
Have you written your first successful Apache Flink job and are still wondering the high-level API translates into the executable details? I did and decided to answer the question in the new blog post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
An Apache Flink DataStream API job moves through several stages before it can be physically executed. In a nutshell, these stages are represented in the schema below:

1: Java code to Stream graph
The first conversion translates the code you write to a stream graph. Let's analyze how.
Whenever you call an operator, you add it to an internal list of transformations present in a StreamExecutionEnvironment class. Below an example of the method called under-the-hood by the high-level map function:
public class StreamExecutionEnvironment implements AutoCloseable {
public void addOperator(Transformation<?> transformation) {
Preconditions.checkNotNull(transformation, "transformation must not be null.");
this.transformations.add(transformation);
}
All the transformations are converted into StreamNodes when you invoke the execute() function:
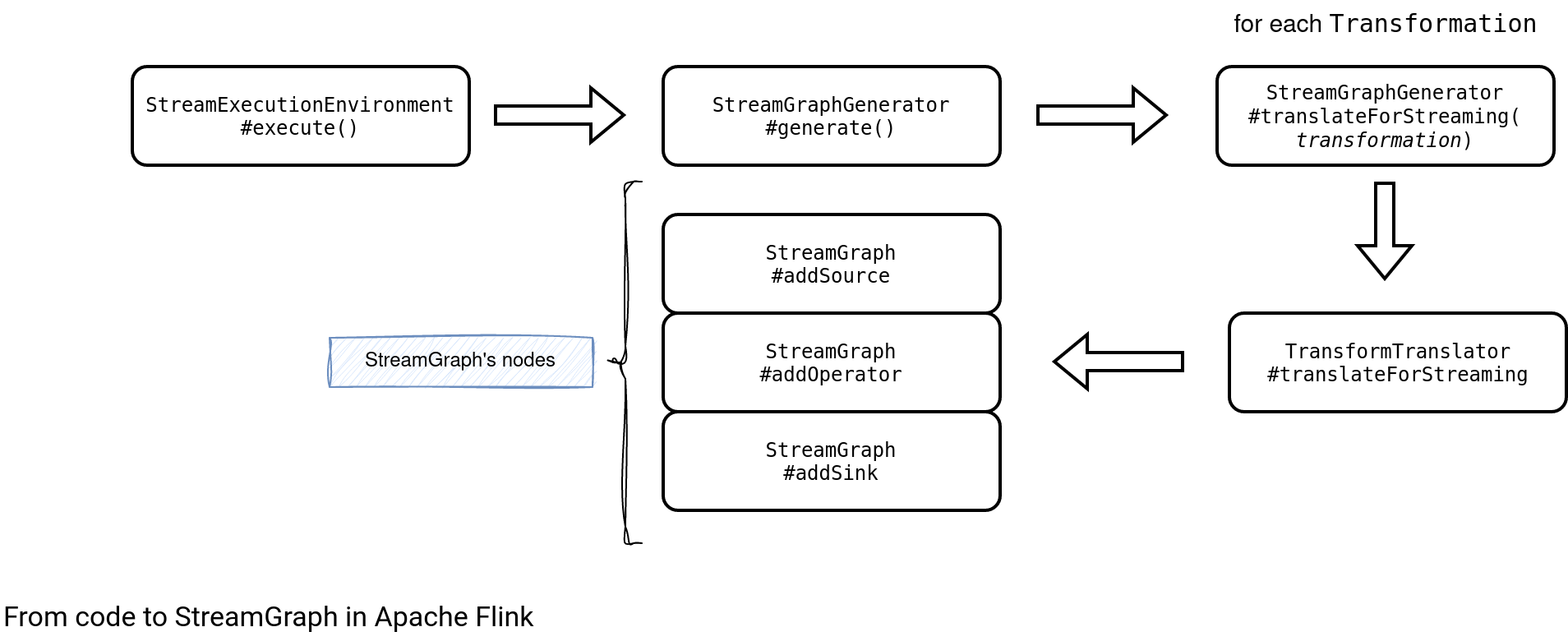
Internally, the StreamGraph stores the operator or their id in different structures:
public class StreamGraph implements Pipeline {
private Map<Integer, StreamNode> streamNodes;
private Set<Integer> sources;
private Set<Integer> sinks;
private Map<Integer, Tuple2> virtualSideOutputNodes;
private Map<Integer, Tuple3, StreamExchangeMode>>
virtualPartitionNodes;
public StreamNode getStreamNode(Integer vertexID) {
return streamNodes.get(vertexID);
}
The sources and sinks are used in the JSON plan generator while two last maps are involved in the StreamGraph creation. The streamNodes is the mapping of ids and StreamNodes used later to generate the job graph.
2: Stream graph to Job graph
The next step consists of translating the StreamNodes and StreamGraph to, respectively, JobVertex and JobGraph classes. The JobGraph is a low-level dataflow representation accepted by the JobManager. If you're familiar with Apache Spark, this second step can be considered as the logical plan optimization because it improves the high-level StreamGraph with various operations, such as combining multiple operators into a single one.

The StreamNode-to-JobVertex conversion happens in the StreamingJobGraphGenerator#createJobVertex method and consists of various steps:
- configuring the chaining operators - chaining in Flink means that an operator runs in the same thread to the predecessor. As a result, these multiple chained operators becomes one compose of multiple steps. It's a little bit like an Apache Spark's stage where multiple transformations are executed in the same processing unit. [?technically speaking, the createJobVertex is triggered while building the chain from the setChaining method]
- setting the resources specifications, such as the CPU, on-heap and off-heap memory, either preferred or minimal
- setting the invokable class which will be later called for the execution; the class is passed from the StreamNode directly here: jobVertex.setInvokableClass(streamNode.getJobVertexClass());
- defining the parallelism and the max parallelism
3: Job graph to Execution graph
So far we have only a logical optimized plan. In the next step Apache Flink transforms it into an execution graph which is the core data structure for the scheduling layer. What happens here?
The JobVertex instances get transformed into ExecutionVertex ones and the IntermediateDataSets into the IntermediateResultPartitions. Even though it looks familiar to the previous transformations, there is a major difference, the parallelism. The ExecutionGraph is a parallel version of the JobGraph. Put another way, the number of vertices is equal to the set parallelism. This structure is then a representation of what should physically run on the cluster.
The state of each ExecutionVertex is tracked by the Execution state class. Why is this needed? An ExecutionVertex can be executed multiple times, e.g. due to recovery, re-configuration, or re-computaion. The Execution state tracks all of these runtime contextes. Additionally, there is an ExecutionAttemptID associated with each Execution. This one provides a unique id for the task execution. Again, it can be retried or recovered.

At this step Apache Flink not only translates the JobGraph but also initializes other components involved in the stream processing, such as CheckpointCoordinator, CoordinatorStore, or yet KvStateLocationRegistry.
4: Execution graph to physical execution
In the final step the ExecutionGraph gets triggered on the cluster by JobManager. The physical unit representing so far presented nodes is Task. A quick look at the class members shows clearly this dependency:
public class Task {
/** The vertex in the JobGraph whose code the task executes. */
private final JobVertexID vertexId;
/** The execution attempt of the parallel subtask. */
private final ExecutionAttemptID executionId;
Task creation comes from the Executing class:
class Executing extends StateWithExecutionGraph implements ResourceConsumer {
private void deploy() {
for (ExecutionJobVertex executionJobVertex :
getExecutionGraph().getVerticesTopologically()) {
for (ExecutionVertex executionVertex : executionJobVertex.getTaskVertices()) {
if (executionVertex.getExecutionState() == ExecutionState.CREATED
|| executionVertex.getExecutionState() == ExecutionState.SCHEDULED) {
deploySafely(executionVertex);
}
}
}
}
private void deploySafely(ExecutionVertex executionVertex) {
try {
executionVertex.deploy();
} catch (JobException e) {
handleDeploymentFailure(executionVertex, e);
}
}
Once created and submitted to the cluster, a Task can be physically executed. The class implements the Runnable interface, hence its physical execution is in the implemented run method, where several things happen:
- task lifecycle state transition, including the transition to any final state involving the notification sent to the TaskManager
- initializing a TaskInvokable that holds the real computation logic executed by the Task. TaskInvokable is only an interface and a dedicated instance will be created for a particular task type. For streaming pipelines there will be the implementations of the StreamTask.
- calling the TaskInvokable's invoke() that starts the task code execution
- managing task shutdown if needed; the task is supposed to be long-running but it can stop because of a failure or cancellation
After relatively high-level blog posts about Apache Flink and first code lines written, it was time for me to start understanding the internal mechanism and discovering internal classes. It always helps me discover new software engineering best practices and also understand any exception messages a bit better.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Apache Flink - anatomy of a job here:
Related blog posts:
- Apache Flink vs. Apache Spark Structured Streaming - high-level comparison
- Data enrichment strategies in Apache Flink
- Apache Flink and the input data reading