
In the previous blog post you discovered the first version of Data Vault methodology. But since the very first iteration, the specification evolved and a few years ago a version 2 was proposed. More adapted to the Big Data world, with several deprecation notes, and more examples adapted to the constantly evolving data world.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this post, you will discover more details about the Data Vault methodology. In the first part, you will see the hubs, links, satellites, and tables as the main building blocks for modeling the approach. In the second part, you will see how the keys are managed. In the 3rd part, you will see how this new specification addresses modern data problems, whereas, in the last part, you will discover an example of the architecture involving Data Vault.
Hubs, links, satellites and tables
The first part, hubs, are a quite clear concept. ,hey are a list of business keys. An important thing to highlight, and you will see it in the specification, is that the hub doesn't require surrogate keys, in any (hash or sequence) format.
The links are there to represent the relationships, but what it's maybe not clear is that the relationship can be between 2 or more business keys, so presumably between multiple hubs. They never contain validity dates. Different types of such links exist:
- hierarchical link that represents hierarchies inside the same hub. An example of that hierarchy can be a hierarchy of product categories
- same-as link helps to solve the data quality issues problem where a given concept can be misspelled and has to be linked to the correct definition. An example of this fuzzy matching modeling can be zip codes written in different formats (e.g., 00000 or 00-000)
- non-historized link that is perfectly adapted to the immutable facts, so something that happened in the past can neither be undone nor modified. And since the changes will never happen, they don't need to be stored in the satellites.
- exploration links is a standard link created from business rules, so it can be easily discarded without affecting the auditability. The official specification calls it also a Deep Learning link because it can give confidence for the prediction and strength for the correlation of 2 datasets, but if we stay with these 2 columns, we could also try to use it to model a result of the ML recommendation system between a user and an item. The link would then specify how possible it is that the user will like the product. Here, the link is mutable since the prediction can change or even be discarded if the algorithm detects other user preferences changes. (it's only a proposition for my understanding of the specification, if you feel it's wrong and that only Deep Learning models can benefit from the exploration links, please comment and explain why 🙏)
The next type of components are satellites. They contain descriptive data for the hubs or links. The data they store may change over time. That's why they contain an effectivity column indicating the time when the given record is valid. There are 3 types of satellites:
- multi-active satellite - in this satellite given hub or link entity has multiple active values. For example, it can be the case of a phone number that can be professional pr personnel, and both may be active at a given moment.
- effectivity satellite - a descriptive record that is valid (effective) only for some specific period of time. You will there the start and end dates and an example of it can be an external contractor working in a company in different periods.
- system-driven satellite - mutable, created from hard business rules (data-type rules, like enforcing integer type; not involving pure business rules like classifying a revenue as poor or rich category of people) for performance purposes. The examples of these satellites are the point-in-time table (PIT) and bridge table, presented in the next paragraph.
In addition to these 3 main building blocks, in Data Vault you'll retrieve the tables, all for different purposes:
- point-in-time table - represents multiple satellite tables in one. But the idea is not to copy any of the context values but only their load dates. For example, if a hub has 3 different satellites, satA, satB and satC, a point-in-time table will store the most recent load date for every satellite and so for every business key. So the stored data will be built like (business key [BK] from the hub, MAX(loadDate from satA for BK), MAX(loadDate from satB for the BK),MAX(loadDate from satC for BK)
- bridge table - similar to the PIT tables, bridge tables are also the tables designed with the performance in mind. But unlike a PIT table, a bridge table will only store the business keys from the hubs and links. If you are familiar with the star schema, you will see some similarities between bridge and fact tables. The difference is that the bridge stores only the keys, whereas the fact will also store the measures. A single accepted value in the bridge tables are aggregations computed at runtime. Together with PIT table, the bride is considered as a query-assist structure.
- reference table - they are present to avoid data storage redundancy for the values used a lot. For example, a satellite can store a product category code instead of denormalizing the whole relationship, so bring the category description, full name to the satellite itself, and use the reference table to retrieve this information when needed. The reference tables are built from the satellite, hub or links values entities but are often used only by the satellites since they're the most "descriptive" part of the data vault modeling.
- staging table - exactly like a staging area, staging tables are temporary structures used to improve the load experience. They can also provide the Data Vault features if the raw data's loading process to the data warehouse storage doesn't support them. More exactly, you will find there a staging table and a second-level staging table that will load the raw data from the staging table and add all required attributes like a hash key, load times or hash difference key)
Data Vault 2 added an extra component to handle Big Data scenarios, but you will find it in the 3rd section.
Hashes are everywhere
In the first specification of Data Vault, the sequence surrogate keys were allowed to overcome performance issues due to the joins on multiple columns. However, it introduced some constraints during the loading, and with the modern data technologies, it doesn't fit everywhere.
That's the reason why it changed, and the recommended way to deal with it is to generate a hash key from all columns identifying the business key. When can it apply? An example you will find very often is one of the flights. A flight has the same number but occurs on different days. So the business key is not only the number but also the date. Both can be then used to compute the hash to be used as an optional key. And this optional key has few benefits that I will discuss in the next section.
Another place where the hash function can be used is an optional hash difference column. You can add it to detect changes in the satellites for a given business key instead of performing the comparison column by column.
Why Big Data-compliant?
In 2 previous sections, you already saw a few changes that help Data Vault adapt to the modern data architectures. The first adaptation is the extra component from the first section of the blog post called landing zone files. They're the files written into an environment characterized by parallel access, partitioning, sharding, and possibly sub-partitioning (bucketing?). Sounds familiar? Yes, it's data lake-compatible.
Regarding the hashes, they have a great benefit for the Big Data workloads. The loading pattern for Data Vault 1 required to load the hubs first, and later, when the links and satellites were loaded, make the lookups on the hubs table to retrieve the surrogate keys. It changes in the Data Vault 2 because the hash key is deterministic, ie. it can be resolved from already existing data, making the load parallel for all components:
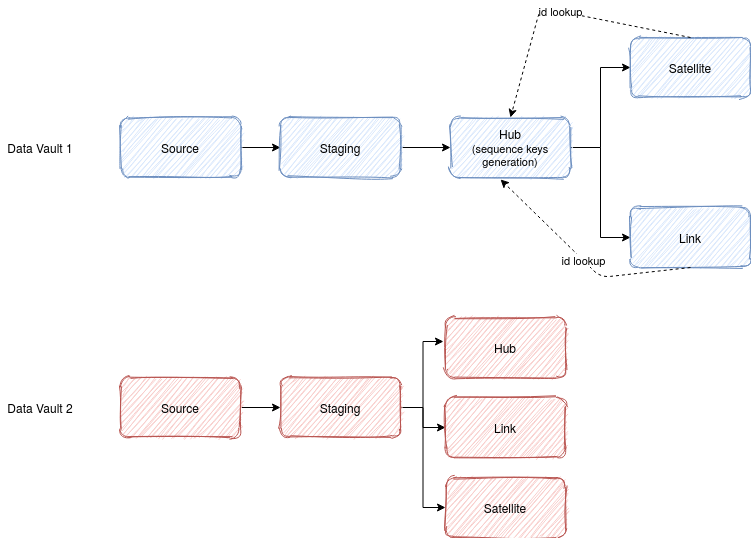
Of course, this approach makes only sense where there are no referential integrity constraints. If it's enforced, you will have to load hubs, links and satellites in order.
Another Big Data-related change is about making some fields optional. An example of that is the load date time field representing when a given record arrived in the system. Not all platforms support it (in Spark you can use current_timestamp method) and was made optional in the new specification. Same, but not for the same reason, is valid for the update user or update timestamp fields representing who and when updated a given line for the last time in the landing zone. Despite the recent effort with ACID-compatible file formats (DeltaLake, Apache Hudi, Apache Iceberg), in-place changes are still costly for big volumes of data. That's why these 2 fields were made optional.
Finally, the already mentioned surrogate sequence keys are deprecated because they don't scale and aren't deterministic (eg. multi-region dataset split).
Architecture examples
All this is still related to the modeling part of Data Vault. Let's now see an example of the architecture. As for every data system, on the leftmost part of the schema, you can find the data sources and the ingestion process that, thanks to the landing zone (aka staging area) abstraction, can be performed in real-time.
An important point to notice is that at this first stage, you can only apply hard rules like reformatting the data. You can't apply the soft rules, which are the data-interpretation business rules. In consequence, the data must remain as close to the source format as possible.
The data from the landing zone will be loaded into the data warehouse layer, where you will apply all Data Vault modeling rules. But not only. This layer can contain 3 optional vaults. The first of them is Business Vault representing the raw vault with business rules applied. It's useful for the advanced users of the organizations who can do some smart things with the data on their own, without necessarily accessing it from BI reporting tools or the data exposition layer.
The second optional part is called Metrics Vault. That's the place where different statistics about ETL execution are recorded. The last part is about Operational Vault, and it's there to ensure faster access for the external systems that, for example, may need it to replicate the master dataset or reference tables definition to the vault.
Once all these vaults are ready, the data is processed with soft rules and exposed to the marts like classical data marts or error marts. The latter stores the ETL errors occurred during this exposition stage. There is also a meta mart that will contain the metadata about the raw vault (the one not processed with soft rules), parameters for business rules or backup logs.
To sum-up this architecture part, nothing better than a picture:
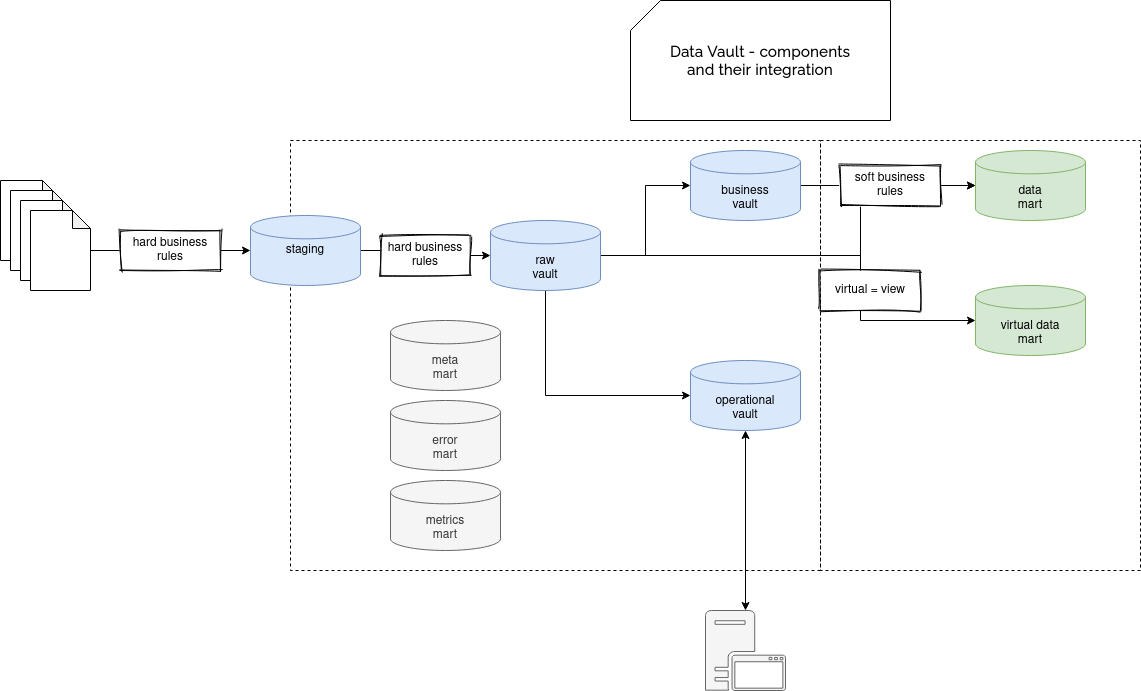
Just a quick summary, because sometimes you can find 2 incoming arrows. In the design proposals I found (links in Further reading section), some different approaches were proposed. Regarding the loading part, the staging area is optional, and if it's missing, the data is loaded directly to the raw data vault. The same flexibility applies to the data marts. You can either build them from a business vault or directly from the raw vault with a virtual data mart, which is nothing more than a view on top of the raw vault.
After the first post about Data Vault, you could think that it's only a modeling approach. It's not, and you can see it in this article. Despite a more detailed explanation for the Data Vault components, you can see that it's also an architectural approach that fits the continually evolving data world.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Data Vault 2.0 and Big Data here:
- Hash Keys in the Data Vault Data Modeling Specification v 2.0.2 DV2.0 Introduction to Data Vault for Data Warehousing Transactional Links Loading Dimensions from a Data Vault Model
Related blog posts:
The last part of Data Vault articles is online. This time you can see more advanced concepts and their integration into a simple architecture diagram ? https://t.co/pRPGiqXMQ4
— Bartosz Konieczny (@waitingforcode) January 3, 2021