
As a former Java engineer, when I have started to work with Scala, I was very early punished for my bad habits about mutable collections. In this post I will show you the story which learned me to prefer the immutability everywhere it's possible.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post tries to explain the importance of immutable collections in Scala - something quite unnatural for a lot of people like me coming from Java ground. I hope the post will convince you (if you are not yet convinced) and will avoid a lot of debug. The first section presents the context that made me appreciate the immutability of collections. The next one presents the solution with the use of immutable data structures. The last part provides more information about good and bad points of them.
The context
Some years ago I was working on a project sending DynamoDB batch get requests. To do that, I used a library shared across all the projects. Since it worked pretty well at that moment, I added it into my project's dependencies confidently.
The library executed batch queries with asynchronous DynamoDB client and made returned a limited number of items. That means that from time to time in order to read all records, we needed to run it in a loop. Fortunately, the SDK provides com.amazonaws.services.dynamodbv2.model.QueryRequest#withExclusiveStartKey(java.util.Map
"data async reading with mutable collection" should "fail because of concurrent access" in {
object RecursiveDataConsumer {
def consumeData(): Seq[Int] = {
// some database query; we start with a small collection to resize the buffer
val dataBuffer = new mutable.ArrayBuffer[Int](2)
consumeRemainingData(dataBuffer, 20)
}
def consumeRemainingData(dataBuffer: mutable.ArrayBuffer[Int], limit: Int): mutable.ArrayBuffer[Int] = {
if (limit > 0) {
new Thread(new Runnable() {
override def run(): Unit = {
try {
dataBuffer ++= InfiniteDataGenerator.generateRows
} catch {
case NonFatal(_) => throw new RuntimeException("error")
}
}
}).start()
consumeRemainingData(dataBuffer, limit - 1)
} else {
dataBuffer
}
}
}
try {
RecursiveDataConsumer.consumeData()
} catch {
case re: RuntimeException => {
re.printStackTrace()
}
}
}
As expected, the code fails because of the concurrent writes on the same ArrayBuffer and conflicting resizing operations. Since it was difficult to illustrate the failure on the embedded database, I written a short schema to show the real context failing with ConcurrentModificationException:
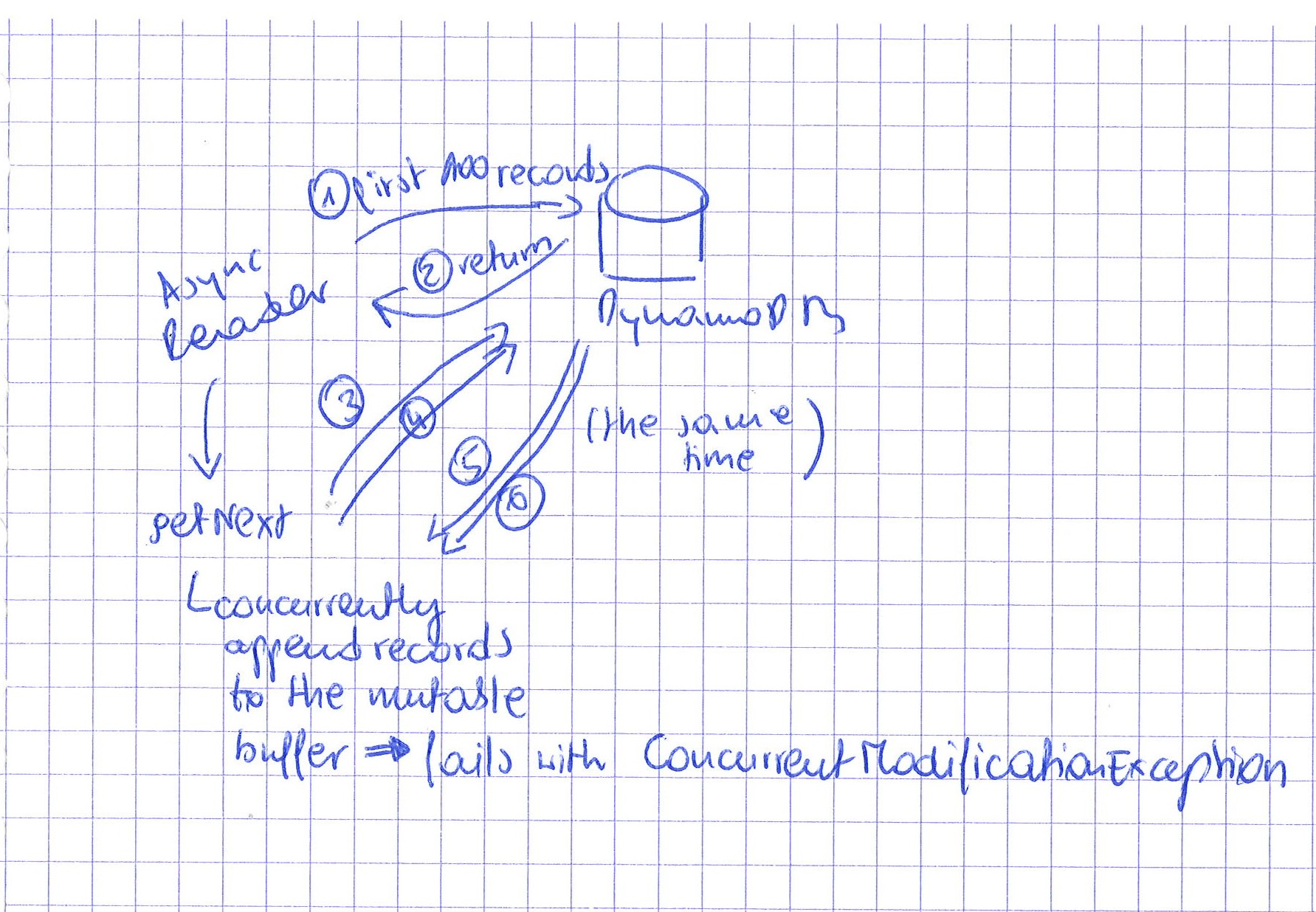
The fix with immutable collection
To fix the such code we have different choices. The first one is the use of synchronized block to eliminate concurrent writes into the buffer. However, this approach adds some blocking to the application, and therefore slows it down. Also, the blocking can lead to more serious problems than several milliseconds of difference, as deadlocks.
Another and much better solution than synchronized block is the use of an immutable collection. The main advantage, shown by the way here, is the thread-safety. The created collection can't be modified in-place. It fits well for our use case with recursive data consumption::
"data async reading with immutable collection" should "succeed because of concurrent access" in {
object RecursiveDataConsumerThreadSafe {
def consumeData(): Seq[Int] = {
// some database query
consumeRemainingData(Seq[Int](), 20)
}
def consumeRemainingData(dataBuffer: Seq[Int], limit: Int): Seq[Int] = {
if (limit == 0) {
dataBuffer
} else {
dataBuffer ++ InfiniteDataGenerator.generateRows ++ consumeRemainingData(dataBuffer, limit - 1)
}
}
}
val retrievedData = RecursiveDataConsumerThreadSafe.consumeData()
retrievedData should have size 40
retrievedData should contain only(0, 1)
}
Using immutable collections
Aside of the thread-safety, the immutable collections provide other advantages. First, they simplify the reasoning about the program. Conceptually the immutability reduces the scope of the object. Concretely, that means that we don't need to worry whether somebody will modify the given object elsewhere - even though the collection is passed as a parameter to other methods. The immutability is also a good way to express the intent. By using an immutable object we clearly mark it as the one which won't and shouldn't be modified outside of its creation scope.
Unfortunately, it's not easy to switch to the immutable collections when during several years we had been using the mutable ones. We are often tempted to stay with our old habits, particularly at the beginning. It's often the case for a lot of for loop-related things when Scala newcomers copy old Java idioms like this one:
"mutable collection" should "be used to show old habit" in {
val numbers = new mutable.ListBuffer[Int]()
for (nr <- 1 to 10) {
numbers.append(nr * 2)
}
numbers should have size 10
numbers should contain allOf(2, 4, 6, 8, 10, 12, 14, 16, 18, 20)
}
This code can be easily rewritten with the help of map function and therefore, not use the mutability:
"map" should "be used to build an immutable collection in new manner" in {
val numbers = (1 to 10).map(nr => nr * 2)
numbers should have size 10
numbers should contain allOf(2, 4, 6, 8, 10, 12, 14, 16, 18, 20)
}
According to some microbenchmarks (Scala's immutable collections can be slow as a snail or Benchmarking Scala Collections), the immutable collections can sometimes perform worse than their mutable colleagues. But since conceptually they're easier to work with and in addition to that, they're thread-safe, we should prefer them as often as possible. A good rule of thumb would be their use by default and the switch to their mutable versions only when we encounter some performance issues because of them.
In this post, through 3 sections, we could discover some positive aspects of the immutable collections use. As shown in the 2 first parts, the immutable collections guarantee thread-safety. It can be pretty easily detected in the case of concurrent writes to a mutable sequence. Depending on the used implementation we'll either have to deal with ConcurrentModificationException or other, more specific errors. But the thread-safety it's not the single reason to prefer the immutable collections. As proven in the 3rd part, they also facilitate the understanding of the application. Everything we need to do is to get rid of the old "Java" habits and do not be afraid of the change. After all, in the case of any problems, we can always switch to the mutable version.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Sealed keyword in Scala
- Promises in Scala
- Annotations in Scala
- Work-stealing in Scala
- Type specialization in Scala
In today #OneScalaFeaturePerWeek post I shared the context which made me appreciate the immutability in #Scala https://t.co/tPzoKmz9N9
— Bartosz Konieczny (@waitingforcode) January 27, 2019