
If you hear "agile", "adapted to the changes", you certainly think about Scrum, Kanban and generally the Agile methodology. And you're correct but it's worth knowing that the agile term also applies to the data. More exactly, to the data modeling with the approach called Data Vault.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The article starts by explaining the whys of this approach. Later, you can learn about the main components and, finally, see one specific example modeled with the data vault. Please notice, the article presents the first version of the approach. A follow-up blog post will discuss the 2.0 release. Also, keep in mind that Data Vault is not only about modeling. Modeling is one of the pillars of the approach and it will be the single one covered here.
Why Data Vault?
Even though Data Vault is quite old regarding the technologies used today (even older than Hadoop MapReduce since it was proposed in 2000 by Daniel Linstedt!), it addresses the problems you may face today. First, the change is the single thing you can be sure about in the data systems. A new business requirement, a new data to expose in the dashboard, a new dataset to integrate into the ML dataset, ... those are only a few examples of what can change. Data Vault, thanks to the isolated modeling approach, enables quite flexible and easy evolution of the schema in the data warehouse.
Apart from that, Data Vault also addresses the cleansing requirement, and more generally, the concept of "good" and "bad" data. Data Vault doesn't judge the data; instead, it considers all records as relevant and leaves the usability decision to the end-users. Why that controversial approach? After all, the end-users always want to have a valid dataset. The principle of Data Vault, and generally of agility, is the ability to adapt to the changing world. And if you get rid of some data at some point in the past, you will not be able to use it in the future when, for example, the business requirements will change. Of course, nowadays, thanks to Data Lake or lakehouse paradigm, you can always bring data back, but at the time when Data Vault was proposed, it was not so obvious.
Another problem Data Vault addresses is the complexity of data systems. Often you will have to integrate the data from different providers, with different latencies, and all this may lead to quite complex schemas and an architecture difficult to maintain. In the next section, you will see the Data Vault components, but mainly thanks to a clear distinction of them and the lack of the preprocessing rules due to the traceability requirement, the complexity issue can be addressed with a modeling pattern composed of:
- Hubs and business keys identification
- Identification of the relationships between hubs
- Description of the hubs
- Preparation of the data for exposition in data marts
The traceability is another point characterizing Data Vault. All data is stored and so in the raw format. It also enables flexibility since any change can be easily implemented without prior reprocessing of all data like it could happen in other modeling techniques.
Components
To enable all of the points presented before, Data Vault uses 3 main component types. The first type of them is hub. It contains only the business key and data source. Additionally, you can add some metadata describing the loading context (who, when, etc.) and a new hub key. It's important to use business information as the business key to avoid any problems with loading the data from different data sources that may have different "technical" ids like UUIDs, numbers, hashes, etc.
You can see then that the hub contains only a few keys and traceability information. But where is the data located? The hub parameters are called context and are stored in the tables of satellite type. Every hub can have one or more satellites, and all of them are built by the area of interest. You need to store a customer address and customer information (id, register date)? In Data Vault, since these two represent 2 different areas, they will be stored in 2 different satellite tables. Satellite tables can also be associated with the next component called links. An important characteristic of satellites is their time-based character. Apart from the business, key and source information, you will find there 2 columns to indicate the validity period of the specific row, in case it could be overwritten.
Links are here to create relationships between the hubs. The link will then contain the keys of hub tables, the source record information and, eventually, a key for the link and the audit information.
Example
To see an example of Data Vault modeling, let's take a use case of an e-commerce store. According to the first section's approach, the first step to make is to identify the hubs alongside the business keys. After the first iteration, you certainly identified the customer, product, order, category hubs. There is more but let's keep this example easy to understand. For the same reason, let's say the business keys are already located with the data and they're simple numerical values.
The next step is the identification of the relationships. You will certainly have the links for: the customer and the order, the order and the product, and the product and the category.
For the description part detection, it's about the satellite identification. Logically, all hubs will have at least one satellite because "hubs without satellites usually indicate "bad source data", or poorly defined source data, or business keys that are missing valuable metadata"
(v1.0.8 Data Vault specification).
Easy? Not really because there is a problematic case in satellites detection. A satellite is potentially mutable data describing the hub (hence the validity period columns). The delivery address will be then a satellite or a hub linked to the order? If there would be only 1 active address at a time, it could be considered as a customer's satellite because the address is one of the descriptions of the customer's concept. But it's not the case. A customer can order different products and deliver them to different places. Moreover, this delivery address can be shared with other hubs like shippers and since it's not possible to link a satellite into multiple hubs, there is another reason why the delivery address deserves to be a hub (FYI I didn't invent it, there is a blog post by Remco Broekmans explaining that; you'll also find some proofs in the specification).
Apart from the data modeling, there is also an essential part of the conventions. Data Vault has its own set of conventions like prefixing or suffixing hubs, satellites and links, using the same prefix or suffix for a date or time-based fields. The full specification is online, but you should remember that for any project - the conventions help to keep it consistent and the consistency helps to maintain it easier.
Overall, the Data Vault model for the discussed but limited, e-commerce case, will look like:
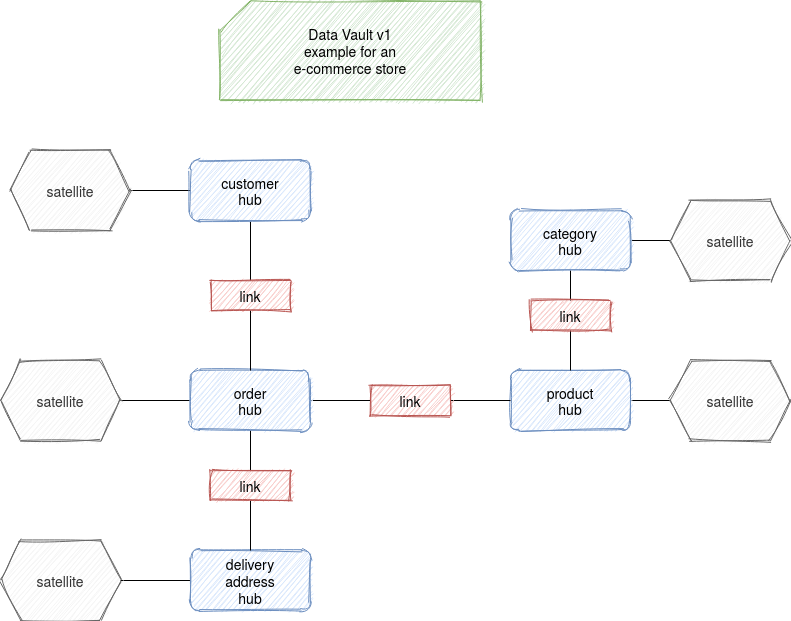
Data Vault is an extensible modeling approach that can be used to expose the data to the end-users from business-specific data marts. All information presented in this post is mostly related to the 1st version of the specification. But there is a 2nd one, adapted to the NoSQL and Big Data world. And you will read about it next month.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Data modeling with Data Vault - part 1 here:
- Data vault modeling What is "The Data Vault" and why do we need it? How to model "Address" in Data Vault Data Vault v1.0.8
Related blog posts:
A common point between Agile and data modeling? Data Vault! The first of 2 posts presenting this approach is online.
— Bartosz Konieczny (@waitingforcode) December 6, 2020
? https://t.co/lwaom6MyW0