
Apache Airflow 2 introduced a lot of new features. The most visible one is probably a reworked UI but there is more! In this and the next blog post I'll show some of the interesting new Apache Airflow features.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Task Flow API
The first improvement from my list is the Task Flow API. This new method greatly simplifies the DAG declaration by getting rid of many Airflow DSL-related elements. For example, to run an arbitrary Python function you don't need to create a PythonOperator and the associated function. Instead, you can simply define the function and annotate it with a @ŧask decorator.
Want to see it in action? Below you can find a model of the DAG based on the Task Flow API:
@task
def create_cluster():
task_definition = {'jar': 'abc.jar'}
logging.info(f'Creating cluster with {task_definition}')
return 'cluster_id'
However, there is a catch! The decorator applies to Python-evaluated operators and you can find the full list of the supported elements in the TaskDecoratorCollection:
class TaskDecoratorCollection:
# ...
python = staticmethod(python_task)
virtualenv = staticmethod(virtualenv_task)
external_python = staticmethod(external_python_task)
branch = staticmethod(branch_task)
short_circuit = staticmethod(short_circuit_task)
Fortunately, the usage of the Task Flow API allows both old- and new-style DAGs declaration:
data_availability_checker = PythonSensor(
task_id='data_availability_checker',
python_callable=check_files_availability,
do_xcom_push=True
)
@task
def create_cluster():
task_definition = {'jar': 'abc.jar'}
logging.info(f'Creating cluster with {task_definition}')
return 'cluster_id'
data_availability_checker >> create_cluster()
Another improvement this new API brings is the ease of passing the variables between tasks. Since they're just Python functions, the parameters exchange consists of referencing the functions return values:
@task
def create_cluster():
task_definition = {'jar': 'abc.jar'}
logging.info(f'Creating cluster with {task_definition}')
return 'cluster_id'
@task
def notify_running_job(cluster_id: str):
logging(f'A job is running on the cluster {cluster_id}')
return 'job_id_a'
cluster_creator = create_cluster()
data_availability_checker >> cluster_creator >> notify_running_job(cluster_creator)
Under-the-hood these "parameters" from the function signature are...XCom variables! The good news is that their exchange is not limited to the @ŧask-decorated functions:
@task
def notify_running_job(cluster_id: str):
logging(f'A job is running on the cluster {cluster_id}')
return 'job_id_a'
def check_job_status():
context = get_current_context()
task_instance: TaskInstance = context['task_instance']
job_id = task_instance.xcom_pull(task_ids='notify_running_job')
logging.info(f'Checking job status for {job_id}')
return True
The last good news is the extendibility. If you need to write your own decorator, you can create a custom one!
Task groups
Another task-related feature in Apache Airflow 2 are task groups. They're a recommended choice over the deprecated SubDAGs to create collections of closely related tasks that should be grouped and displayed together.
Their declaration is relatively easy. It looks like writing a DAG except that each task group can be a parent for another. You can check my example out where I'm generating 12 task groups with 2 subgroups inside each of them:
with TaskGroup(group_id='partitions_cleaners') as partitions_cleaners:
months_to_clean = range(12)
sub_task_groups = []
for month_to_clean in months_to_clean:
with TaskGroup(group_id=f'month_{month_to_clean}', parent_group=partitions_cleaners) as month_cleaners:
partition_1_cleaner = EmptyOperator(task_id=f'merge_{month_to_clean}_partition_1')
partition_2_cleaner = EmptyOperator(task_id=f'merge_{month_to_clean}_partition_2')
sub_task_groups.append([partition_1_cleaner, partition_2_cleaner])
sub_task_groups
Before moving forward, let's stop for a while and see the reasons for depreciating the SubDAGs and preferring task groups:
- SubDAGs use the main DAG slots until all SubDAG tasks complete. It can introduce a significant delay in the processing.
- Separation. SubDAGs might have different parameters or schedule than the main DAG. It can lead to unexpected behavior which is hard to debug.
Task groups repeat the tasks as an instance of the main DAG and overcome the SubDAG issues.
Dynamic task mapping
The 3rd change impacting the DAGs you can write is dynamic task mapping. Sounds mysterious? Actually, the feature is simpler than the name. It lets you generate dynamic DAGs that might have a different number of a given task instance.
In my example below I'm creating a DAG running the refresh_table task as many times as the month day of the execution date:
@task
def refresh_table(table_name: str):
logging.info(f'Refreshing {table_name}')
return table_name
@task
def generate_params_from_execution_date_day():
context = get_current_context()
execution_date: DateTime = context['execution_date']
logging.info(f'execution_date.day = {execution_date.day}')
return map(lambda day: f'table_{day}', range(execution_date.day))
@task
def refresh_materialized_view(refreshed_tables):
logging.info(f'>>> Refreshing materialized view for tables {", ".join(refreshed_tables)}')
tables = refresh_table.expand(table_name=generate_params_from_execution_date_day())
refresh_materialized_view(tables)
Apache Airflow 2 refers to them as to lazy sequences that gets resolved at runtime, only when asked. There is no eager evaluation involved.
Data dependencies
The last feature covered in this first part is about scheduling. Apache Airflow 2 has a possibility to schedule the DAG after a dataset is available. To do that, the new version supports a Dataset trigger. In the example below, I'm generating text files into a watched Dataset directory:
dataset_path = 'file:///tmp/datasets'
dataset = Dataset(uri=dataset_path)
with DAG(dag_id='dataset_writer', start_date=start_date_for_reader_and_writer, schedule='@daily') as writing_dag:
@task(outlets=[dataset])
def data_generator():
context = get_current_context()
execution_date: DateTime = context['execution_date']
with open(f'{dataset_path}/{execution_date.to_date_string()}.txt', 'w') as file_to_write:
file_to_write.write("abc")
data_generator()
with DAG(dag_id='dataset_reader', start_date=start_date_for_reader_and_writer, schedule=[dataset]) as reading_dag:
@task
def data_consumer():
print(os.listdir(dataset_path))
data_consumer()
writing_dag
reading_dag
This data-aware scheduling adds an extra place to the UI where you can visualize all DAGs triggered by each Dataset:
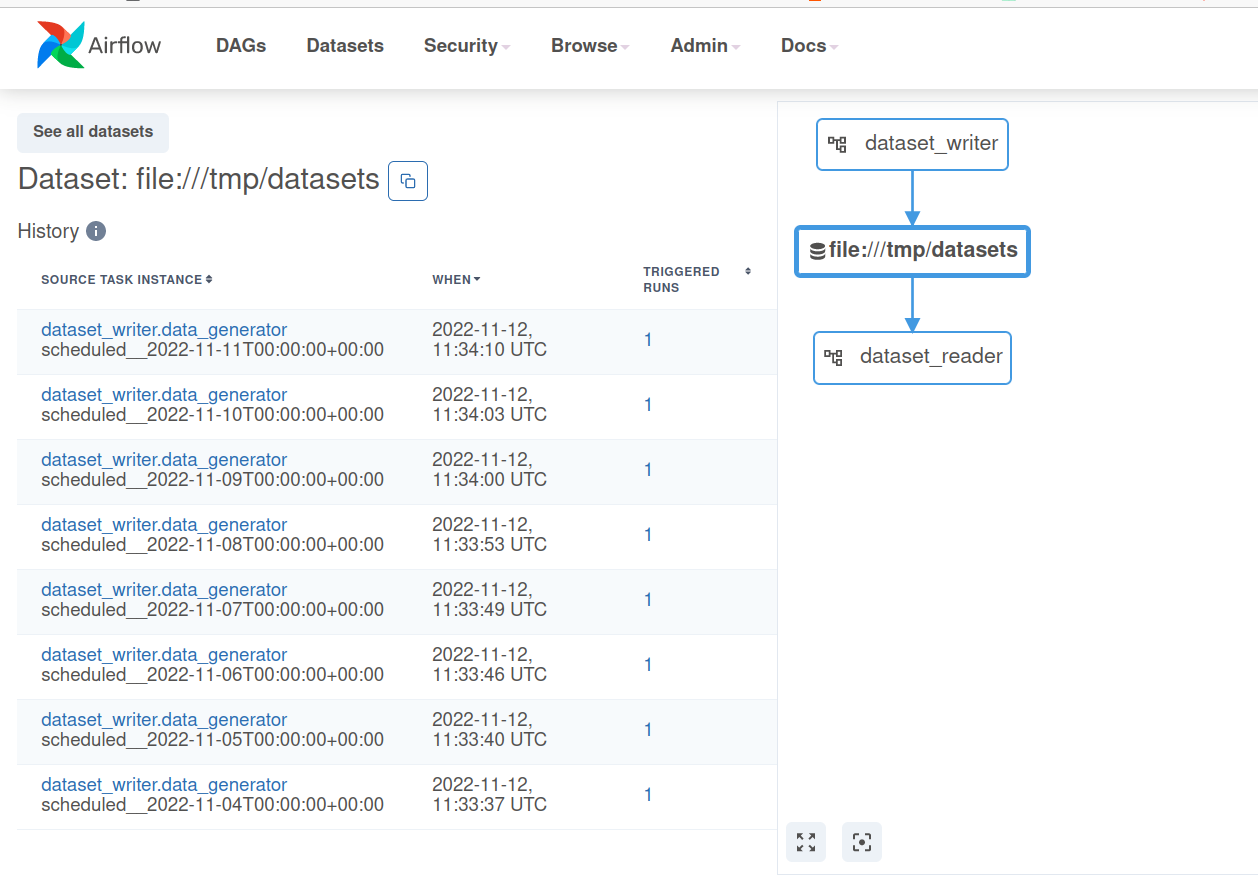
An important thing to notice, though. I haven't succeeded in using the Dataset-scheduling on top of an externally generated data (by not an Airflow-managed writer). Additionally, there is no way to define complex input patterns, such as regular expressions or file glob patterns. That's why you might still need some data sensors in the DAGs to handle these scenarios.
As you can see, Apache Airflow 2 doesn't only come with the new User Interface. It also has several new features extending the tasks and DAG capabilities. And it's only the beginning. I'll share the rest next week in the second part of the blog post.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Apache Airflow 2 overview - part 1 here:
Related blog posts:
- Apache Airflow 2 overview - part 2
- Dealing with time delta in Apache Airflow
- DAG evolution - using start_date and end_date?
My last #ApacheAirflow blog post is 2 years old! It was necessary to catch up on the most recent changes of this data orchestrator. Today it's the first part of 2 articles covering the new features in the release number 2 ? https://t.co/cEHAroxJX3
— Bartosz Konieczny (@waitingforcode) December 4, 2022