
If you follow me, you know I'm an Apache Spark enthusiast. Despite that, I'm doing my best to keep my mind open to other technologies. The one that got my strong attention past years is Apache Flink and I found nothing better to start than comparing it with Apache Spark Structured Streaming.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Execution model
The execution models are different. Apache Spark Structured Streaming treats streaming data as micro-batches. Each micro-batch has its own stages, including: data to read planning, physical data retrieval, data processing, micro-batch commit with the metadata checkpoint and state store updates. If before writing your Structured Streaming pipelines you've done only batch, the micro-batch model should simplify the batch-to-streaming switch a lot.
Apache Flink on the other side relies on the Dataflow programming model that represents a Flink job as a set of streams and transformations, aka streaming dataflows. A stream is an unbound flow of events that gets processed by a transformation and transformed into another stream or written into the sink.
Even though both models look similar at first glance, they have one major difference that helps finding out the right use case for each framework. The micro-batch model - despite the initiated work on the continuous execution - is synchronous. It means that the next micro-batch can't start as long as the previous one doesn't finish. The Dataflow model is different because it treats each task a separate unit of work. As a result, they don't block each other.
Throttling
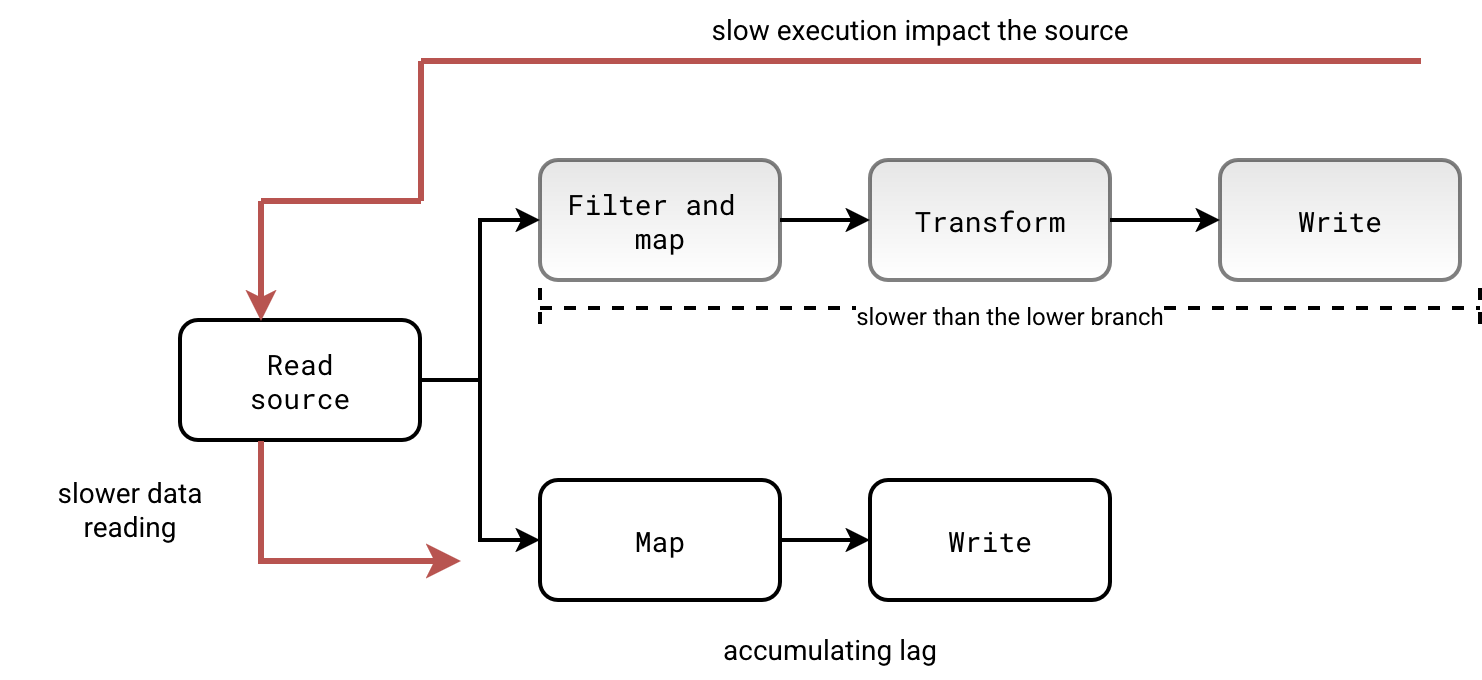
This continuous execution in the Dataflow model is a bit simplified. Technically speaking, Apache Flink can also suffer from a noisy neighbor problem. If one branch of the execution graph is slower than the rest, it may lead to throttling and slowing down the rest of the data flow. Following schema shows how a slow branch can reduce the reading throughput and lead to increased lag even for fast data processing:
Streaming semantics
They don't have the same meaning. Let's take an example of Triggers. Apache Spark uses them to define the execution frequency of each micro-batch. In Apache Flink, triggers control the data emission to the next stream or sink. Said like that, both look similar but that's only the appearance.
Due to the micro-batch execution model, Apache Spark triggers operate at the micro-batch level. Therefore, you can't apply them on individual operations of your query. It's possible to do in Apache Flink since it considers the job as a sequence of streams with operators.
Triggers are the first example that came to my mind but other aspects are different too. For example watermarks. In Apache Flink you can use them to filter out late data without having to write any aggregations. In Apache Spark you need to use them on queries with aggregations (Watermarks and not grouped query - why they don't work).
Late data
There is a dark and bright side of dealing with date data. On one hand, they appear as unnecessary details for beginners and probably a lot of the jobs can live without them. On the other hand, the inability to access them makes our lives harder, especially when you come to a project based on hacky solutions just to meet the business requirements.
One of such requirements is late data access. You may need it in different use cases. You may want to store it in a dedicated space for backfill batch jobs. You may need to process it in a dedicated task to avoid blocking the on-time delivery. Finally, you may need to simply count it and expose from your monitoring layer.
Capturing late data in Apache Flink is possible with a ProcessFunction evaluating each record against the watermark and sending the late ones to a dedicated stream via the side output. In Apache Spark it's automated and you can't access the records that were dropped by the watermark evaluator.
Customization
When it comes to customization, Apache Spark Structured Streaming provides a rich API that you can leverage to implement your business logic. Since recently there is also a possibility to define custom data source (cf. SPARK-46866) making the customization possible at the lowest levels of the framework.
However, this low-level customization is still reduced to what you can do with Apache Flink where besides business logic, you can leverage the high-level API to implement custom streaming primitives such as triggers or windows.
Fault-tolerance
Apache Spark Structured Streaming and Apache Flink are fault-tolerant. However, the definition is not the same. Apache Spark due to this micro-batch paradigm provides strong fault-tolerance, at least from the reasoning standpoint. Sure, you can still use the new asynchronous progress tracking to reduce the checkpoint overhead and gain some performance but it's still an option.
Apache Flink is by design different and more complex in my opinion. First, it doesn't have a single checkpoint but 2, the "normal" one and the "externalized" one. The difference is important. The normal checkpoint can be only used as a fault-tolerance mechanism within the running job. So if there is a task failure, it can help. On the other hand, you will need to configure an externalized checkpoint if you want to protect yourself against the job failure.
Besides the checkpoints, Apache Flink also has the savepoints that unlike checkpoints, can be triggered at demand. All this makes the whole checkpointing environment different and more complex but also more flexible because you can better control the deployment process, e.g. by creating a savepoint before releasing a new version of your application.
Transactions
Due to its batching nature, Apache Spark supports transactions for table file formats natively but it struggles with streaming brokers. Transactions in Apache Kafka are not yet supported and job failures can lead to partially written data to a topic.
Apache Flink is different. It integrates to Apache Kafka transactional producer with the 2 Phase Commit protocol.
Closing words
I'm not going to enter into a discussion over which one is better. They're both performing well in dedicated areas and contexts. So if you'll ever ask me, should I use Apache Spark Structured Streaming or Apache Flink, the answer will be, it depends 🙈
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩