
Java programmers are often limited in their thoughts to heap management and it's justified. JVM offers the possibility to code without taking care about manual objects allocation and deallocation. But, as JVM-based language programmer, at least for personal knowledge, it's good to know that on heap memory is not the single memory storage solution in JVM applications. The complement memory is off-heap.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post describes off-heap memory in the context of JVM-based languages (Java, Scala - used in code samples) point of view. The first part recalls what happens when new objects are created and where it's located. It's the required point to understand better off-heap memory, described in the second section. The last part contains some learning tests that show how to manipulate off-heap memory with Unsafe and ByteBuffer classes.
On-heap memory
JVM-based applications use predefined amount of total system memory called on-heap that is divided in different spaces shown in image below:
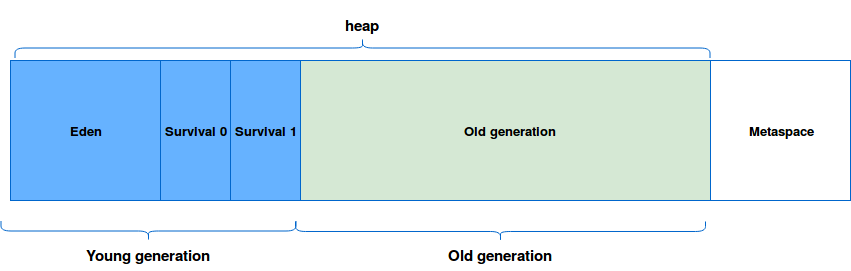
Each newly created class instance is located in the eden space of young generation. If it's still in used in the moment of Garbage Collection, it's promoted to the next space. Finally, if it's a long lived object, it's moved to the old generation where the GC are less frequent and more susceptible to produce longer stop-the-world events (old generation is usually much bigger than each of previous spaces). If you want to learn more about it, you can read the post about Generations in JVM.
After this short reminder we could characterize on-heap memory as a memory present in the JVM and managed automatically by the Garbage Collector.
Off-heap memory
At first glance everything seems to be fine - objects are located and deallocated automatically, on-heap is freely configurable through appropriated options. But sometimes it's not enough, especially when we need to: cache a lot of data without increasing GC pauses, share cached data between JVMs or add a persistence layer in memory resistant to JVM crashes. In all mentioned cases off-heap memory is one of possible solutions.
As you can imagine, the off-heap memory stores the data outside the heap in OS memory part. Because there are no the JVM, the data must be stored in specific format that is an array of bytes. So using the off-heap memory in JVM languages programs introduces the overhead of serializing/deserializing these arrays to corresponding objects every time with additional cost of going outside the JVM and dealing with native memory. And because this space is out of JVM it can follow its own rules and bring other problems to programmers as Big-Endian and Little-Endian one.
Big-Endian vs Little-Endian
The endianness difference consists on bytes representing in the memory. Big-Endian (BE) stores the most significant bytes in the smallest address while Little-Endian (LE) stores the least significant ones in these address. If we take the value of 0x12345672, in BE it'll be stored as: 0x12, 0x34, 0x56 and 0x72. However for the LE, this value will be stored as: 0x72, 0x56, 0x34 and 0x12.
To handle this in Java's ByteBuffers we can use the order(ByteOrder bo) method taking either BIG_ENDIAN or LITTLE_ENDIAN as a parameter. To discover the endianness we could add a kind of flag (or magic number) in the beginning of the array. Before reading all data, we should read this flag first and check its order (LE or BE), and apply it to the later reading.
However the use off-heap can help to reduce GC pauses (especially in large heaps). It also allows different process to share the data stored in memory (e.g. C++ program and Scala one). In additional, off-heap memory helps the data to survive JVM crashes. With that it's possible to have a long living hot cache.
But off-heap memory is not the solution in all cases:
- Still short-lived objects (= never promoted to old generation) are better suited for on-heap storage simply because of the simplicity guaranteed by this automatic management.
- Moreover, the JIT can make several optimization for memory use (e.g. some objects allocation can be skipped thanks to Escape Analysis).
- In addition, off-heap storage involves serialization/deserialization overhead (we can save only arrays of bytes) that doesn't exist in on-heap objects storage.
- Off-heap storage means the manual management of the memory. Sometimes it can lead to memory leaks, seg faults or other uncommon problems in the life of "on-heap Java programmer".
Off-heap example
The examples below deal with off-heap memory through sun.misc.Unsafe and java.nio.ByteBuffer (with Scala for the brevity). As you'll see, the use of both of them is not straightforward, especially if you take a look at ignored test case (you can uncomment it to see the segmentation fault):
"DirectByteBuffer" should "allocate some simple integer on off heap and take 4 bytes" in {
val directBuffer = ByteBuffer.allocateDirect(10)
// puts int at the first available offset
directBuffer.putInt(1)
// As you can see, even if we put a simple int, the position is 4 instead of 1
// It means that 4 bytes was taken
// It's one of reasons why dealing with off heap memory is tricky (= difficult to
// estimate the necessary amount of storage)
directBuffer.position() shouldEqual 4
directBuffer.getInt(0) shouldEqual 1
}
"allocating int at the last position" should "throw an exception because int takes 4 bytes" in {
// This situation looks like the previous one. As we know
// the int takes 4 bytes so to allocate it at the end of 10-bytes array
// we should start with the 6th index and not the last one
// At first glance, it could appear a little bit confusing
val directBuffer = ByteBuffer.allocateDirect(10)
assertThrows[IndexOutOfBoundsException] {
directBuffer.putInt(10, 1)
}
}
"adding int without index" should "override the added element with explicit index because of not changing position" in {
val directBuffer = ByteBuffer.allocateDirect(12)
// But the .position() method is a little trap
// The cursor moves only when the value is added
// without explicit index:
directBuffer.putInt(1)
val positionAfter1 = directBuffer.position()
directBuffer.putInt(4, 2)
val positionAfterExplicit2 = directBuffer.position()
// We put again the value without defining the index
directBuffer.putInt(3)
val positionAfter3 = directBuffer.position()
positionAfter1 shouldEqual 4
positionAfterExplicit2 shouldEqual 4
positionAfter3 shouldEqual 8
val valueAt0Index = directBuffer.getInt(0)
valueAt0Index shouldEqual 1
// int=2 should be here but int=3 took its place
val valueAt4Index = directBuffer.getInt(4)
valueAt4Index shouldEqual 3
}
"with Unsafe use" should "allocate first 10 bytes" in {
val unsafe = getUnsafe()
val address = unsafe.allocateMemory(10)
var position = address
// Here again, int takes 4 bytes, so we need to handle address position
// manually in the code
unsafe.putInt(position, 1)
position += 4
unsafe.putInt(position, 2)
// Now, check if the ints were saved correctly
val mostRecentInt = unsafe.getInt(position)
position -= 4
val firstAddedInt = unsafe.getInt(position)
firstAddedInt shouldEqual 1
mostRecentInt shouldEqual 2
}
// Replace 'ignore' by 'in' to enable this test and see the problem
"allocating data on already taken memory address" should "make JVM crash" ignore {
val unsafe = getUnsafe()
unsafe.allocateMemory(10)
// We allocated only 10 byte so the 200th position is out of the range and
// should produce SIGSEGV error as the follow one:
// # A fatal error has been detected by the Java Runtime Environment:
// #
// # SIGSEGV (0xb) at pc=0x00007f9fa5ad3251, pid=3694, tid=0x00007f9fa6c35700
// #
// # JRE version: Java(TM) SE Runtime Environment (8.0_101-b13) (build 1.8.0_101-b13)
// # Java VM: Java HotSpot(TM) 64-Bit Server VM (25.101-b13 mixed mode linux-amd64 compressed oops)
// # Problematic frame:
// # V [libjvm.so+0xa8f251] Unsafe_SetNativeInt+0x51
val corruptedPosition = 200
unsafe.putInt(corruptedPosition, 4)
}
private def getUnsafe(): Unsafe = {
try {
val unsafeField: Field = classOf[Unsafe].getDeclaredField("theUnsafe")
unsafeField.setAccessible(true)
unsafeField.get(null).asInstanceOf[Unsafe]
} catch {
case x: Throwable => x.printStackTrace()
null
}
}
As proved through this post, off-heap memory can be useful in some specific cases. In the context of applications dealing with a lot of data stored in memory, it can significantly help to reduce the size of heap and thus the pauses needed for GC. However, as shown in the learning tests, it's still tricky to deal with it directly. And instead of doing that, you'd rather consider to use one of existing Open Source libraries (e.g. Chronicle from OpenHFT Github).
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about On-heap vs off-heap storage here:
- WJUG #166 - On-heap cache vs Off-heap cache w Javie - Radek Grębski On heap vs off heap memory usage Off-heap memory