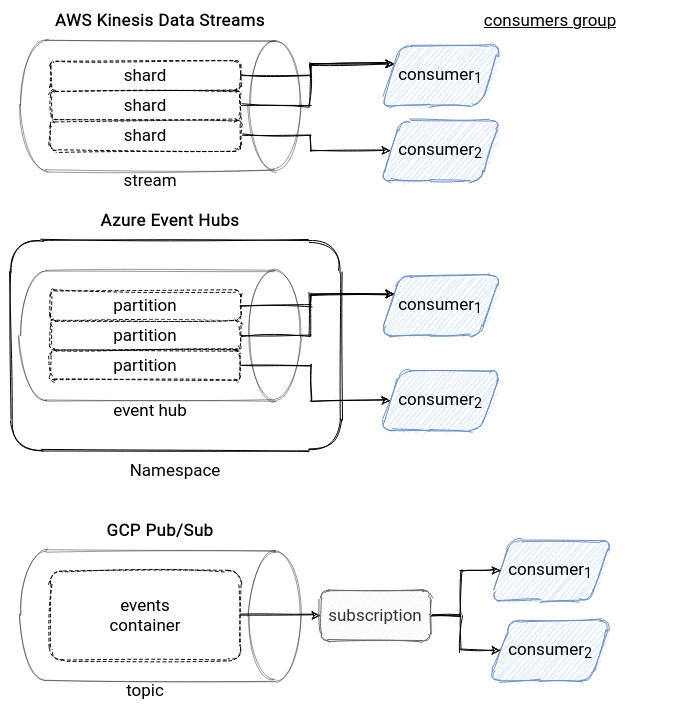
The architecture of Kinesis and Event Hubs looks similar. Both are the distributed append-only logs like Apache Kafka. Only the naming is different. In Kinesis, Kafka's topic is a stream, the partition is a shard, and the offsets are sequence numbers. In Event Hubs, you first create a namespace that has the same role of organizing resources as the namespace in Kubernetes. Inside this namespace, you create one or multiple Event Hubs sharing its throughput units. Every Event Hub has its name and number of partitions.
The comparison with Kafka is less evident for GCP Pub/Sub. Even though it uses the same abstraction to store the events - the topic - it's the single similarity. It doesn't expose any partitioning details to the consumers because all data delivery happens through subscriptions. The single-component, or rather a sub-component, based on the concept of the partition is Pub/Sub Lite - a cheaper version of Pub/Sub.
Due to the architectural differences, scaling all these streaming brokers is different. For Kinesis, you have to execute an operation called resharding that will add or remove shards. And you can't do everything since you can only set the new number of shards to ${current shards} * 2 or ${current shards} / 2. An important thing to notice, though. Kinesis has a reading and writing capacity per shard shared across all the consumers of this shard. Therefore, adding more shards doesn't necessarily mean that the consumers will process the data faster. To be sure that each of them uses the full capacity of the broker, you can configure the enhanced fan-out, which gives the full shard throughput to a single consumer.
Scaling Event Hubs is less obvious. Still, it's based on the number of partitions but is only possible for the Dedicated clusters configuration. If you don't have one and need to increase the throughput, you can play with the Throughput Units (TU) set at the namespace level. A single TU lets you read 1MB or 1000 events per second and write 2MB or 4096 events per second, whichever comes first. Hopefully, you can use an auto-inflate feature to scale these numbers automatically.
Among all of the 3 brokers, scaling in Pub/Sub was the biggest mystery for me. Unlike Kinesis and Event Hubs, it seems to work at the consumer's side. Since the concept of partitions doesn't exist in the public API, the recommended scaling strategy is to simply add new consumers to the subscription. Of course, as for two other brokers, Pub/Sub also has some quotas for the throughput which are 400MB/s or 100MB/s for pull reading, 20MB/s or 5MB/s for push reading, and 200MB/s or 50MB/s for writing.
You can find the summary for this section in the following schema:
Consumers
Regarding the consumers, all of the 3 brokers integrate pretty well with other services existing in the given cloud provider. That's why we'll try to see more general concepts in this section. Let's start with Pub/Sub this time since it's the last described in the previous section. The consumers are called subscribers because they connect to the subscription instead of the topic. They work in pull or push mode. The former one is similar to the one you know from Apache Kafka, i.e., the consumer issues a request to the broker. The push is an opposite mode where the broker sends the data to the consumer when there is something new to process.
In Kinesis, the consumers are organized in consumer groups associated with every stream. A group can have one or multiple workers which will process an independent subset of shards. The grouping is made with the property called application name.
Event Hubs also implements the concept of consumer groups. The workers are composed of processor instances working on the hub partitions. Their grouping is based on the consumer group parameter set whenever we initialize a new consumer.
Aside from the distributed reading, I was also wondering how these services handle not delivered messages without using any other service like AWS Lambda or Azure Functions. In other words, which of them support dead-letter pattern. At the broker level, only Pub/Sub supports it natively. If the consumer can't acknowledge the message within configured delivery attempts, the service will send it to the dead-letter topic. Don't get me wrong, you can also implement this pattern with Kinesis and Event Hubs as a data source, but the Pub/Sub's API seems to be the single one supporting it at the data source level.
To terminate, all of the consumers work in an at-least once semantic.
Producers
Regarding the producers, all of them support batches; i.e., they can send multiple events in a single request. And you can configure it with the definition of the max number of buffered records. Kinesis is a bit special in this field because it implements 2 batching modes. The collection mode is a classical batch approach where the producer sends multiple events in a single network request. The aggregation mode is slightly different because it aggregates all individual records to a single one delivered to the broker.
Regarding the partitioning feature, Kinesis and Event Hubs producers support the configuration of the partition key before delivering the data. In Pub/Sub, since it hides this partitioning concept, the producer can't define it. However, if you want to process a group of messages together (aka consumer affinity), you can set an ordering key to the produced messages and read them from a streaming pull mode.
Ordering key is related to another concept that we should have discussed in the previous section, ordering. As you can deduce, the ordering key in Pub/Sub guarantees an ordered delivery of the events; i.e., the consumer will read them in the same order as the broker got them. Does it exist for Kinesis or Event Hubs? Yes, because you can send the events one-by-one, in a fully synchronous manner; i.e., send it and wait for the broker's acknowledgment. However, as you can imagine, doing that will increase the latency because every record will be delivered in a separate request. And to guarantee a strict ordering in Pub/Sub, you will need to use a similar strategy which is explained in the documentation.
As you can notice, these 3 services serve the same purpose: scalable data ingestion and real-time processing. Despite an apparent similarity, they have some subtle differences in the architecture, auto-scaling and data generation. And I hope that this article shed some light on them.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- What's new on the cloud for data engineers - part 12 (10.2023-02.2024)
- Vertical autoscaling for data processing on the cloud
- What's new on the cloud for data engineers - part 11 (06-09.2023)
Last week I described serverless streaming services on AWS. Today, it's time to present streaming data sources on 3 major cloud providers, with a special focus on their architectures, producers and consumers ? https://t.co/oDJA30G9dF
— Bartosz Konieczny (@waitingforcode) May 23, 2021