
That's one of the biggest problems I've faced in my whole career. The development environment! I'm not talking here about creating cloud resources in different subscription but about the environment sharing similar characteristics to the production. In the blog post I'll share with you different strategies to put in place in the context of the cloud and streaming applications.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Unit and integration tests first!
Although the article covers different ways to run the code against the production data, it doesn't want to favor this approach over unit and integration tests. They still should be the first step in the testing strategy thanks to their ease of implementation and of maintenance compared to the strategies from the blog post. Thank you, Marcin, for the comments that made me realize this missing explanation!
The idea for this blog post came to me after a bad surprise I had when simply upgrading a dependency of a library. The unit tests executed correctly, the tests on staging as well, so there were nothing bad to happen. Wrong! The data volume on production was much higher than on staging and the new version of the library optimized data ingestion part which made the writes fail in random way.
Strategy 1- dev on production
That's the easiest one, but I'm not sure if your legal department will be happy. The idea is to allow all the development applications to read (AND only read!) the data from the production systems. Do you need to test a new version of your Structured Streaming job with real-world volumes? Or maybe you want to check how the new release of a data cleansing job will work with real-world data? No problem, simply deploy it with a good identity and test.
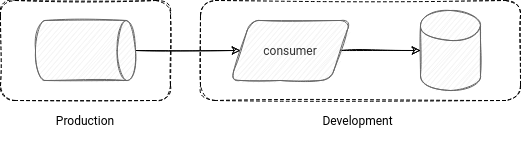
This strategy is easy to put in place but has some gotchas. First, your legal department may not be happy. Your development users will manipulate production data, so the real information about your consumers and business. And because the development environment is probably the most open environment in the project, they might want to minimize the risk of data leak and not accept such a solution. There is an alternative, though. It uses a data anonymization layer that will filter out all sensitive information:

It's a bit better now from the legal standpoint, but it doesn't protect against data leaks either. You can imagine that the production data got a new sensitive information field, and it took a few days before it got added to the anonymizer. Or worse, it didn't get implemented at all due to some communication issues! The anonymizer can mitigate that issue by explicitly choosing the attributes to synchronize. However, depending on the complexity of your input data, it can be difficult to set up.
Another problem with this dev-on-production strategy is the additional pressure on the production system. Knowing that cloud services have their limits like the maximal throughput for streaming brokers (AWS Kinesis Data Streams, Azure Event Hubs), connecting one or multiple extra consumers can have a negative impact on the stability of the production workloads.
There is a better way? It depends.
Strategy 2 - data generator
You can write your dedicated data generator and produce as much data as you need to test your system. It can be even more than in production! However, there is a hitch. How to generate this data? It won't always be an easy task. The complexity will be in the implementation details if you have good data governance represented by consistent input schemas. If not, besides the implementation effort, you will also need to find out how to maintain the generator consistent with the production data changes.
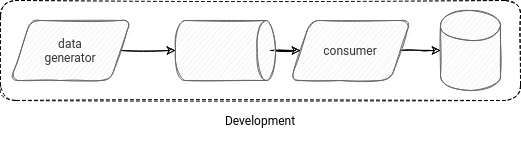
To generate the data, you have different choices. You can create a VM and rely on the multithreading programs. You can also represent the production data producers with serverless services like AWS Lambda, Azure Functions, or Cloud Functions, which could be triggered on-demand, run for a while, and stop to optimize the costs. By definition, they're cheap, and generating some data for dozens of minutes shouldn't cost you a fortune.
So the data generator is a better way because you have a full control over the generation process. You don't need to worry about data privacy issues and additional pressure on the production system. On the other hand, you get an extra component to maintain. And it's important to mention that this component doesn't capture the real production data, both from the volume and format standpoint.
Strategy 3 - dry run
We keep the production and development environments separated in this strategy. Instead, the idea is to deploy a resource on production that will:
- read the same input as the current version of the application - so that we don't worry about the volumes or schema differences
- write the processed data to a different sink to avoid duplicates - as long as we're not sure that the tested version works correctly, we can't write the processed data to the production database/table/topic. You can't expose "eventually" valid data to your end-users if you want them to trust you.
Once the candidate version is validated - either with some manual assertions or with automatic data quality checks - you simply "promote" it to production.
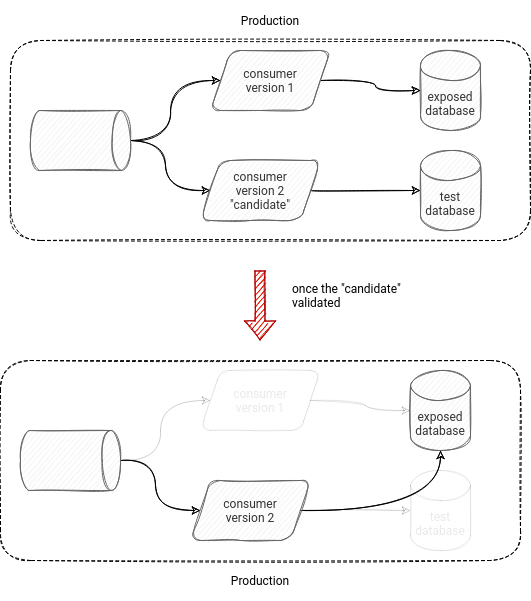
Is it shiny and rossy? Of course not! It has some extra manual steps like double deployment (first for test output, second for the final output). It may also require some flexibility on the job side. Hopefully, it's not complicated, but still, you will probably need to define your output as "mytable-testv2" instead of simply "mytable". Also, it may not work for all types of jobs. For example, if your job sends the data through an external HTTP endpoint and you would like to test whether the changes you've made didn't lead to errors on its side, the tests can be difficult to define.
Strategy 4 - canary deployment
Apart from the blue-green, there is another ops practice that we could employ in data systems, the canary deployment. The idea is to release an application incrementally to the end users. In our case, it could mean:
- deploying the job with 2 versions of the data processing logic - the "old" one and the "candidate" one
- starting by reading 5% of the input by the "candidate" and increasing this number every hour, as long as it doesn't reach the promotion threshold
- after reaching the threshold, you can remove the "old" logic and keep only the "candidate" one as the new final production version
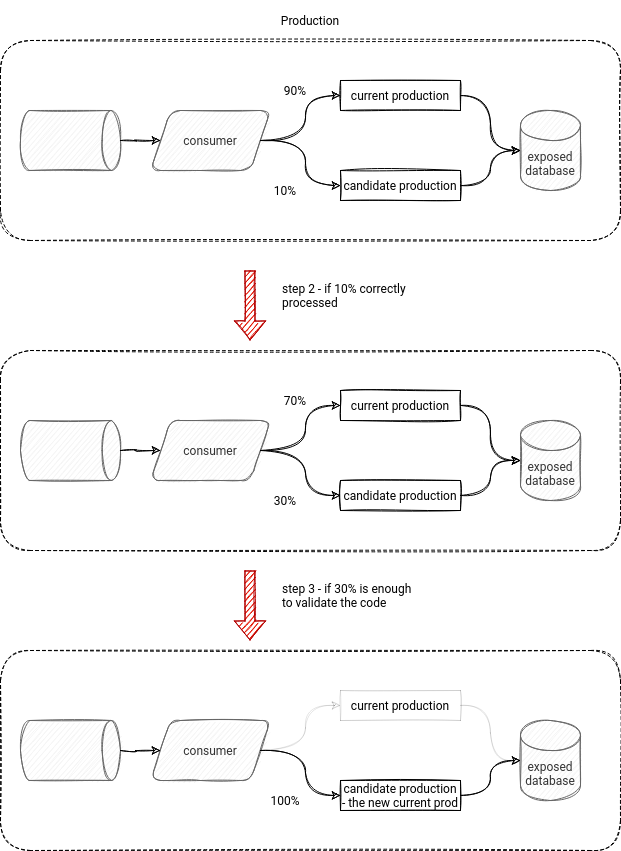
Once again, this approach is not all shiny and rosy. It eliminates the problem of testing HTTP endpoints, but what if the data generated by the new version was invalid? Also, defining 2 different versions working simultaneously can be challenging and may require some code duplication and effort than simply deploying the updated application.
To sum-up, there is no one-size-fits-all solution. Each of them has some pros and cons, and the decision will always belong to you and your team, and depend on the trade-offs you can make. I hope that the article can help you somehow in taking that decision, though!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- What's new on the cloud for data engineers - part 12 (10.2023-02.2024)
- Vertical autoscaling for data processing on the cloud
- What's new on the cloud for data engineers - part 11 (06-09.2023)
"Late blog posts", part 2. Testing Big Data streaming systems is hard. In the cloud blogging section I presented 4 different strategies and tried to apply them to create a dev environment similar to the production ? https://t.co/qii3ri1Dxw
— Bartosz Konieczny (@waitingforcode) December 20, 2021