
Last time I wrote about a special - but logical - behavior of NULLs in joins. Today it's time to see other queries where NULLs behave differently than columns with values.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Conditions
The first place where NULLs can surprise you are the conditions. If you write a query like SELECT * FROM my_table WHERE column_a != 1 and your table contains null values in the filtered column, they won't be returned. It may sound strange at first because NULL != 1, doesn't it? In fact, the reason for that is the same as for the JOINs from the previous blog post – NULL is considered as an unknown value, so it's not different from a real value which is 1:
letters = spark.createDataFrame([{'id': 1, 'letter': 'A'}, {'id': None, 'letter': 'B'}, {'id': 4, 'letter': 'D'},
{'id': None, 'letter': 'E'}, {'id': None, 'letter': 'F'}],
'id INT, letter STRING')
letters.createOrReplaceTempView('letters')
spark.sql('SELECT * FROM letters WHERE id != 2').show()
The result of this query will be:
+---+------+ | id|letter| +---+------+ | 1| A | | 4| D | +---+------+
To include the NULLs in the query, you need to add an IS NULL condition, therefore transform the statement to SELECT * FROM letters WHERE id != 2 OR id IS NULL:
+----+------+ | id|letter| +----+------+ | 1| A | |NULL| B | | 4| D | |NULL| E | |NULL| F | +----+------+
Consequently, the same NULL-as-unknown behavior applies to other conditional statement in SQL, such as CASE...WHEN.
Count
Besides filtering, NULLs can also put you into trouble while counting rows. Let's analyze these two queries in the context of our letters dataset:
spark.sql('SELECT COUNT(*) AS all_rows FROM letters').show()
spark.sql('SELECT COUNT(id) AS all_rows FROM letters').show()
When you compare the results, you will see both are different:
+--------+ |all_rows| +--------+ | 5 | +--------+ +--------+ |all_rows| +--------+ | 2 | +--------+
When you write COUNT(*), you ask your query engine to count all the rows whereas if you write COUNT(id), you only want to get the rows that have the id defined. That's the simplest explanation for this difference yet again relying on the fact that NULL is considered as an unknown and not defined value.
By the way, the same behavior applies to the aggregation functions, such as AVG. A query like SELECT AVG(id) AS average_id FROM letters will return an average of 2.5 because 1 + 4 / 2 = 2.5 and only 2 rows have their id defined.
Concatenations and additions
The third place where NULLs can surprise you are concatenations or additions. Concretely speaking, if in our test dataset you do:
- id + 3, the results will be NULL for all columns where id is unknown
- CONCAT_WS("_", "id", id) the result will be id for all columns where id is unknown
As you can see, depending on the operation, NULL is either propagated or not. It's then not easy to predict how a given function will behave with NULLs and for that reason, it's always recommended to verify the semantics beforehand.
IN vs. EXISTS
When you need to verify if a row exists in another table, you can do it with WHERE ... NOT IN condition, or with WHERE NOT EXISTS. To understand how both behave with NULLs, let's use this time a more advanced example with two tables:
letters_1 = spark.createDataFrame([{'id': 1, 'letter': 'a'}, {'id': None, 'letter': 'b'}, {'id': 3, 'letter': 'c'},
{'id': None, 'letter': 'G'},], 'id INT, letter STRING')
letters_2 = spark.createDataFrame([{'id': 1, 'letter': 'A'}, {'id': None, 'letter': 'B'}, {'id': 4, 'letter': 'D'},
{'id': None, 'letter': 'E'}, {'id': None, 'letter': 'F'},], 'id INT, letter STRING')
letters_1.createOrReplaceTempView('letters_1')
letters_2.createOrReplaceTempView('letters_2')
Let's imagine that you want to get all rows from letters_1 that are not present in the letters_2. For that you issue a query like:
spark.sql('''
SELECT * FROM letters_1 l1
WHERE l1.id NOT IN (SELECT id FROM letters_2)
''').show()
Surprisingly, it doesn't return any results!
+---+------+ | id|letter| +---+------+ +---+------+
On another hand, when you use the NOT EXISTS:
spark.sql('''
SELECT * FROM letters_1 l1
WHERE NOT EXISTS (SELECT 1 FROM letters_2 l2 WHERE l1.id = l2.id)
''').show()
...the result will contain all rows from letters_1 that are missing in the letters_2 table:
+----+------+ | id|letter| +----+------+ |NULL| b | | 3| c | |NULL| G | +----+------+
Although you might achieve the same results with the two methods, there is a significant difference if your subquery returns NULLs. The NOT IN is a value-based operation, therefore yet again if the subquery returns a NULL, the expression evaluates as unknown. It's not the case of the NOT EXISTS that verifies whether a row – so not a value – exists in the subquery. Consequently, it's not affected by this NULLs problem.
Ordering
The next place where NULLs can be surprising are the ordering statements. Depending on the database you use, the NULLs can be returned first or last. In Databricks the rows with NULLs are considered as the lowest value...
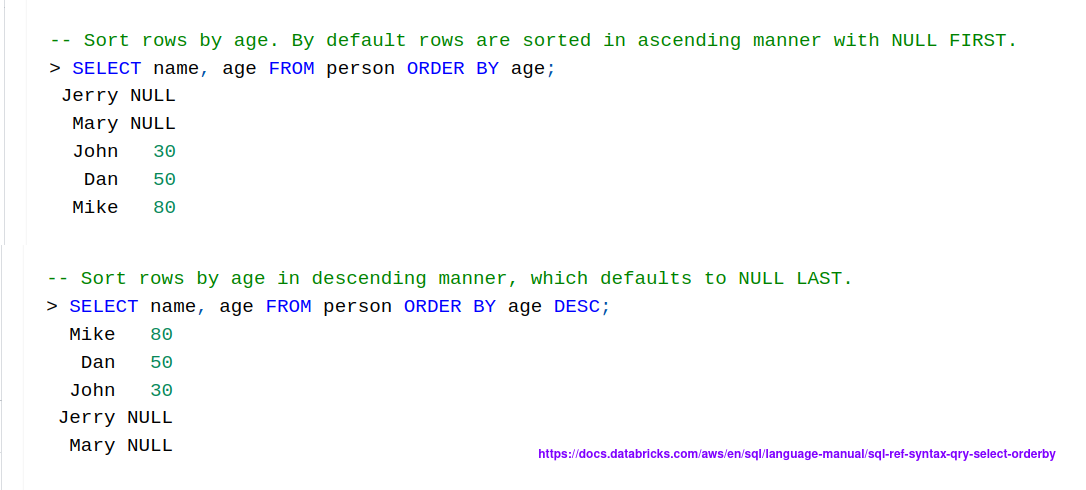
The opposite happens for PostgreSQL:

If you want to avoid any surprises – and also because being explicit is better than being implicit for future you and your colleagues - you can extend the ordering clause by NULL FIRST or NULLS LAST to return NULL values in the beginning or in the end of the dataset. Let's see this in action with our letters dataset:
letters = spark.createDataFrame([{'id': 1, 'letter': 'A'}, {'id': None, 'letter': 'B'}, {'id': 4, 'letter': 'D'}, {'id': None, 'letter': 'E'}, {'id': None, 'letter': 'F'}], 'id INT, letter STRING')
letters.createOrReplaceTempView('letters')
spark.sql('SELECT * FROM letters ORDER BY id ASC NULL LAST').show()
spark.sql('SELECT * FROM letters ORDER BY id ASC NULL FIRST').show()
The result will be:
+----+------+ | id|letter| +----+------+ | 1| A | | 4| D | |NULL| F | |NULL| E | |NULL| B | +----+------+ +----+------+ | id|letter| +----+------+ |NULL| E | |NULL| B | |NULL| F | | 1| A | | 4| D | +----+------+
Constraints
So far you have seen NULLs behavior in the context of data reading. However, they may surprise you also in writing. For example, a unique constraint will not prevent many rows with nulls to be written. To see this, let's start a PostgreSQL instance:
docker run --name wfc -e POSTGRES_USER=wfc -e POSTGRES_PASSWORD=wfc -e POSTGRES_DB=wfc_db -p 5432:5432 -d postgres:15 docker exec -it wfc psql -U wfc -d wfc_db
Next, let's create a simple table with two columns:
wfc_db=# CREATE TABLE letters (id INT NULL UNIQUE, letter CHAR(1));
Now, if you try to insert the following rows, the unique constraint won't apply:
wfc_db=# INSERT INTO letters (id, letter) VALUES (NULL, 'a'), (NULL, 'b'), (3, 'c');
The select statement will return all three rows:
wfc_db=# SELECT * FROM letters;
id | letter
----+--------
| a
| b
3 | c
(3 rows)
For the sake of formality, let's validate if the unique constraint is working for defined values:
wfc_db=# INSERT INTO letters (id, letter) VALUES (4, 'd'), (5, 'e'), (3, 'c'); ERROR: duplicate key value violates unique constraint "letters_id_key" DETAIL: Key (id)=(3) already exists.
As you can see, it is working correctly. This unique constraints part is a great example of the special consideration of the NULLs. I'll repeat this again but NULLs are unknown and not defined, so a database cannot consider them in terms of equity because both equal and not equal are valid answers to the question.
NULLs are special; they're not values and deserve a dedicated treatment on your side. That's the last time I'm repeating this, hopefully to avoid you some bad surprises in the future 😉
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩