
Data enrichment is a crucial step in making data more usable by the business users. Doing that with a batch is relatively easy due to the static nature of the dataset. When it comes to streaming, the task is more challenging.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The blog post, even though it focuses on Apache Flink, presents general categories of various data enrichment approaches. And I didn't reinvent the wheel! Credits go to a wonderful 99 Ways to Enrich Streaming Data with Apache Flink webinar led by Konstantin Knauf .
TL;NR Whatever data enrichment strategy you choose, you'll be always paying in terms of network traffic or memory. There is no perfect solution but only ones better suited for a given problem.
External lookup
As any enrichment dataset lives in a data store, the external lookup is the easiest implementation. In this approach the streaming job interacts with the enrichment data store, as depicted below:
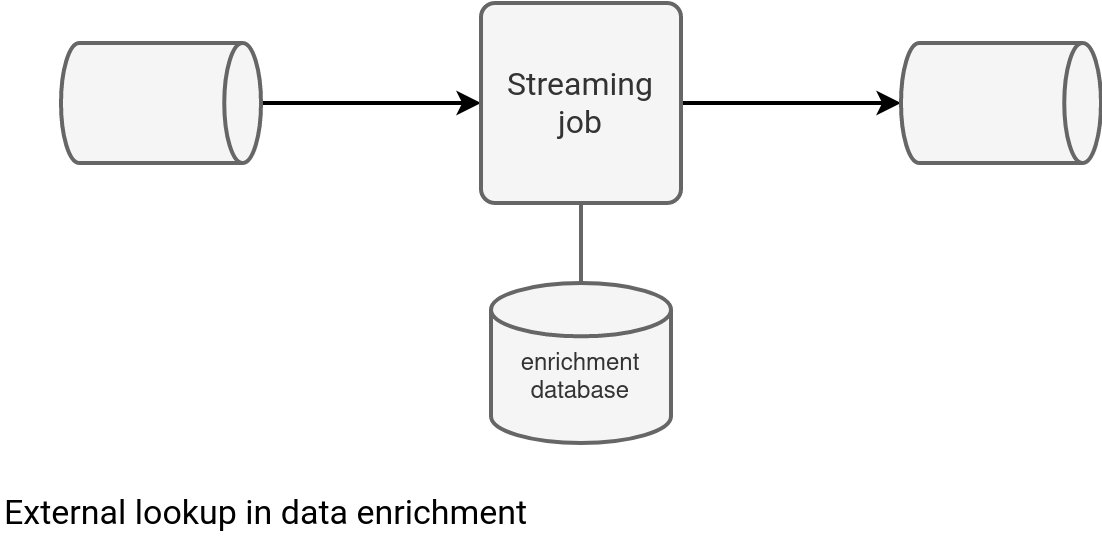
The solution has two important pros: simplicity and freshness. Simplicity because your enrichment process is just an implementation of the enrichment database's API or of its query language. Freshness because you interact with the database every time, meaning that you always get the most recent values. The pros automatically bring the cons. The simplicity involves costly network trips while the data freshness causes continuous load on the database.
The implementation in Apache Flink relies on the Rich* functions. Unlike the regular ones, they provide additional execution context plus the ability to manage the function's lifecycle. Let's see an example with the RichFunction interface shared by all implementations:
public interface RichFunction extends Function {
void open(Configuration parameters) throws Exception;
void close() throws Exception;
RuntimeContext getRuntimeContext();
IterationRuntimeContext getIterationRuntimeContext();
}
If you are familiar with Apache Spark, these rich functions are more like ForeachWriter that also provides the open/close steps where you can manage the database connection. After that, you can implement the enrichment process in a RichMapFunction.
However, a drawback of this approach is its synchronous character. As a result, each enrichment request will block until it gets a response. It leads to a poor throughput and increased latency. A better alternative than the synchronous rich functions are...asynchronous rich functions represented by the RichAsyncFunction class. Besides the classical open/close methods, they provide an asyncInvoke that you can leverage for an asynchronous data enrichment:
public abstract class RichAsyncFunction<IN, OUT> extends AbstractRichFunction
implements AsyncFunction<IN, OUT> {
public abstract void asyncInvoke(IN input, ResultFuture<OUT> resultFuture) throws Exception;
Local lookup
An alternative to the external lookup is the Local lookup. In this approach the enriched dataset is locally available, for example located in the manager's memory or available from disk:
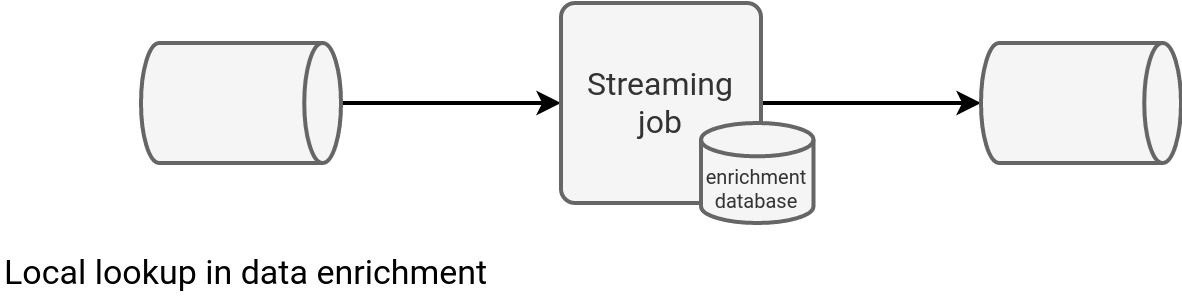
This strategy provides a better overall latency as the IO equation doesn't involve the network transfer anymore. But that's where the pros end. Even though you get a better throughput, you pay an extra price in the hardware for the enrichment dataset storage. Besides, you're exposed to integrating stale data. If you need a refresh mechanism, you should consider the reference dataset as a stream and work with the next described method.
Anyway, for the local lookup you can also leverage the Rich functions and use the open method for loading the whole or a part of the reference dataset.
Reference stream dataset
The third approach - remember, we're in the streaming world - consists of considering the reference dataset as a dynamic asset, i.e. as another streaming data source to process. A little bit like in the picture below:
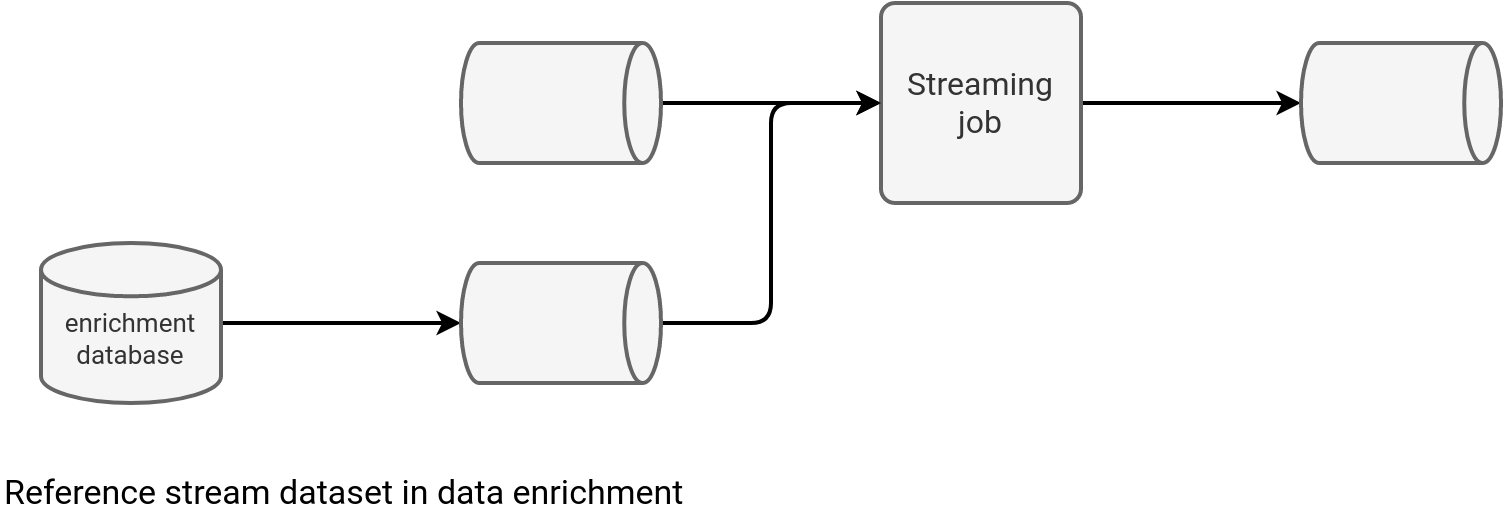
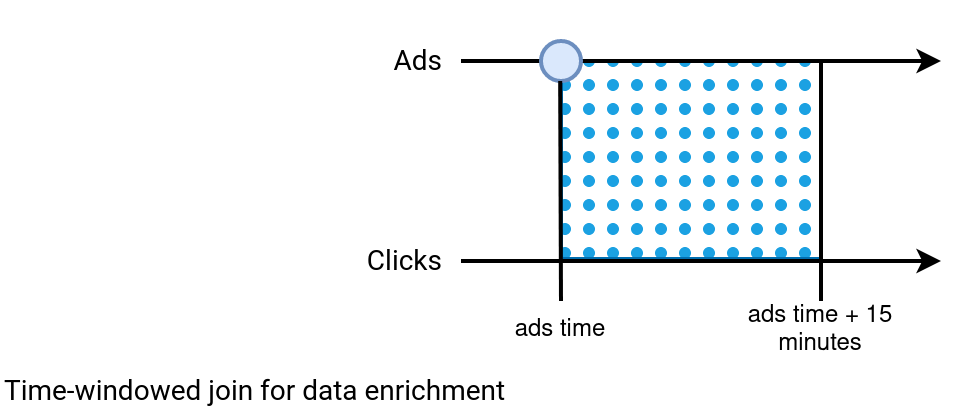
This solution addresses stale data issues from the previous approach but requires more advanced skills and understanding. First, the enrichment database may not be adapted to this use case. You might need some adaptation work to do beforehand, such as enabling streaming the table with a Change Data Capture pattern. Second, if the enrichment is implemented without any constraints, you'll end up having a big hardware pressure on your infrastructure anyway. For that reason often this kind of joins is defined as time-windowed joins where a given record is valid for enrichment only if it's within the accepted watermark. The schema below shows a simplified version where each ad from the Ads stream accepts a Click occurred at most 15 minutes after the ad impression:
Besides, Apache Flink also has another join solution relying on the stream of data called Temporal joins. The approach is based on Temporal tables (aka dynamic tables) that are an interesting concept by the way. They're dynamic, i.e. they never materialize, continuously evolve, and associate each row with at least one temporal period. A temporal table can have one of two different forms, either a changelog with all modifications recorded, or a latest snapshot with the most recent entry for a given key. Both tables are shown below for a blue event:
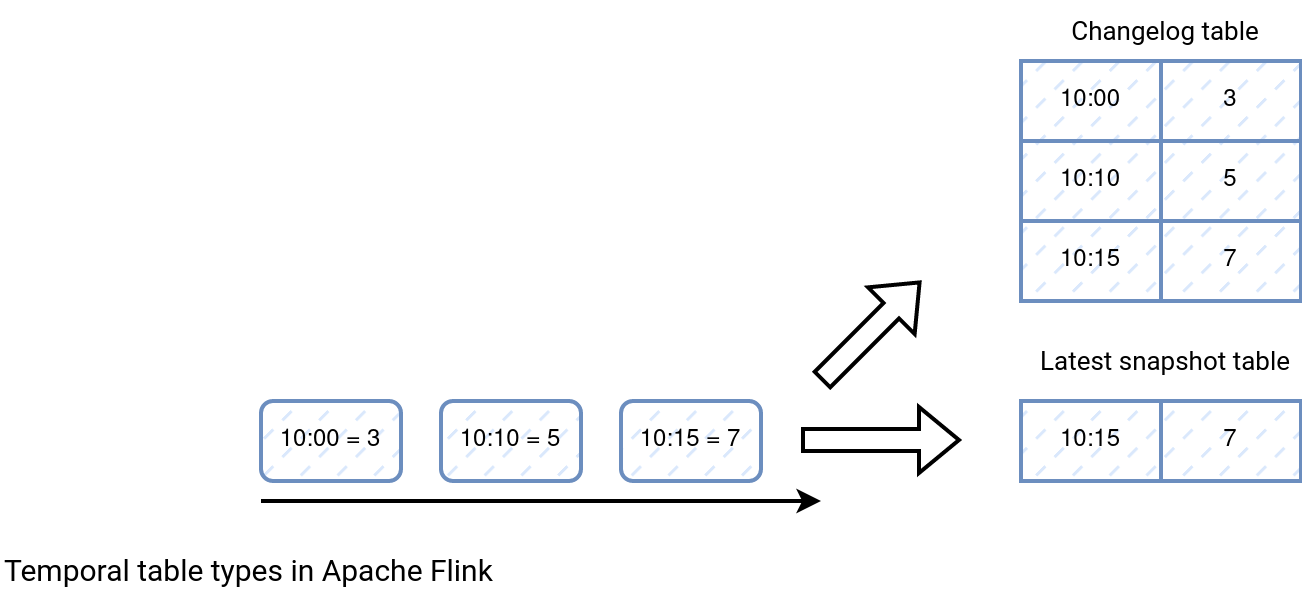
Temporal joins have processing time and event time flavors, and of course, they do support watermarks to avoid the underlying state growing indefinitely. If they're used with the changelog table version, the join will take the most recent entry from the enrichment table, as depicted in the next schema:
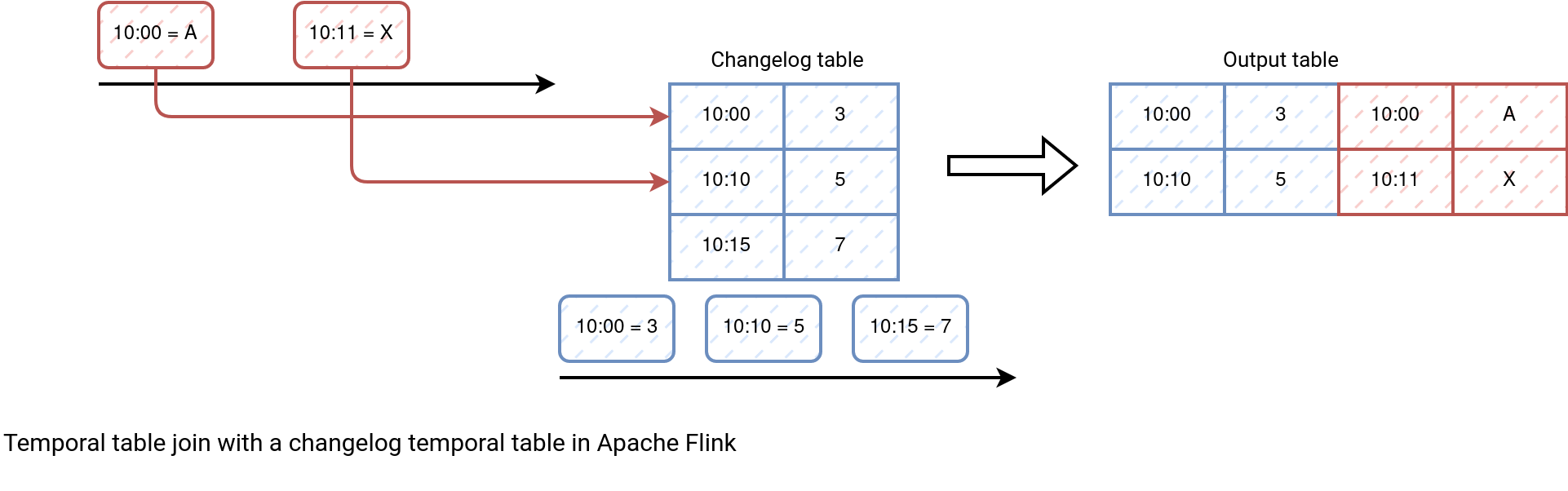
However, their setup requires some different skills than the ones covered so far for Apache Flink (DataStream API). Let's see this in the next section.
Temporal table join example
Let's see the temporal table join method in action. In our example we're going to enrich visits events with the ad configured for the visit page. It can't be expressed as a simple page-to-page join condition as a page has many different ads through its lifetime. Since our join must get the most recent configured ad, we can rely here on the temporal table join.
The method relies on the Table API, so the code starts with the tables declaration:
tableEnvironment.createTemporaryTable("visits_tmp_table", TableDescriptor.forConnector("kafka")
.schema(Schema.newBuilder()
.fromColumns(SchemaBuilders.forVisits())
.watermark("event_time", "event_time - INTERVAL '5' MINUTES")
.build())
.option("topic", "visits")
.option("properties.bootstrap.servers", "localhost:9094")
.option("properties.group.id", "visits-consumer")
.option("value.json.timestamp-format.standard", "ISO-8601")
.option("value.format", "json")
.option("properties.auto.offset.reset", "latest")
.build());
Table visitsTable = tableEnvironment.from("visits_tmp_table");
I'm omitting here the declaration of the ads table as besides different fields, it looks similar. Next comes the TemporalTableFunction definition that determines what is the versioning column (update_time for our ad) and the primary key (ad page):
TemporalTableFunction adsLookupFunction = adsTable.createTemporalTableFunction(
$("update_time"), $("ad_page"));
After this definition it's time to declare the join:
Table joinResult = visitsTable.joinLateral(call("adsLookupFunction",
$("event_time")), $("ad_page").isEqual($("page"))).select($("*"));
The join uses a joinLateral method to combine the visits with the rows produced by the adsLookupFunction. In the end, the job writes the output to the table defined similar way to the aforementioned visits:
joinResult.insertInto("visits_with_ads").execute();
How does it work? You can see a simulation as a picture below:
Enriching data is a frequent data engineering task but depending on your environment, one solution may fit better than another.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Data enrichment strategies in Apache Flink here:
- Webinar: 99 Ways to Enrich Streaming Data with Apache Flink - Konstantin Knauf Flink Forward San Francisco 2019: How to Join Two Data Streams? - Piotr Nowojski
Related blog posts:
- Apache Flink vs. Apache Spark Structured Streaming - high-level comparison
- Apache Flink and the input data reading
- Apache Flink and cluster components deep dive