
Previously you could read about transformation of a user job definition into an executable stream graph. Since this explanation was relatively high-level, I decided to deep dive into the final step executing the code.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In the blog post you will not see any high-level code snippet. Instead, I decided to analyze the internals and see what action Apache Flink performs since submitting the job to the cluster. To understand better what the article will be about, let me introduce this schema:
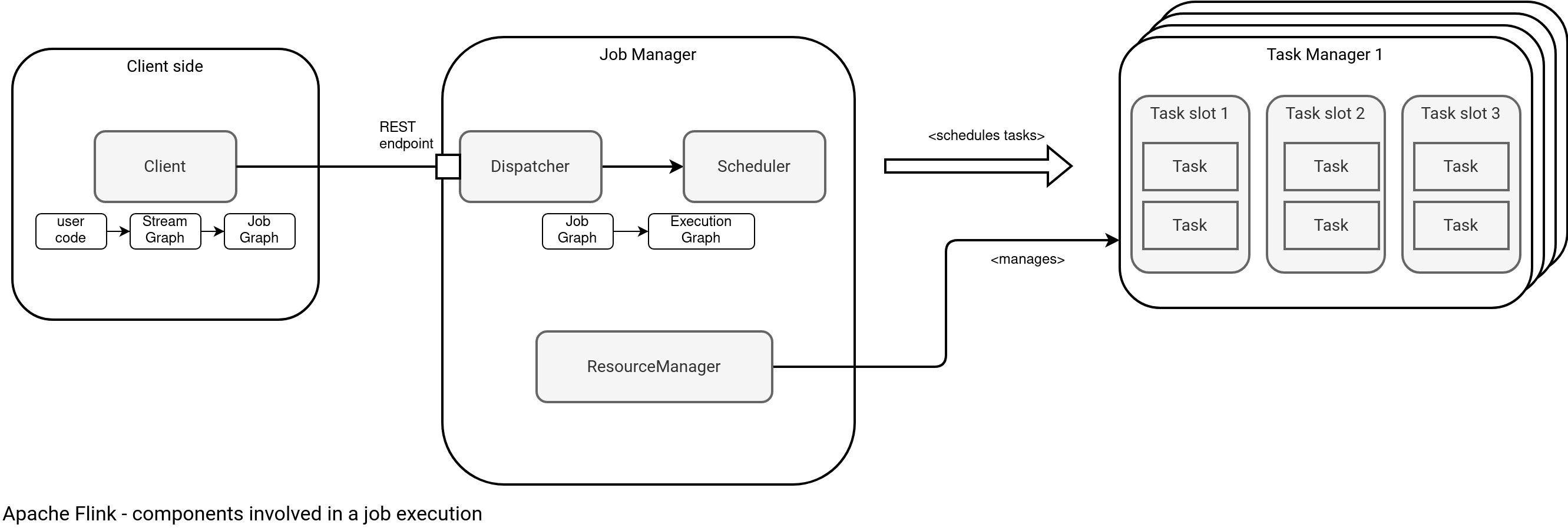
The schema shows main components involved in a Flink job execution that you're going to see in this blog post. Everything starts with the client side that I slightly explained in the Apache Flink - anatomy of a job. For that reason I won't spend much time on it today. Instead, I'll focus on the Job Manager and Task Manager, with their respective components depicted in the schema.
Dispatcher
The first component from the schema is Dispatcher. Dispatcher exposes a RESTful endpoint for job submission. It's then responsible for getting the JobGraph, transforming it into an ExecutionGraph, and scheduling on the cluster.
That's a high-level definition. If you deep delve into code, you'll notice the main Dispatcher abstract class with 2 possible implementations:
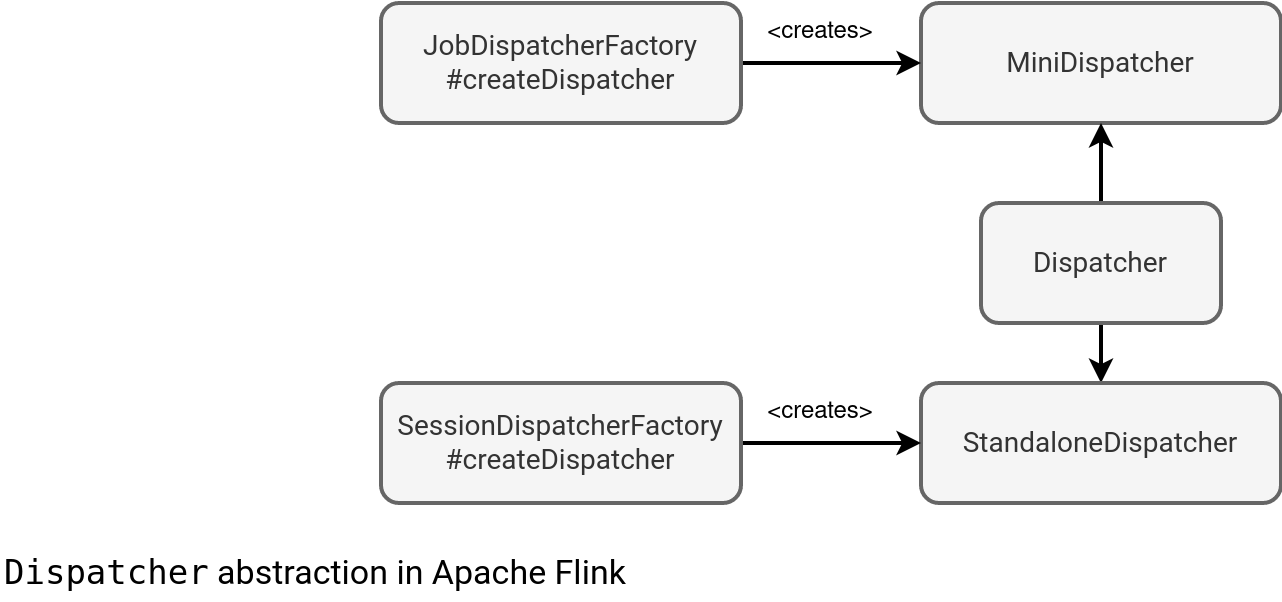
As you can see, there are 2 possible implementations with 2 possible execution paths. The prefix that has a special meaning for cluster types. Apache Flink supports:
- Per-Job Cluster where the created cluster is exclusive for the submitted job. Since Flink 1.15 it's called Flink Application Cluster (Flink Job Cluster before). The class responsible for it is ApplicationClusterEntryPoint.
- Session Cluster where multiple jobs run on the created instance of the JobManager. In Flink's nomenclature it's called Flink Session Cluster.
Scheduler
The second component living in the JobManager is Scheduler. As the name suggests, it's responsible for scheduling Flink jobs
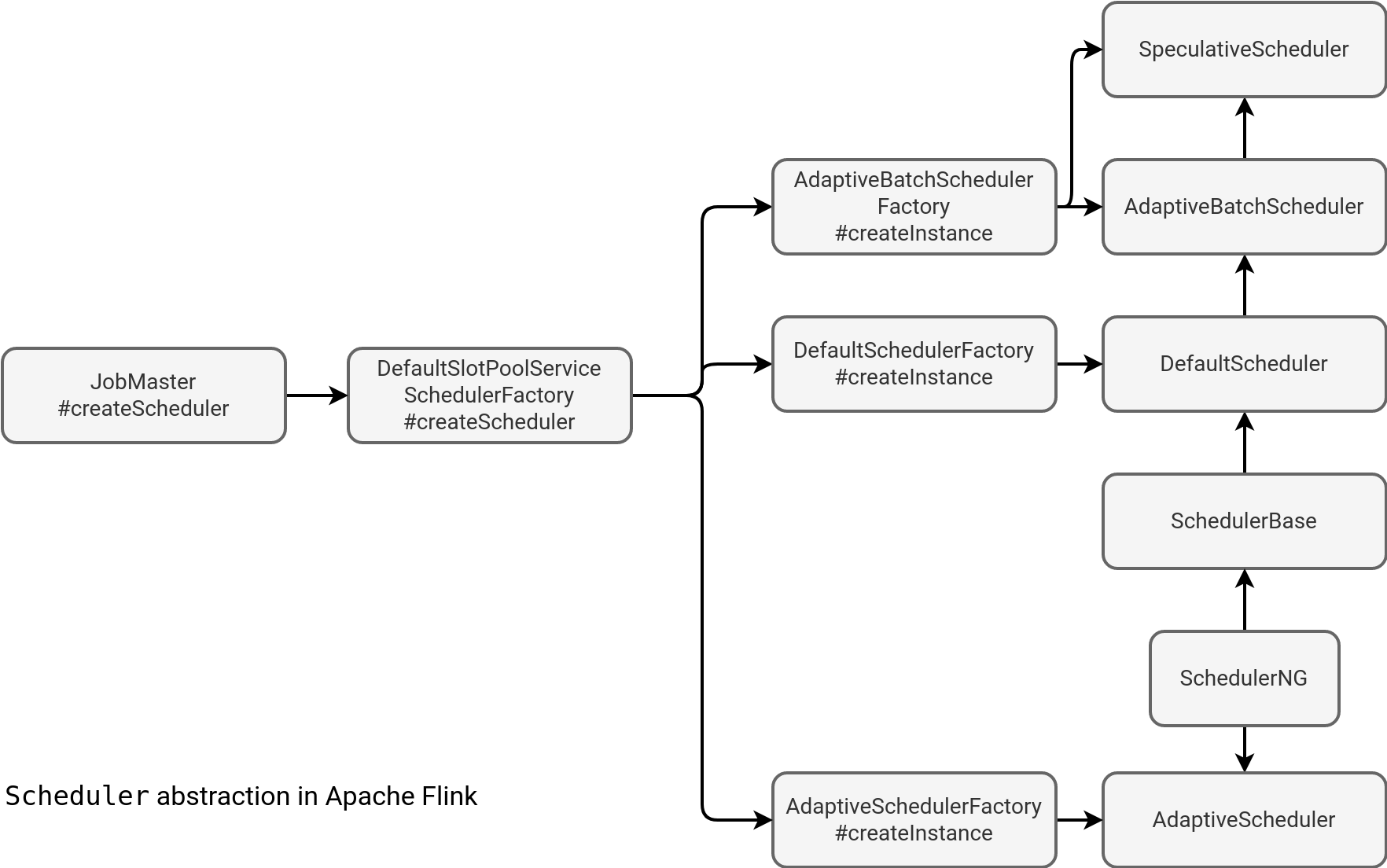
As for the Dispatcher, Scheduler also has various implementations that depend on the workflow. Among them you will find:
- AdaptiveScheduler that adapts the job parallelism to the available slots. It can then increase or decrease the parallelism level if, respectively, more or less resources are free.
- DefaultScheduler is the default scheduler without any extra features.
- AdaptiveBatchScheduler is the default scheduler for batch jobs. It inherits the adaptive behavior from the AdaptiveScheduler.
- SpeculativeScheduler is responsible for managing tasks in the Speculative Execution mode, i.e. when slowness of one or multiple tasks can trigger their respective speculative runs that might complete faster. It inherits from the AdaptiveBatchScheduler. The main difference is this function that gets called when one task completes. In case of any other runs, it'll kill them:
@Override protected void onTaskFinished(final Execution execution, final IOMetrics ioMetrics) { if (!isOriginalAttempt(execution)) { numEffectiveSpeculativeExecutionsCounter.inc(); } // cancel all un-terminated executions because the execution vertex has finished FutureUtils.assertNoException(cancelPendingExecutions(execution.getVertex().getID())); super.onTaskFinished(execution, ioMetrics); } private CompletableFuture<?> cancelPendingExecutions( final ExecutionVertexID executionVertexId) {
How Apache Flink knows what scheduler it should create? The answer comes from DefaultSlotPoolServiceSchedulerFactory#getSchedulerType where you'll find the logic following these conditions:
- If the job is of a batch type:
- AdaptiveBatchScheduler is used if one of these settings is true: scheduler-mode=reactive config or jobmanager.scheduler=adaptive.
- Otherwise, by default, the scheduler comes from the jobmanager.scheduler configuration. If the entry is missing, it uses AdaptiveBatchScheduler for dynamic graphs or DefaultScheduler.
- If the job is a streaming one:
- AdaptiveScheduler if the scheduler-mode=reactive
- Otherwise, by default, the scheduler comes from the jobmanager.scheduler configuration. If the entry is missing, it uses AdaptiveScheduler if flink.tests.enable-adaptive-scheduler is present among system properties, or DefaultScheduler.
Dynamic graphs
Dynamic graphs are properties of adaptive batch scheduler. The dynamic flag is set in the StreamGraphGenerator#setDynamic(StreamGraph) method:
private void setDynamic(final StreamGraph graph) {
Optional<JobManagerOptions.SchedulerType> schedulerTypeOptional =
executionConfig.getSchedulerType();
boolean dynamic =
shouldExecuteInBatchMode
&& schedulerTypeOptional.orElse(
JobManagerOptions.SchedulerType.AdaptiveBatch)
== JobManagerOptions.SchedulerType.AdaptiveBatch;
graph.setDynamic(dynamic);
}
In other words, the job automatically adapts the parallelism of the batch jobs. The Adaptive Batch Scheduler: Automatically Decide Parallelism of Flink Batch Jobs greatly explains the feature.
Besides scheduling, the Scheduler also creates an ExecutionGraph and managed tasks lifecycle with adequate onTaskX callbacks.
TaskManager
The next component is TaskManager. If you're familiar with Apache Spark, and probably most of the readers are, it corresponds to the executors. Therefore, it's a JVM and component responsible for physically executing tasks on the available task slots.
A task slot is a Thread within the TaskManager's JVM. It can run one or multiple tasks asynchronously (multi-threading). Their number impacts the number of concurrently executed tasks, exactly as for Spark's tasks availability. But do not get it wrong, a task slot can run multiple sub-tasks.
Slots bring another important point, the slot sharing. The feature lets different subtasks, even the ones coming from different tasks, share the same task slot. The documentation gives a pretty well detailed example:
It is easier to get better resource utilization. Without slot sharing, the non-intensive source/map() subtasks would block as many resources as the resource intensive window subtasks. With slot sharing, increasing the base parallelism in our example from two to six yields full utilization of the slotted resources, while making sure that the heavy subtasks are fairly distributed among the TaskManagers.
Knowing all this, let's see some internals. Surprisingly, you'll find out that TaskManager is not alone in the tasks execution process.
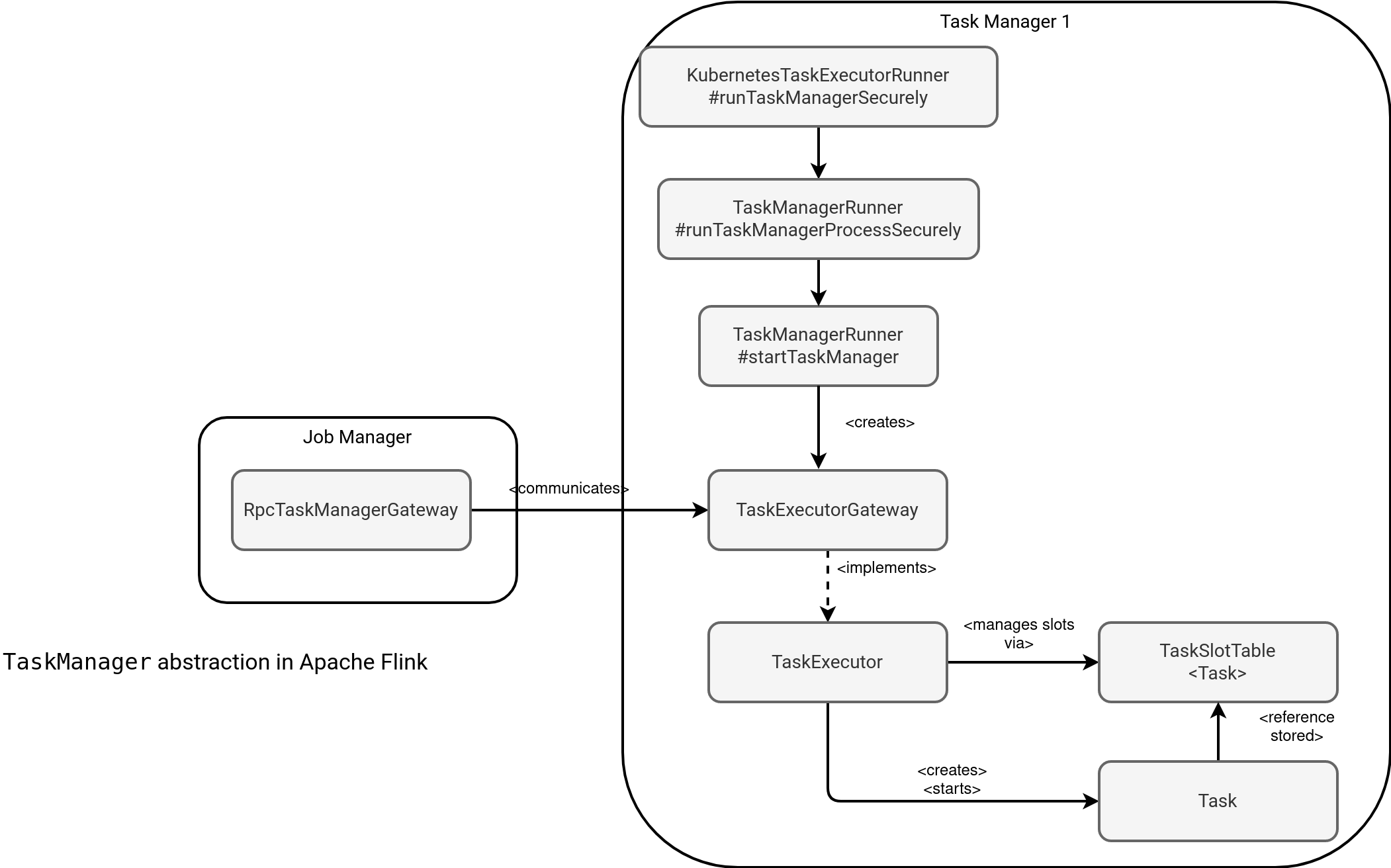
The schema above shows a lot of things. First, the TaskManager exposes a TaskExecutorGateway to communicate with JobManager for slots requests and tasks submission among other things. Internally, the TaskManager handles these requests from the TaskExecutor that keeps a map of slots with their statuses in an internal field represented by the TaskSlotTable<Task> instance. After getting an available slot, the TaskExecutor creates a Task instance [(1)], allocates it in the TaskSlotTable [(2)], and finally, starts the physical execution [(3)]:
@Override
public CompletableFuture<Acknowledge> submitTask(TaskDeploymentDescriptor tdd, JobMasterId jobMasterId, Time timeout) {
// ...
// (1)
Task task = new Task(jobInformation, taskInformation,
// ...
partitionStateChecker, getRpcService().getScheduledExecutor(),
channelStateExecutorFactoryManager.getOrCreateExecutorFactory(jobId));
// (2)
boolean taskAdded;
try {
taskAdded = taskSlotTable.addTask(task);
} catch (SlotNotFoundException | SlotNotActiveException e) {
throw new TaskSubmissionException("Could not submit task.", e);
}
// (3)
if (taskAdded) {
task.startTaskThread();
setupResultPartitionBookkeeping(
tdd.getJobId(), tdd.getProducedPartitions(), task.getTerminationFuture());
return CompletableFuture.completedFuture(Acknowledge.get());
// ...
Task and TaskInvokable
To complete this blog post, let's focus on the last abstraction, the Task. Technically, it brings a few other ones which are StreamTask and StreamOperator.
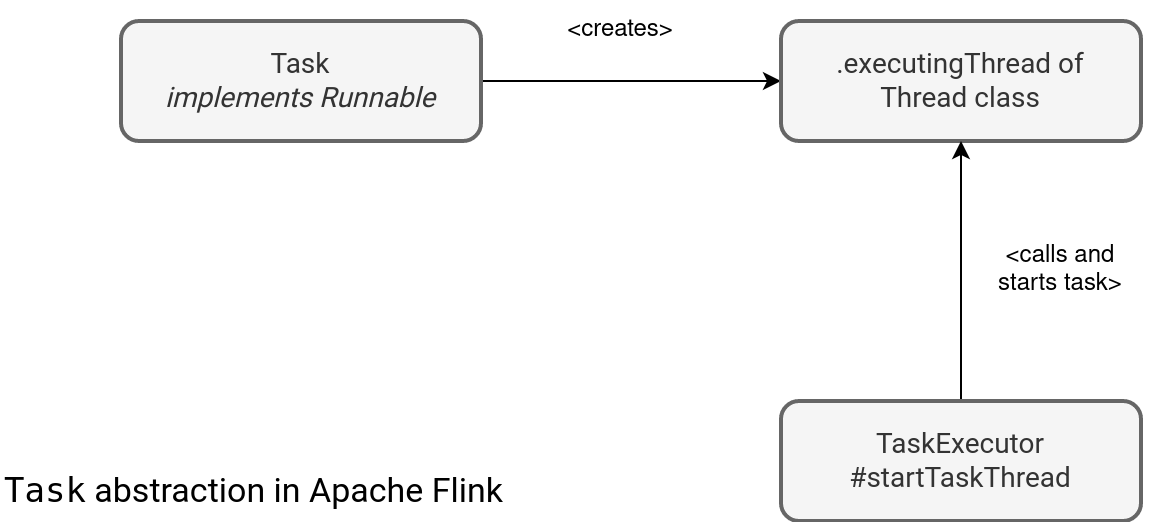
The key thing to understand the Task is in the schema above. Remember, TaskManager is a JVM that possibly runs multiple threads in the task slots. The schema clearly shows the thread execution unit as the Task class creates a Thread that gets called by the TaskExecutor. Since Task also implements the Runnable interface and is passed as a reference to the created Thread, the real task execution logic is defined in the run method:
/** The core work method that bootstraps the task and executes its code. */
@Override
public void run() {
try {
doRun();
} finally {
terminationFuture.complete(executionState);
}
}
private void doRun() {
// ...
Inside, the task first tries to transition to the DEPLOYING state that is required before it starts doing real work. Later, it performs some preparation and moves to the real computation:
try {
// now load and instantiate the task's invokable code
invokable = loadAndInstantiateInvokable(userCodeClassLoader.asClassLoader(), nameOfInvokableClass, env);
} finally {
FlinkSecurityManager.unmonitorUserSystemExitForCurrentThread();
}
this.invokable = invokable;
restoreAndInvoke(invokable);
Subtasks
As you can see in the code, there is no such a class as SubTask and all physical execution happens within the same Task instance, one which is a high-level interaction entrypoint with TaskManager, and second which is a low-level execution unit implementing the Runnable interface at the same time.
This snippet brings another concept, the TaskInvokable interface.
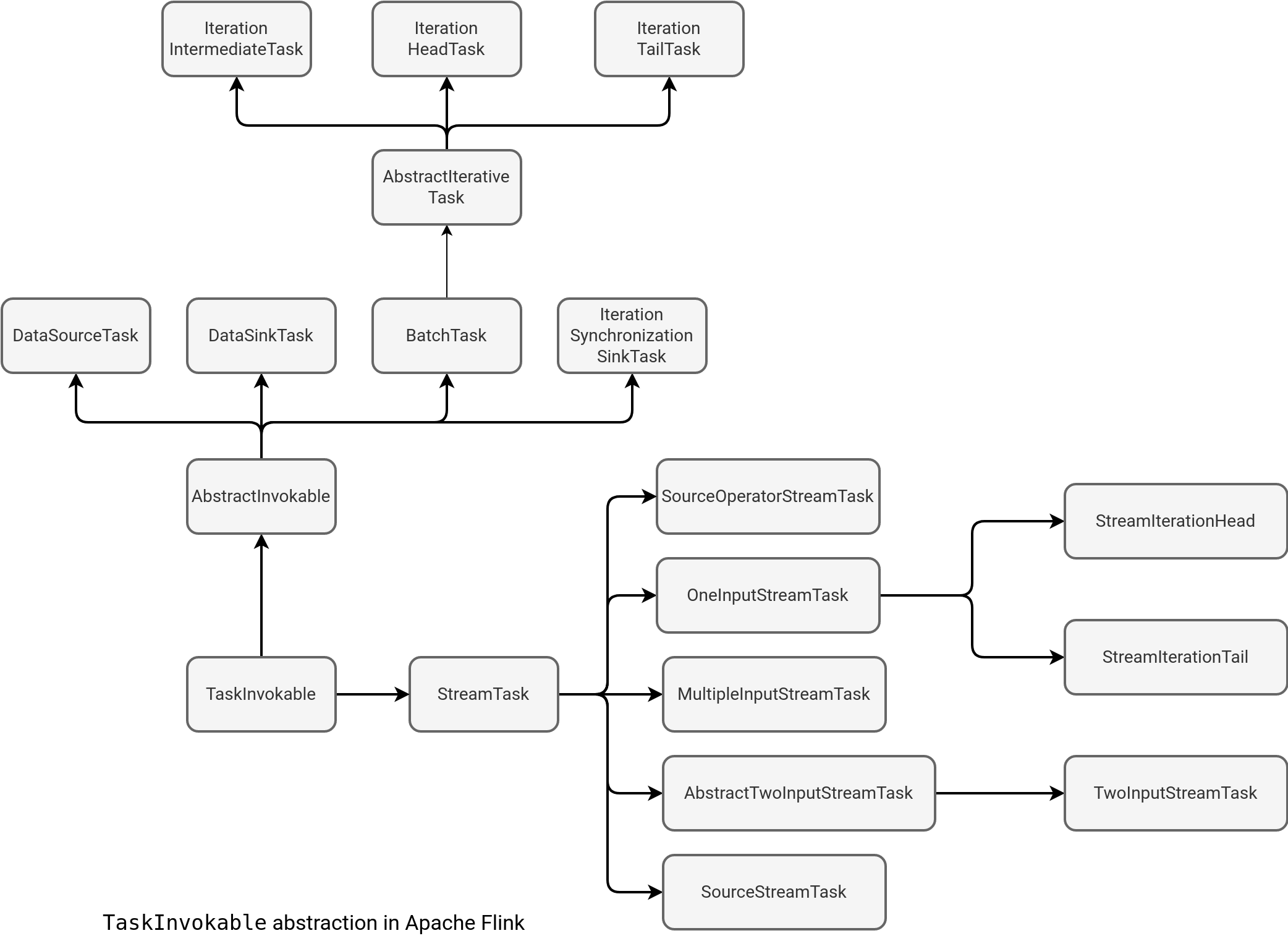
The interface has 2 branches, one dedicated to streaming tasks (StreamTask), and another where you will find tasks for batch pipelines.
TaskInvokable provides 2 important methods, the restore and invoke. The first one is used to recover the last valid state of a task whereas the second starts the real task execution.
At this moment I should have introduced stream operators but I'll dedicate a separate blog post to them. Hopefully now you, as me, are more aware of what happens under-the-hood when your Flink job runs.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Apache Flink and cluster components deep dive here:
Related blog posts:
- Apache Flink vs. Apache Spark Structured Streaming - high-level comparison
- Data enrichment strategies in Apache Flink
- Apache Flink and the input data reading