
Idempotence is something I appreciate, maybe the most, in data engineering. If you write an idempotent logic you don't need to worry when your logic is reprocessed. You don't need to worry that it will generate duplicates or inconsistent results between runs. However, using it is not always easy and I'm actively looking for all related patterns to it. This time I will focus on idempotent consumer implementation in Apache Camel. Even though it may sounds old-school with modern streaming and messaging solutions, it's a good solution to know.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In 3 parts of this post I will try to focus on the idempotent consumer implementation in Apache Camel. In the 2 first parts, I will detail the logic and some major implementation details. In the last part, I will show how to integrate Apache Camel's model in Apache Spark.
Not a perfect solution
Of course, whenever you can, you should use any built-in mechanism provided by your message or data store. For instance, Apache Kafka comes with 2 solutions. The first one are transactions to guarantee exactly once processing between producers and consumers. The second one is enable.idempotence parameter which defines whether the broker should keep track of already received events and, therefore, dedupe the messages in your place. It should work quite good for Kafka-to-Kafka processing.
Another point is that the solution discussed here can end up by introducing duplicates. Even if you use the kind of 2 phase commit approach, the confirmation message after a successful processing can still not reach the message store.
But if you are able to accept this risk which, depending on the availability of your message store will be lower or bigger, and your streaming broker doesn't come with built-in deduplication mechanism, the proposed approach from Apache Camel can be a good fit. If you are curious about the alternatives (still under the same constraints), I will publish 2 other posts about idempotent consumers next weeks.
I wrote all of that just to emphasize the fact that the easiest way to guarantee idempotence is to simply write an idempotent logic. Even if you receive given event multiple times, you'll always generate the same output or action.
Idempotent consumer explained
The role of an idempotent consumer consists of filtering out already seen and processed events. If you think about your data pipeline in real-time categories, you will certainly see a few places where duplicates may occur. The most visible one will be your producers which, in case of any error, may retry to send you the data that can be already consumed by the readers (at-least once semantic here). But let's leave this almost perfect world for the moment and think about the case where your producers had a bug and delivered you only a half of records. In that case, you want to integrate missing data in your pipeline but you don't want to include duplicates. An idempotent consumer, the one who reads the data sent by the producers, is a good pattern to use here.
In its simplest format, the idempotent consumer could be written as follows:
event_id = generate_event_id(event) if event_id not in processed: # process the message else: # do nothing
The processed from this snippet may be a lot of things. You can keep it local and store a map of already seen records in memory. But you risk losing everything if your data processor restarts on a different node or if the data is not always partitioned the same way. In the latter case, the same record may arrive at 2 different processors and not be detected as duplicate. A better idea is to use a more persistent and distributed data store, like in the following schema:
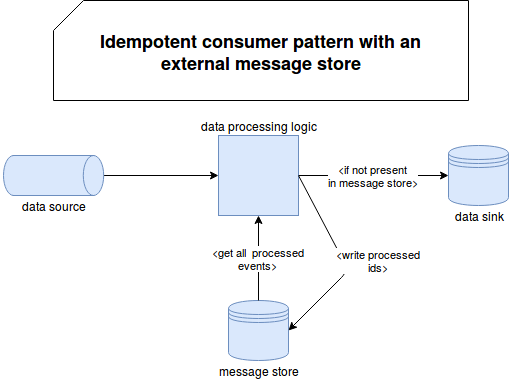
However, this snippet has some important points to discuss. First of them is scalability. Imagine that you are processing hundreds of thousands of events. Doing the check unitary would be overkill and instead of having low latency streaming you would end up with much slower semantic. To overcome this, you can use batch queries which alongside with a memory-first distributed store like Redis should improve the latency.
Another problem with the above condition is delivery semantic. The place where you check out the not processed event defines whether you risk having duplicates or whether you lose some data. If you decide to materialize that information just before the processing code, you may lose the events if its processing fails. On the other side, if you do it at the end and the materialization fails, you may end up with duplicates if the same message is sent again. To overcome this drawback, I will detail it more in the next part, Apache Camel sometimes uses a kind of 2 phase commit.
This behavior, consisting on checking whether given event was already processed or not, is called in the literature inconsistency detection. You should also know that there is another solution called idempotent semantic where your application is able to deal with duplicates, either by deduping them before processing (e.g. for grouped events) or simply because calling it multiple times for the same input always generates the same output.
Idempotent consumer in Apache Camel
Apache Camel's idempotent consumer is implemented in org.apache.camel.processor.idempotent.IdempotentConsumer class. The processing logic is straightforward. The first step consists on calculating the id of the message that will be used to dedupe.
Just after the id resolution, one of 2 things may happen. If the consumer is configured eagerly, it will first persist the id of the processed message in the message store which in Apache Camel is called repository, and check whether the record is already present. For lazy configuration, it will only do the check. If the processed event is seen for the first time, the consumer will process it and at the end write the id to the message store.
Now, depending on the outcome of the processing, the consumer will either call a callback function for failure or for successful execution. In the former case, the consumer will remove the key from the message store. In the latter case, it will save it into the store and, depending on the implementation, confirm the key. Confirmation is only a boolean flag saying whether the processing logic fully completed. It's only implemented in some message stores like Hazelcast's one.
Simplified, the logic can be then written as:
event_id = generate_event_id(event)
if event_id not in message_store:
try:
process(event)
message_store.save_id(event_id)
except:
message_store.remove_id(event_id)
Idempotent consumer in Apache Spark SQL
In this section I will try to implement similar mechanism with Apache Spark SQL module against a simple in-memory representation of message store:
class IdempotentConsumerTest extends FlatSpec with Matchers {
"an idempotent consumer" should "skip already read events" in {
// I'm using here a batch processing for its simpler semantic for this example
val sparkSession = SparkSession.builder().appName("Spark SQL idempotent consumer test").master("local[*]")
.getOrCreate()
import sparkSession.implicits._
val events = Seq(
IdempotentConsumerEvent(1, "2019-05-01T10:00"), IdempotentConsumerEvent(1, "2019-05-01T10:00"),
IdempotentConsumerEvent(1, "2019-05-01T10:00"), IdempotentConsumerEvent(2, "2019-05-01T10:00"),
IdempotentConsumerEvent(3, "2019-05-01T10:00"), IdempotentConsumerEvent(3, "2019-05-01T10:00"),
IdempotentConsumerEvent(4, "2019-05-01T10:00"), IdempotentConsumerEvent(5, "2019-05-01T10:00")
).toDF
events.map(row => IdentifiedIdempotentConsumerEven(IdempotentConsumerRowMapper.id(row), user(row), dateTime(row)))
// Semantically I'm not using groupByKey because I don't want to create groups. Rather than that I want all events
// with the same key on the same node to create groups of ids to query instead of querying them 1 by 1
.repartitionByRange($"id")
.mapPartitions(rows => {
rows.grouped(100)
.flatMap(groupedRows => {
// Here 2 choices:
// - using .hashCode() - not a lot of work but you're generating the id on all columns
// - custom algorithm - more work but also more control
// I chosen the latter one.
val eventsIds = groupedRows.map(event => event.id)
val alreadyProcessedIds = MessageStore.getRowsForIds(eventsIds).toSet
val notProcessedEvents = groupedRows.filter(event => !alreadyProcessedIds.contains(event.id))
notProcessedEvents.distinct
})
})
.foreachPartition(notProcessedEvents => {
val materializedEvents = notProcessedEvents.toSeq
val eventsIds = materializedEvents.map(event => event.id)
try {
// do something with the events here
// I'm using a big batch but maybe you can opt for micro-batches built
// with Scala's .grouped(...)
MessageStore.persist(eventsIds)
} catch {
case NonFatal(e) => {
MessageStore.remove(eventsIds)
throw e
}
}
})
MessageStore.newPersistedIds should have size 4
MessageStore.newPersistedIds should contain allOf (-1660704958, -220168171, -209817447, -96024353)
}
}
case class IdempotentConsumerEvent(user: Int, dateTime: String)
case class IdentifiedIdempotentConsumerEven(id: Int, user: Int, dateTime: String)
object IdempotentConsumerRowMapper {
def user(row: Row): Int = row.getAs[Int]("user")
def dateTime(row: Row): String = row.getAs[String]("dateTime")
def id(row: Row): Int = MurmurHash3.stringHash(s"${user(row)}_${dateTime(row)}")
}
object MessageStore {
// For now only the event corresponding to user=1 is considered as processed
private val ids = Seq[Int](-284117173)
private var newIds = Seq[Int]()
def newPersistedIds = newIds
def getRowsForIds(idsToCheck: Iterable[Int]): Seq[Int] = {
ids.intersect(idsToCheck.toSeq)
}
def persist(newIdsToPersist: Seq[Int]) = {
newIds ++= newIdsToPersist
}
def remove(ids: Seq[Int]): Unit = {
newIds = newIds.diff(ids)
}
}
Of course, it's only one of the different ways to deal with duplicates in Apache Spark. Here I gave an example of batch processing, just for the sake of simplicity. But you will deal with the idempotent consumer at streaming level as well. In this context, you can also use Apache Spark Structured Streaming state. Unlike message store, it's more volatile, unless you want to store all processed keys which will be costly. It's then more adapted to the situations where you are sure to not reinject past data in your pipeline and you can keep the dedupe logic during a shorter period of time like few hours. This solution will perform poorly if, for instance, you will want to reinject some missed events one or 2 weeks after. Probably you will not persist all processed keys from last 2 weeks in the state, and therefore introduce duplicates in the stream.
For message store-based solution, a good practice is to use automatic TTL. Thanks to that you won't need to worry about the space and let the data store to clean too old records by itself. Among the solutions I know, Apache Cassandra and AWS DynamoDB offer this feature. Of course, TTL value will drive your deduplication policy (like the example from previous chapter with 2 weeks old reinjected data) but in most of the cases, you won't need to store the history of all seen records ever. And having fewer data will increase the throughput and reduce the costs as well.
Idempotence is a property that will help to keep data pipelines simple and resilient. However, it's not always easy to implement. As shown in this post, one of the possibilities is an idempotent consumer which, even though sometimes may process duplicates, will fit well for a lot of different use cases. Of course, if you have a choice, you should always prefer much stronger and, among others, built-in semantic like Apache Kafka exactly once delivery.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Idempotent consumer pattern here:
- Idempotent consumer Idemotency patterns (Un) Reliability in messaging: idempotency and de-duplication Cloud Computing Patterns: Fundamentals to Design, Build, and Manage Cloud Applications HazelcastIdempotentRepository Enabling Exactly Once in Kafka Streams
Related blog posts:
- Idempotent consumer with AWS DynamoDB streams
- Change Data Capture and Apache Cassandra idempotent consumer
Idempotent data processing logic is not always easy to write. In today's post I'm focusing on the implementation of idempotent consumer pattern in #ApacheCamel with the help of a message store https://t.co/Et7ADUe12C
— Bartosz Konieczny (@waitingforcode) June 21, 2019