
We all know more or less how to manage code for data processing jobs, either in Python, Scala, or Java. But oftentimes those jobs operate on other resources such as Delta Lake tables, or row files, that may not follow the same management rules.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this blog post we're going to explore how to manage Unity Catalog tables on Databricks. We're going to see three different repository organizations possible, hoping to help you choose the right one for your projects!
Monorepo job-based
I'm deliberately starting with the one I'm at least in favor of. A single Git repository where you declare data processing jobs that directly create and evolve tables with operations like saveAsTable in PySpark. The single advantage I've found so far for this approach is the simplicity. Simplicity because you don't need to bring another technology to manage your tables. Instead, you use all the well known constructs to deal with table lifecycle.
Unfortunately, this simplicity makes all other things worse. You don't have a clear separation of concerns between the data and metadata (schema) generation. Updates won't be easy and might need some custom code. Even a simple change of a schema may require data reprocessing which obviously will cost you time and money.
Second, you may need to use some less obvious options for schema manipulation or resources creation such as imperative mode instead of the declarative one. Although it doesn't sound like a big deal, most of the time it will be easier to declare static things than coding them with SQL operations or PySpark API.
Monorepo jobs and DDL-based
An alternative to the mono-repo and job-based splits the job and schema manipulation parts into two tasks in the same job. Here each job starts with a task manipulating the schema and as soon as it succeeds, the data processing kicks off.
It's a more solid alternative to the first approach because it provides a clear separation that you can easily materialize in your code base. It also lets some flexibility in case of schema changes where, for example, with an if-else conditional task you could decide to skip the data processing task if you had only the schema to evolve. Below you can find a high-level design for that:

It might be sufficient for you if you don't want to invest time and energy to bring even more declarative solution to your Databricks projects with Infrastructure as Code (IaC) tools like Terraform.
Mono-repo IaC-based
In another alternative scenario, you leverage a technical separation for the data and metadata (schemas) management. The data remains managed by Lakeflow jobs but it's not valid anymore for the Unity Catalog layer owned by the given data project. You delegate this UC responsibility to the CI/CD pipeline that is the typical place to integrate an IaC stack. Overall, the change would translate into two physically separated - because of two different technologies used - layers:
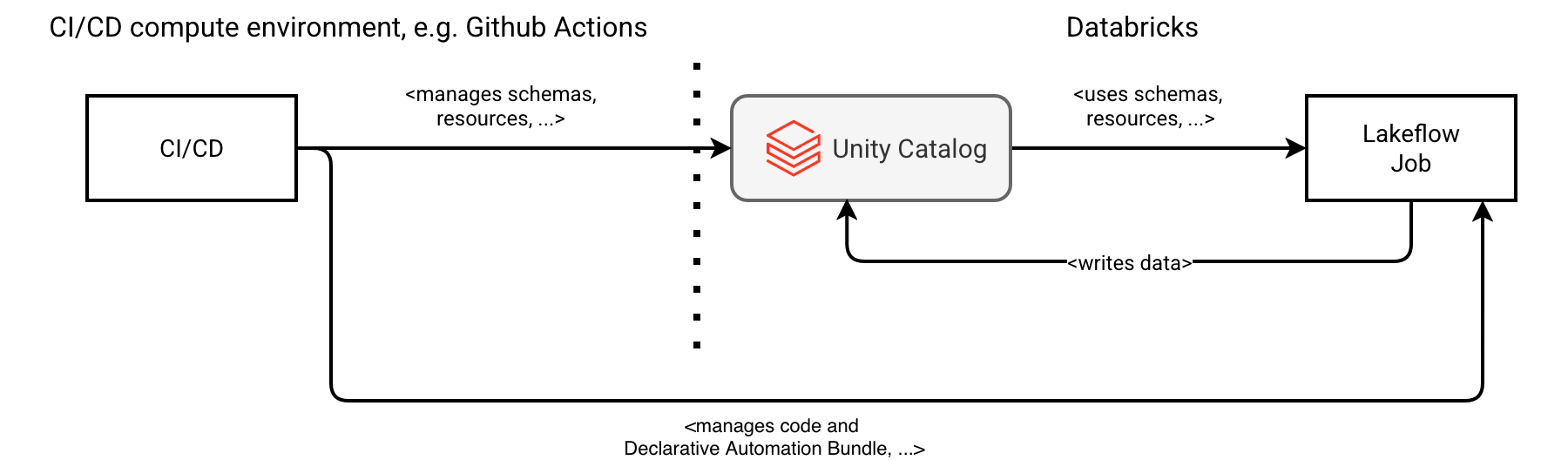
An important point here is the coupling of the Unity Catalog resources managed by the CI/CD and the deployed Lakeflow resources. The idea is to imitate the dependency from the previous example but with a real declarative solution. Just take a look how to declare Unity Catalog tables with Terraform:
# Example from the doc: https://registry.terraform.io/providers/databricks/databricks/latest/docs/resources/sql_table#example-usage
# Version 1.116.0
resource "databricks_sql_table" "thing" {
provider = databricks.workspace
name = "quickstart_table"
catalog_name = databricks_catalog.sandbox.name
schema_name = databricks_schema.things.name
table_type = "MANAGED"
column {
name = "id"
type = "int"
}
column {
name = "name"
type = "string"
comment = "name of thing"
}
comment = "this table is managed by terraform"
}
Besides calling terraform plan and terraform apply, you don't have anything else to code. Databricks provider will be in charge of the communication with the Databricks API.
Main-repo Unity Catalog
The opposite to the mono-repo solution with both Unity Catalog and job resources declared in a single place, possibly with technological separation, is the main repo with all Unity Catalog definitions. Here nothing changes to the usual workflow where a Git project manages Lakeflow resources. The project can still handle your data processing logic only because all the Unity Catalog work - including your data project's scoped resources such as tables or volumes - are fully managed in a dedicated repo.
The dedicated repo is either a dedicated Databricks job running schema management libraries like Flyway, or a CI/CD pipeline, like in the next schema:
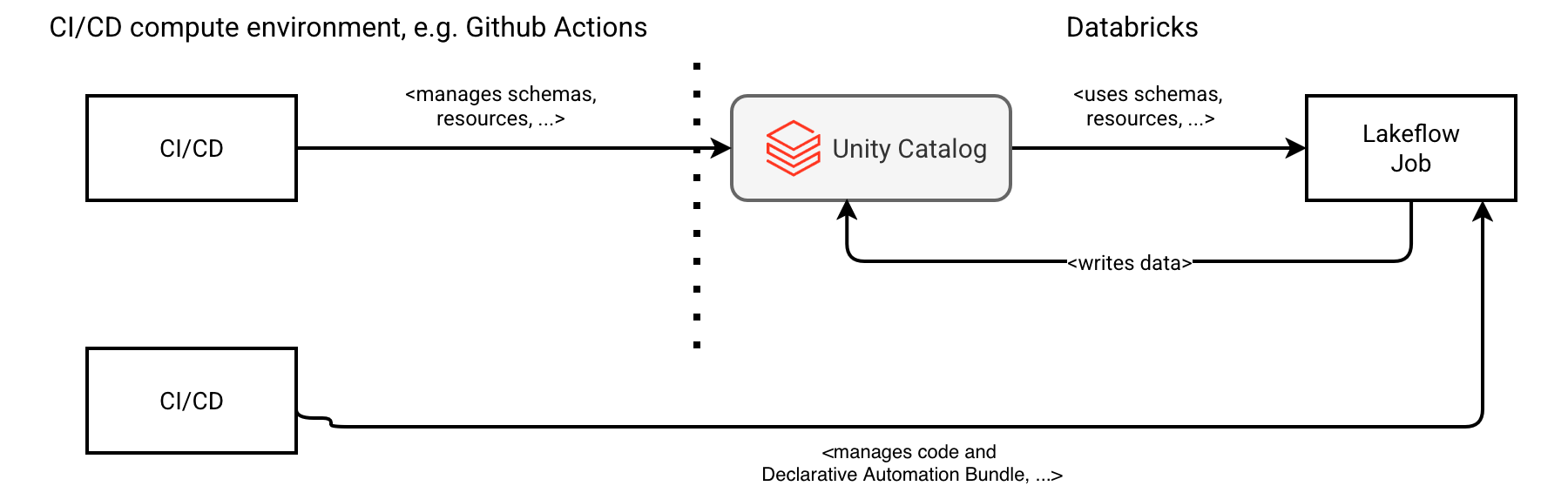
The dedicated repo brings a single source of truth. You won't risk that another project overwrites your changes; Technically all changes are visible with the terraform plan but sometimes people may simple miss them and make some concurrent changes on your resources - for that reason the scope separation is also important that may lead to managing shared resources such as schemas, or credentials, in a dedicated UC repo and other, project-local items like tables or volumes, in a mono-repo approach.
Decision tree
If you are looking for some free hints on how to organize that part, here is a simplified decision tree that takes a few important aspects into account: team skills, platform team support, and upskilling capabilities. I might call some of those approaches best practices or the ways to go, but ultimately there will always be a team of people responsible for the project. And those people won't be the same in each organization, or even in different departments within the same organization. Sure, AI simplifies here a lot but it will not replace people's willings.
My recommendation would be to go with an IaC tool, either native or templated where you could define the schemas as YAMLs or JSONs for less technical uses (you will need one tech guy to set up the IaC abstraction, though). So, if you can rely on ops people to make it work, that's great because your resources management will be fully declarative, as per Terraform code you just saw.
If you can't count on your ops colleagues, that in some team setups are imaginary, then you will unlikely check for one of the first two approaches. The first one where you manage UC resources directly in the code is a bit messy since you mix data processing and resources, making the day-to-day usage challenging, e.g. when you want to only trigger the resources update, you will either have to write a custom logic to skip the processing, or reprocess the data. Moreover, you can't separate the compute type. For those reasons the solution with a dedicated DDL task is far better. IMO, it's still less optimized than the fully declarative IaC-based solution, but at least it provides a separation that helps understand what's going on and also, operate the stack on a daily basis.
Unity Catalog is incredibly powerful, but getting the management layer right takes time (and a few headaches). If your organization is hitting a wall with this or similar data engineering challenges, you don't have to figure it out alone. Reach out at contact@waitingforcode.com. Let's jump on a call, look at your architecture, and get your data governance sorted out together!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩