
Recently I wrote posts about idempotent consumer pattern analyzing Apache Camel implementation and CDC applied on NoSQL stores. After that I had an idea, what happened if we would mix both of them?
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this post I will try to answer to that question. In the first section, I will present a big picture of the architecture to dedupe logs directly from a NoSQL storage. In the second part, I will write some code to test my idea on Apache Cassandra. At the end of the post, you will find a short summary of the advantages and drawbacks of the solution.
Big picture
The implementation of an idempotent consumer using CDC mechanism is straightforward. Or at least, so is the big picture. From one side we have a data producer which inserts new rows to some key-value store. Later in the schema, you can find a CDC agent and consumer which filters out already inserted rows (I suppose here that only insert operation is allowed on this data store). A schema summary would look like in the following picture:
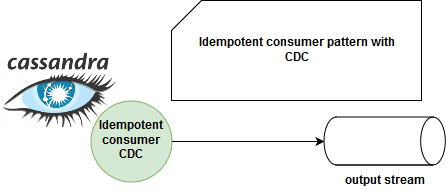
I already mentioned the first requirement of using INSERT operation. The second point is that it's about lightweight transactions, i.e. the use of IF NOT EXISTS operator in the insert clause. Even though it's much slower than classical INSERT, I didn't find another way to get rid of duplicated items at the CDC's consumer level. Btw, you will see in one of the next posts that it's quite possible to achieve with AWS DynamoDB streams.
Code - Apache Cassandra
To test the idea of Apache Cassandra idempotent consumer I will use Cassandra Cluster Manager tool. I will start by creating a single node cluster:
ccm remove cdc_cluster ccm create cdc_cluster -v 3.11.3 ccm populate -n 1 ccm node1 start
I will next create a keyspace, a table and add some data:
# ccm node1 cqlsh
CREATE KEYSPACE cdc_test WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1};
USE cdc_test;
CREATE TABLE orders (id int, amount double, first_order boolean, PRIMARY KEY(id)) WITH cdc=true;
INSERT INTO orders (id, amount, first_order) VALUES (1, 100, true) IF NOT EXISTS;
INSERT INTO orders (id, amount, first_order) VALUES (2, 100, false) IF NOT EXISTS;
INSERT INTO orders (id, amount, first_order) VALUES (3, 100, true) IF NOT EXISTS;
INSERT INTO orders (id, amount, first_order) VALUES (4, 100, false) IF NOT EXISTS;
INSERT INTO orders (id, amount, first_order) VALUES (5, 100, true) IF NOT EXISTS;
INSERT INTO orders (id, amount, first_order) VALUES (6, 100, false) IF NOT EXISTS;
INSERT INTO orders (id, amount, first_order) VALUES (7, 100, true) IF NOT EXISTS;
INSERT INTO orders (id, amount, first_order) VALUES (8, 100, false) IF NOT EXISTS;
# + cp commitlogs/* cdc_raw/ -r - if commit logs aren't moved to CDC dir automatically
Now it's time to start the idempotent consumer. For the sake of simplicity I only print the manipulated rows (complete code is available on gist):
public void handleMutation(Mutation mutation, int size, int entryLocation, CommitLogDescriptor commitLogDescriptor) {
for (PartitionUpdate partitionUpdate : mutation.getPartitionUpdates()) {
if (partitionUpdate.metadata().ksName.equals("cdc_test")) {
String rowKey = partitionUpdate.metadata().getKeyValidator().getString(partitionUpdate.partitionKey().getKey());
List<String> values = new ArrayList<>();
values.add(partitionUpdate.metadata().partitionKeyColumns().toString()+"="+rowKey);
partitionUpdate.unfilteredIterator().forEachRemaining(partitionRow -> {
Row row = partitionUpdate.getRow((Clustering) partitionRow.clustering());
Iterator<Cell> cells = row.cells().iterator();
Iterator<ColumnDefinition> columns = row.columns().iterator();
while (cells.hasNext() && columns.hasNext()) {
ColumnDefinition definition = columns.next();
Cell cell = cells.next();
values.add(definition.name.toString()+"="+definition.type.getString(cell.value()));
}
System.out.println("Got new row="+values);
});
}
}
}
In the output you should be able to find the following messages:
Processing mutation cdc_test; orders Got new row=[[id]=6, amount=100.0, first_order=false] Processing mutation cdc_test; orders Got new row=[[id]=7, amount=100.0, first_order=true] Processing mutation cdc_test; orders Got new row=[[id]=8, amount=100.0, first_order=false]
The single point to note is that for an unknown reason, the data was not flushed to CDC directory on my localhost. I had to listen for commit logs director instead. If you have some clue, you're welcome to post it in the comment (nodetool flush didn't work, nodetool drain did but it stopped the node every time :/).
Wrap-up
To sum up, let's start by good points of the experience. First, the data store provides a way to not consume records added multiple times. In the architecture presented in idempotent consumer pattern post, the data store is only a long-term storage for already processed keys. Here, it's automatically used to prevent duplicates. It achieves that by enforcing (by convention though!) IF NOT EXISTS inserts on the producer side. Hence, no more need for extra lookups that at scale can be costly.
On the other side, the idempotent consumer is here coupled to the database. It enables fast data access from the shared disk but on the other side it can be difficult to scale and automatize.
Another thing to consider, maybe the most important one, is replication. Generally, replication helps to ensure fault-tolerance but in this particular case, it will be problematic. Since we'll need to deploy our listeners on every node, we'll automatically consume duplicated messages from replicated data. If the goal of the idempotent consumer is to send the rows to some other storage, we can end up with an extra deduplication layer which is ... something we're trying to avoid !
The goal of this post was not to convince to implement your idempotent consumers with Apache Cassandra and CDC pattern. Throughout the simple application and some words of summary, I wanted to show how it could be implemented and why you probably won't use it on production (unless you have a smart way to handle file watchers on replicas?). Fortunately, the issues discovered during this post have already been addressed elsewhere. You will discover this in the next post where I will implement an idempotent consumer directly from DynamoDB...Streams. And for more information about CDC in Apache Cassandra I recommend you "Cassandra to Kafka data pipeline Part 2" post which gives the clearest explanation of the feature I could find.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Change Data Capture and Apache Cassandra idempotent consumer here:
- Using lightweight transactions Cassandra: How to know if operation was insert or update Cassandra to Kafka data pipeline Part 2
Related blog posts:
#CDC and #ApacheCassandra ? In the second post of this week I check whether this database is a good candidate for streaming data with native CDC option (spoiler alert ⚠️: not really) https://t.co/Ne0YcLMYQH
— Bartosz Konieczny (@waitingforcode) June 27, 2019