
Welcome to the 2nd blog post dedicated to Apache Airflow 2 features. This time it'll be more about custom code you can add to the most recent version.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Branch-time operators
The first feature concerns the branch operators. No, Apache Airflow 2 doesn't get rid of the BranchPythonOperator. Instead, the new release completes the scope with 2 time-sensitive branch operators called BranchDateTimeOperator and BranchDayOfWeekOperator.
They address relatively common scenarios where a DAG can behave differently and the behavior is conditioned by a time (e.g. job logic migration time). The new operators integrate this time dimension natively as parameters. For example, to define a time-based branch for BranchDateTimeOperator you simply need to define the boundary for one side of the branch and, of course, the DAG branches to follow after evaluating these boundaries:
processing_version_dispatcher = BranchDateTimeOperator(
task_id='processing_version_dispatcher',
follow_task_ids_if_true=['v1_process_raw_data_1', 'v1_process_raw_data_2'],
follow_task_ids_if_false=['v2_process_raw_data_1_and_2'],
target_lower=pendulum.datetime(2020, 10, 10, 15),
target_upper=pendulum.datetime(2022, 11, 7),
use_task_logical_date=True
)
Besides the time and task parameters you've certainly noticed the use_task_logical_date attribute. It's there to resolve the reference date the boundaries are evaluated against. If it's true, Airflow will use the execution time (so immutable). Otherwise, it'll take the real-time, so the value that changes when the DAGs get backfilled.
ExternalTaskMarker
The second feature simplifies inter-DAG dependencies management. It's not rare to find DAGs with ExternalTaskSensor where a downstream DAG waits for some important job to be done by the upstream DAG. Although this building pattern is valid, it becomes cumbersome at daily life mostly due to the reprocessing complexity.
The ExternalTaskMarker added in Apache Airflow 2 automatizes this reprocessing dependency. If it's present in the DAG and gets cleared, the scheduler will automatically trigger the computation of the dependent parts! For example, if I clean the generate_data task with its downstream dependencies, it'll automatically not only clean the ExternalTaskMarker but also bi_dashboard_refresher.data_generator_sensor:
with DAG(dag_id="data_generator", schedule='@daily', start_date=datetime(2022, 11, 4)) as data_generator_dag:
@task
def generate_data():
print('Generating data')
parent_task = ExternalTaskMarker(
task_id="dashboard_refresher_trigger",
external_dag_id="bi_dashboard_refresher",
external_task_id="data_generator_sensor",
)
generate_data() >> parent_task
data_generator_dag
with DAG(dag_id="bi_dashboard_refresher", schedule='@daily', start_date=datetime(2022, 11, 4)) as bi_dashboard_refresher_dag:
data_generator_sensor = ExternalTaskSensor(
task_id='data_generator_sensor',
external_dag_id='data_generator',
external_task_id='dashboard_refresher_trigger',
allowed_states=['success'],
failed_states=['failed', 'skipped'],
mode="reschedule",
)
@task
def refresh_dashboard():
print('Refreshing dashboard')
data_generator_sensor >> refresh_dashboard()
bi_dashboard_refresher_dag
The ExternalTaskMarker takes as a parameter the recursion_depth. It represents how many transitive dependencies are allowed.
Timetables
Two previous features are mostly about using the existing Apache Airflow components. The next one is different. Timetable is a way to extend the scheduling mechanism of Apache Airflow to overcome the "after-the-period" scheduling mode or implement schedules difficult to express with a CRON expression.
The first "after-the-period" problem is pretty well explained in the documentation. Basically, for a DAG executed during the weekday, the Friday's DAGRun is scheduled only before the next schedule, so by Monday.
The second point can be relevant for DAGs that need to be run at various hours each day. Such mode is difficult to express with a CRON expression but it's quite possible with custom code.
From the technical point of view, Timetable is an interface exposing 2 methods:
- infer_manual_data_interval - it generates the execution date for the manual trigger.
- next_dagrun_info - it generates the execution date for the scheduler trigger.
It's worth noting that the Timetable implementation must be exposed to the DAGs as a plugin. Therefore, you need to wrap it with an AirflowPlugin implementation, as I'm doing just below for a custom Timetable trigger:
class EndOfScheduleTimetablePlugin(AirflowPlugin):
name = "end_of_schedule_timetable_plugin"
timetables = [EndOfScheduleTimetable]
To use a timetable instead of a schedule expression, the DAG must contain the timetable attribute. You'll find an example of the declaration just below:
with DAG(dag_id="end_of_schedule_processor", start_date=pendulum.datetime(2022, 11, 14, tz="UTC"), catchup=True,
timetable=EndOfScheduleTimetable()) as end_of_schedule_processor_dag:
# ...
The Timetable implementation accesses DAG parameters from the restriction: TimeRestriction attribute. In my example, I'm raising an exception when the catch-up is disabled or the start_date misssing:
def next_dagrun_info(self, *, last_automated_data_interval: DataInterval | None, restriction: TimeRestriction,) \
-> DagRunInfo | None:
if last_automated_data_interval is None:
if restriction.earliest is None or not restriction.catchup:
raise Exception("EndOfScheduleTimetable doesn't support missing start_date and disabled catch-up")
# ...
Deferrable operators and sensors
Finally, there are also deferrable operators and sensors. In simple terms, they're daemon processes running in the asyncio event loop by a new component called triggerer. Thanks to this design, they're completely decorelated from the scheduler. As a result, they don't consume worker slots.
Previously, a big number of sensor tasks could consume all available worker slots making the progress impossible for the ready DAGs. Apache Airflow brings several deferrable alternatives out-of-the-box. The TimeDeltaSensorAsync can replace the TimeDeltaSensor whereas the DateTimeSensorAsync can be an alternative to DateTimeSensor. What's the difference? The execute(self, context: Context) method that doesn't implement the poke logic. Instead, it delegates its to the corresponding Trigger that yields the sensor readiness event and passes it to the method defined in the method_name parameter:
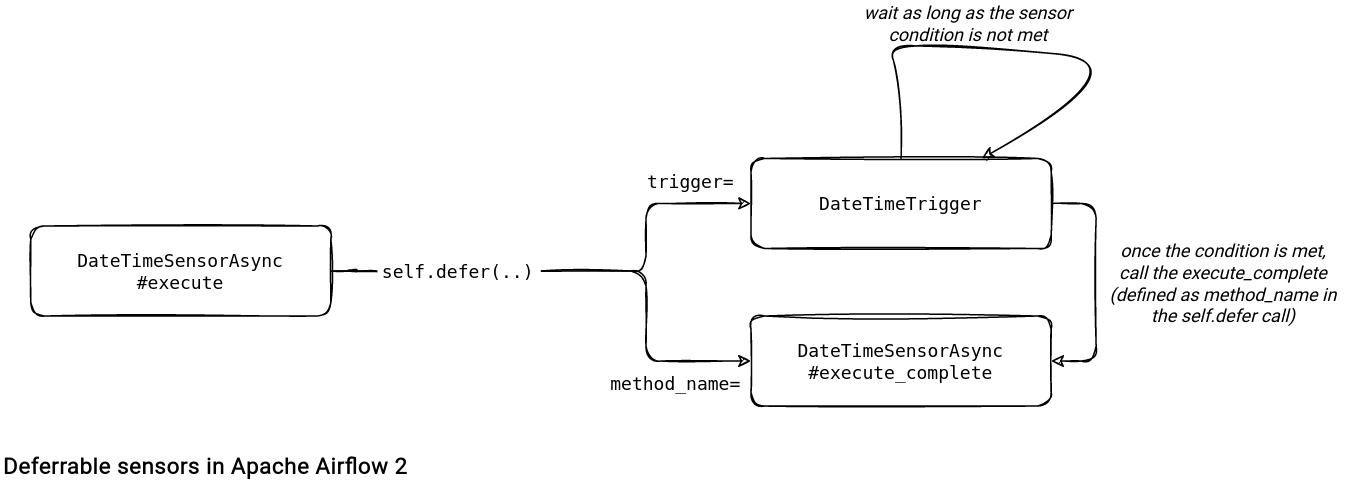
And if you need to define your own deferrable operator or sensor, you can also do it by implementing the required interface. A custom example waiting for Apache Spark _SUCCESS files is just below:
class SuccessFileTrigger(BaseTrigger):
def __init__(self, file_input_directory: str):
super().__init__()
self.file_found = False
self.file_input_directory = file_input_directory
self.file_to_wait_for = f'{file_input_directory}/_SUCCESS'
def _check_if_file_was_created(self):
logging.info(f'Checking if {self.file_to_wait_for} exists...')
if os.path.exists(self.file_to_wait_for):
logging.info('...found file')
self.file_found = True
else:
logging.info('...not yet')
async def run(self):
while not self.file_found:
self._check_if_file_was_created()
await asyncio.sleep(5)
yield TriggerEvent(self.file_to_wait_for)
def serialize(self) -> tuple[str, dict[str, Any]]:
return ("04_deferrable_operators.SuccessFileTrigger", {"file_input_directory": self.file_input_directory})
class SparkSuccessFileSensor(BaseSensorOperator):
template_fields = ['file_input_directory']
def __init__(self, file_input_directory: str, **kwargs):
super().__init__(**kwargs)
self.file_input_directory = file_input_directory
def execute(self, context: Context) -> Any:
self.defer(trigger=SuccessFileTrigger(self.file_input_directory), method_name='mark_sensor_as_completed')
def mark_sensor_as_completed(self, context: Context, event: str):
# event is the payload send by the trigger when it yields the TriggerEvent
return event
with DAG(dag_id="spark_job_data_consumer", schedule='@daily', start_date=datetime(2022, 11, 15)) as spark_job_data_consumer:
success_file_sensor = SparkSuccessFileSensor(
task_id='success_file_sensor',
file_input_directory='/tmp/spark_job_data/{{ ds_nodash }}',
)
Two blog posts can't cover all new features in Apache Airflow 2. The release brought much more, including the most visible changes as the one with the new UI or improved scheduler. However, it's time for me to cover other topics from the data landscape and eventually come back to Apache Airflow sometime in the future!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Apache Airflow 2 overview - part 1
- Dealing with time delta in Apache Airflow
- DAG evolution - using start_date and end_date?
Task-related changes are only a small part of the new features in #ApacheAirflow 2. There are more things, such as deferrable operators or timetables that I covered in the new blog post ? https://t.co/nkrhRuw0YO
— Bartosz Konieczny (@waitingforcode) December 11, 2022