
The first "reverse" term I've ever encountered in programming was reverse proxy. Since then, I've seen passing "reverse engineering", "reverse iterator", but none of them was a pure data term. Until recently, when I heard about reverse ETL.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Reverse ETL solves the problem of making data available in specialized systems, mostly used in the operational analytics domain. In a more human-friendly tone, it takes the data you import to your data warehouse/gold tables layer and moves it to the systems dedicated to growth marketing, sales support, or customer management. In the picture below, you can see a process exporting the sales information to some 3rd party sales support system:
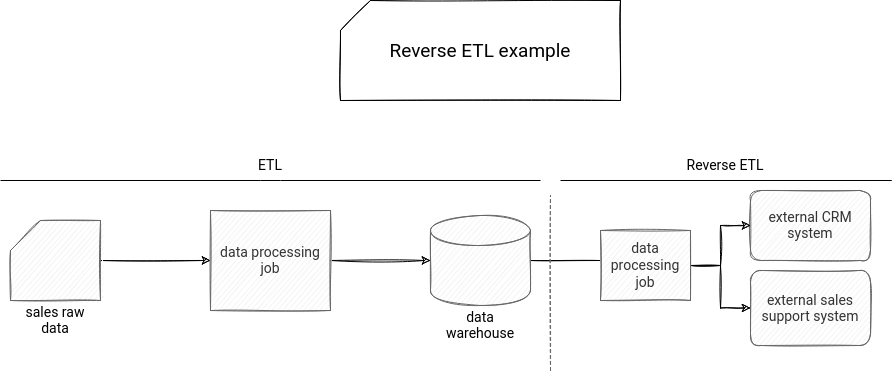
The reasons to move the data outside your ecosystem vary. Among the key ones you will find:
- taking advantage of SaaS - if you need to send some invoices to the customers, there is no need to write an invoicing system. Simply export what you need to some 3rd party provider and let it do the job for you
- operational analytics - not all business users know SQL. Operational analytics brings the data to the business-specialized systems that don't require any technical knowledge.
How to implement this reverse ETL? If we consider this process like any data processing step, the implementation is a simple data processing job reading the data warehouse/gold table data and importing it to the operational system. Very often, this job will use the APIs exposed by this system. The throughput can also be limited, so you may need to implement a resilient retry strategy. Besides the custom solutions, you will also find 3rd party reverse ETL tools. Unfortunately, I didn't find any Open Source library, so your comment is more than welcome if you know one! Thank you, Kurt, for sharing Grouparoo as an Open Source example.
On some cloud providers you'll be able to connect your data warehouse/golden table layer to 3rd party business tools managed by these providers. For example, GCP BigQuery is a natively supported data source for Google Analytics.
In a nutshell, reverse ETL is a way to operationalize the data warehouse/gold tables layer. Technically, it consists of loading the data to often 3rd party systems heavily used by the business users who do not necessarily master SQL (= so they can't directly use your last data layer).
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Reverse ETL here:
- ‘Reverse ETL’ Can Help Companies Operationalize Data Warehouses How Datadog Operationalizes Their Data Warehouse to Supercharge Their Business Teams Reverse ETL on Airflow What is Reverse ETL: A Definition & Why It's Taking Off
Related blog posts:
- Useful classes for data engineers - Scala and Java
- ACID file formats - file system layout
- ACID file formats - API
ETL, ELT, EL - OK, but reverse ETL?! I heard about this term a few months ago for the first time and recently did some research to know more. The result is there ? https://t.co/z89O7Nww0I
— Bartosz Konieczny (@waitingforcode) January 9, 2022