
One of the greatest properties in data engineering is idempotency. No matters how many times you will run your pipeline, you will always end up with the same outcome (= 1 file, 1 new table, ...). However, this property may be easily broken when you need to evolve your pipeline. In this blog post, I will verify one possible way to manage it in Apache Airflow.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The post is divided into 2 parts. In the first one, I will describe my idea to handle DAG evolution with start_date and end_date attributes. In the second part, I will verify whether I was wrong or not about that concept.
Manage evolution with time
The idea is to have one DAG execution that will be composed of 2 execuion logics thanks to the start_date and end_date attributes. The following schema shows that pretty clearly with the red part of the DAG executed in the past and blue part of the DAG executed in the current period:
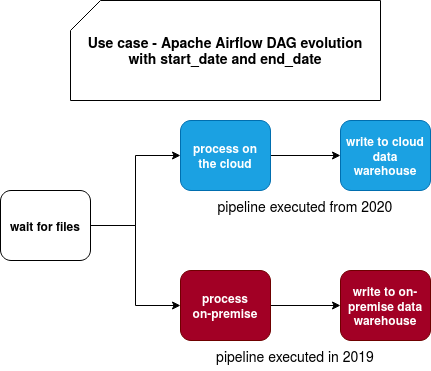
What is the goal of such a split? As explained in the introduction, the main purpose is to preserve idempotence, so avoid the situation when you will relaunch the pipeline for 2019 and generate the results for your cloud data warehouse instead of the on-premise one (since all 2019 must be stored there). Are there other alternatives? Yes:
- you can use BranchPythonOperator and depending on the date, follow one branch or another
- you can duplicate the DAG and create a new one suffixed with _2020. Since Apache Airflow defines the processing logic as the code, you can share common parts between different versions and customize only different ones. To implement that you can use a Factory method pattern
But let's check whether start_date and end_date can be also used as a solution.
Test time
The structure of my tested DAG looks like in the following snippet:
task_2019_start = datetime(2019, 11, 1, hour=0)
task_2020_end = datetime(2021, 1, 1, hour=0)
dag = DAG(
dag_id='dates_for_idempotence_test',
schedule_interval='@monthly',
start_date=task_2019_start,
end_date=task_2020_end
)
with dag:
task_2019_end = datetime(2020, 12, 31, hour=23)
common_start = DummyOperator(
task_id='common_start',
start_date=task_2019_start,
end_date=task_2020_end
)
task_1_2019 = DummyOperator(
task_id='task_1_2019',
start_date=task_2019_start,
end_date=task_2019_end
)
task_2_2019 = DummyOperator(
task_id='task_2_2019',
start_date=task_2019_start,
end_date=task_2019_end
)
task_2020_start = datetime(2020, 1, 1, hour=0)
task_1_2020 = DummyOperator(
task_id='task_1_2020',
start_date=task_2020_start,
end_date=task_2020_end
)
task_2_2020 = DummyOperator(
task_id='task_2_2020',
start_date=task_2020_start,
end_date=task_2020_end
)
common_start >> [task_1_2019, task_1_2020]
task_1_2019 >> task_2_2019
task_1_2020 >> task_2_2020
I set all of the date-like parts to have the most complete view of the DAG and avoid having any defaults set magically by Apache Airflow. After that, I enabled the DAG and few minutes later I had the result presented in the following picture:
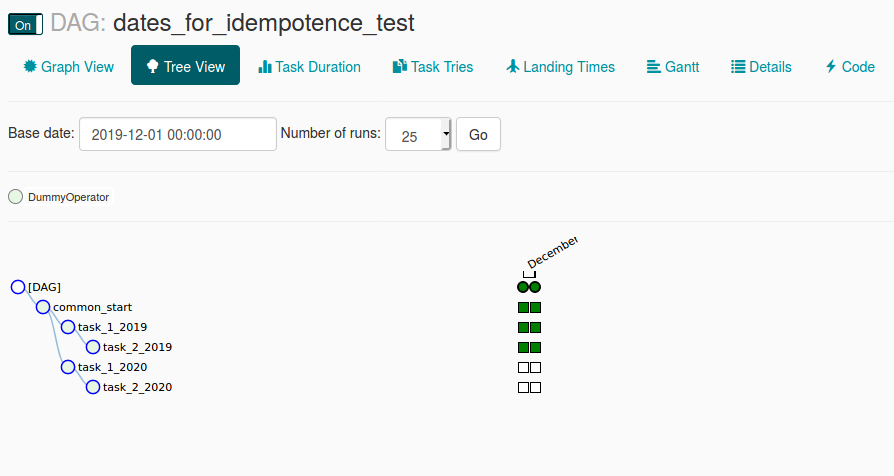
As you can see, it almost worked as expected? Why "almost"? Simply because the DAG won't execute for 2020 - these 2 DAGRuns are for 2019, so for the old processing logic. Why did it happen? The problem is located in SchedulerJob#create_dag_run method, and more exactly here:
# Don't schedule a dag beyond its end_date (as specified by the task params)
# Get the min task end date, which may come from the dag.default_args
min_task_end_date = []
task_end_dates = [t.end_date for t in dag.tasks if t.end_date]
if task_end_dates:
min_task_end_date = min(task_end_dates)
if next_run_date and min_task_end_date and next_run_date > min_task_end_date:
return
As you can see, the algorithm takes all end_date attributes of the tasks, independently on the branching. Later, it takes the smallest one and compares it against the next DAG run. It worked fine for 2019 since the smallest end_date was "2019-12-31T23:59:00" and obviously, it didn't work for 2020 since the DAGRun date was always bigger than the smallest end date of the tasks. In consequence, DAGRun for 2020 will never be created.
Ideally, but I'm saying that without having a deep knowledge of Apache Airflow internals (say me if I'm wrong), we should base the DAGRun creation on the DAG's end_date and if, and only if, this date is not set, use the end_dates of the tasks, but use the biggest one. In other words, the fact of triggering a task from start_date and end_date should be controlled at the task's instance level. However, the problem I see is that the start_date and end_date from the task don't have the same meaning as for DAG. They're used to compute the task execution time and end_date is always overridden to the current time:
# models/taskinstance.py
def handle_failure(self, error, test_mode=None, context=None, session=None):
self.end_date = timezone.utcnow()
def set_duration(self):
if self.end_date and self.start_date:
self.duration = (self.end_date - self.start_date).total_seconds()
else:
self.duration = None
To sum-up, my experience shows that it won't work as I expected, so any of 2 techniques listed in the first section should be considered as a solution for managing idempotence for DAG's logic changes.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about DAG evolution - using start_date and end_date? here:
Related blog posts:
- Apache Airflow 2 overview - part 2
- Apache Airflow 2 overview - part 1
- Dealing with time delta in Apache Airflow
Can we use start_date and end_date to version a DAG in #ApacheAirflow ? ? Not really. More details in my today's blog post https://t.co/tQzjmpm2ij
— Bartosz Konieczny (@waitingforcode) May 24, 2020