
Surprised? You shouldn't. I've always been eager to learn, including 5 years ago when for the first time, I left my Apache Spark comfort zone to explore Apache Beam. Since then I had a chance to write some Dataflow streaming pipelines to fully appreciate this technology and work on AWS, GCP, and Azure. But there is some excitement for learning-from scratch I miss.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
PyFlink and jars
It's relatively easy to include external packages while constructing the SparkSession with the .config('spark.jars.packages', 'org.apache.spark:spark-sql-kafka-0-10_2.12:3.4.0'). PyFlink is different - and maybe because I misunderstood the idea - but you have to bring the JARs to your local environment and explicitly include in the execution environment:
env = StreamExecutionEnvironment.get_execution_environment(configuration=config)
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(2)
env.add_jars(
f"file://{os.getcwd()}/kafka-clients-3.2.3.jar",
f"file://{os.getcwd()}/flink-connector-base-1.17.0.jar",
f"file://{os.getcwd()}/flink-connector-kafka-1.17.0.jar"
)
PyFlink and classpath
The second failure is still related to PyFlink. When I started a job reading some Kafka data and decorating it with the processing time, I got this:
Caused by: java.lang.ClassCastException: cannot assign instance of org.apache.kafka.clients.consumer.OffsetResetStrategy to field org.apache.flink.connector.kafka.source.enumerator.initializer.ReaderHandledOffsetsInitializer.offsetResetStrategy of type org.apache.kafka.clients.consumer.OffsetResetStrategy in instance of org.apache.flink.connector.kafka.source.enumerator.initializer.ReaderHandledOffsetsInitializer
I was lost. Fortunately, I was not alone. After googling the issue, I had to add the following part to the configuration object to prefer loading classes from the application path:
config = Configuration()
config.set_string("classloader.resolve-order", "parent-first")
As a Python user I wasn't expected to deal with this kind of details, but lucky me, I have been working on JVM for 10+ years already and it rang a bell. However, I must admit dealing with that for non-JVM users will not be easy.
Not advancing watermark
But I've done it right! That was my thinking when I implemented my first tumbling event-time window. I defined a watermark strategy, wrote a timestamp assigner, but when I ran the code, the output wasn't generated. Worse, the watermark didn't advance. It was always set to the default Long.MIN_VALUE. What went wrong? The job's parallelism was higher than the partitions in the input Kafka topic...
How did I find that? I had to add some debug points and get some support from the UI. Only when I saw the "No Watermark (Watermarks are only available if EventTime is used" message I got the solution from here answer on StackOverflow.
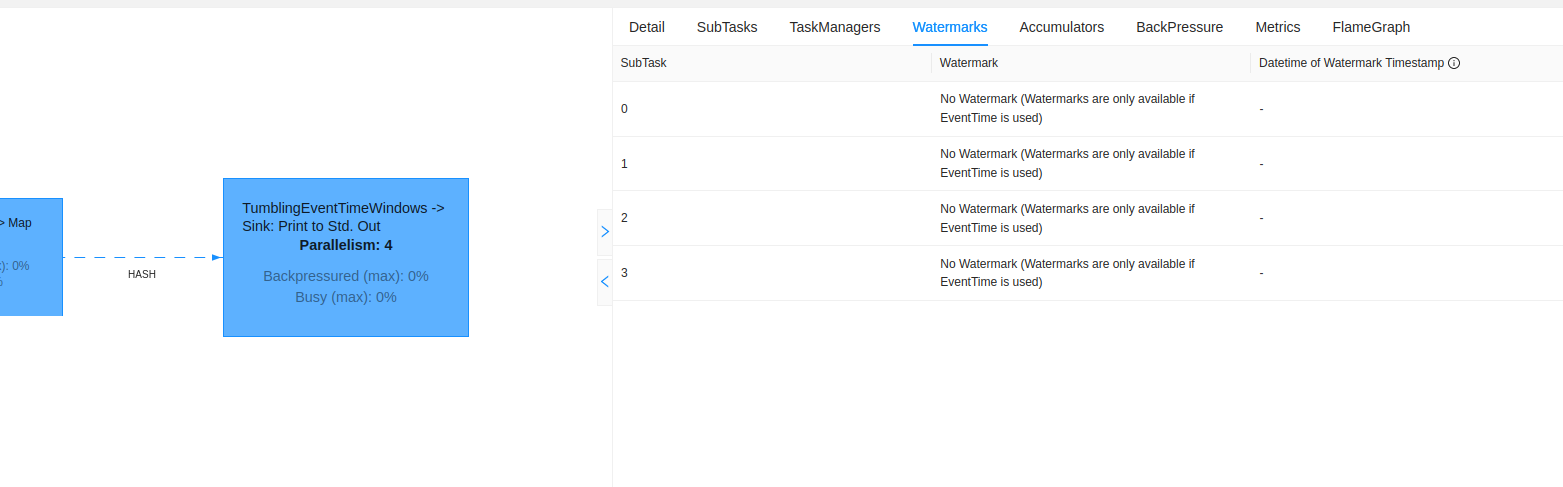
The reasons seems related to the idle partitions mentioned in FLINK-5479.
UI from IDE
When you launch an Apache Spark job locally you have access to the Spark UI interface without any extra manipulation. I expected the same for Apache Flink but turns out, it's a bit different here.
To enable the UI from your IDE you need to use a specific execution context...
Configuration conf = new Configuration(); StreamExecutionEnvironment localEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
...and include an extra Maven dependency:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-runtime-web</artifactId> <version>1.17.0</version> </dependency>
Despite this setup requirement, the UI is really nice, interactive and easy to navigate even for the beginners like me (of course, you must know what you are looking for)!
IDE-based learning experience
You know me, I like learning from simple IDE-based examples before going any further. I'm still doing that to understand new Apache Spark features by the way. I was hoping the same will be true for Apache Flink. Albeit it's true for maybe 90% scenarios, there are some others that require deploying a local cluster.
I learned that when I wanted to test job recovery from an externalized checkpoint. The recovery process is automatic in Apache Spark Structured Streaming but requires some specific setup in Apache Flink with the --fromSavepoint (aka -s) job submission parameter. Unfortunately, I haven't found a way to specify it at the code level so that I could still rely on the local execution environment.
But I must admit, setting up the local Docker environment was easy-peasy!
Job ID
I've rarely found any restrictions in Apache Spark, especially for the user input. It turns out Apache Flink has more validators for that part. It hit me when I wanted to launch a job with a custom job id. As a good data engineer who knows how to name things, I called my job "test1". Look what I got:
docker_jobmanager_1 | org.apache.flink.runtime.entrypoint.FlinkParseException: Failed to parse '--job-id' option
docker_jobmanager_1 | at org.apache.flink.container.entrypoint.StandaloneApplicationClusterConfigurationParserFactory.createFlinkParseException(StandaloneApplicationClusterConfigurationParserFactory.java:129) ~[flink-dist-1.17.1.jar:1.17.1]
docker_jobmanager_1 | at org.apache.flink.container.entrypoint.StandaloneApplicationClusterConfigurationParserFactory.getJobId(StandaloneApplicationClusterConfigurationParserFactory.java:123) ~[flink-dist-1.17.1.jar:1.17.1]
docker_jobmanager_1 | at org.apache.flink.container.entrypoint.StandaloneApplicationClusterConfigurationParserFactory.createResult(StandaloneApplicationClusterConfigurationParserFactory.java:91) ~[flink-dist-1.17.1.jar:1.17.1]
docker_jobmanager_1 | at org.apache.flink.container.entrypoint.StandaloneApplicationClusterConfigurationParserFactory.createResult(StandaloneApplicationClusterConfigurationParserFactory.java:45) ~[flink-dist-1.17.1.jar:1.17.1]
docker_jobmanager_1 | at org.apache.flink.runtime.entrypoint.parser.CommandLineParser.parse(CommandLineParser.java:51) ~[flink-dist-1.17.1.jar:1.17.1]
docker_jobmanager_1 | at org.apache.flink.runtime.entrypoint.ClusterEntrypointUtils.parseParametersOrExit(ClusterEntrypointUtils.java:70) [flink-dist-1.17.1.jar:1.17.1]
docker_jobmanager_1 | at org.apache.flink.container.entrypoint.StandaloneApplicationClusterEntryPoint.main(StandaloneApplicationClusterEntryPoint.java:58) [flink-dist-1.17.1.jar:1.17.1]
docker_jobmanager_1 | Caused by: java.lang.IllegalArgumentException: Cannot parse JobID from "test1". The expected format is [0-9a-fA-F]{32}, e.g. fd72014d4c864993a2e5a9287b4a9c5d.
Casting issues for a dummy string!
I wouldn't expect to have any issues with primitive types like string for my Flink Python jobs. Unfortunately, the unexpected hit me again with the errors like that when I was trying to deliver some stringified json to Kafka:
Caused by: org.apache.flink.streaming.runtime.tasks.ExceptionInChainedOperatorException: Could not forward element to next operator
at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.pushToOperator(CopyingChainingOutput.java:89) ~[flink-dist-1.17.0.jar:1.17.0]
at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:50) ~[flink-dist-1.17.0.jar:1.17.0]
at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:29) ~[flink-dist-1.17.0.jar:1.17.0]
at org.apache.flink.streaming.api.operators.TimestampedCollector.collect(TimestampedCollector.java:51) ~[flink-dist-1.17.0.jar:1.17.0]
at org.apache.flink.streaming.api.operators.python.process.collector.RunnerOutputCollector.collect(RunnerOutputCollector.java:52) ~[?:?]
at org.apache.flink.streaming.api.operators.python.process.AbstractExternalOneInputPythonFunctionOperator.emitResult(AbstractExternalOneInputPythonFunctionOperator.java:133) ~[?:?]
at org.apache.flink.streaming.api.operators.python.process.AbstractExternalPythonFunctionOperator.invokeFinishBundle(AbstractExternalPythonFunctionOperator.java:100) ~[?:?]
at org.apache.flink.streaming.api.operators.python.AbstractPythonFunctionOperator.checkInvokeFinishBundleByTime(AbstractPythonFunctionOperator.java:300) ~[?:?]
at org.apache.flink.streaming.api.operators.python.AbstractPythonFunctionOperator.lambda$open$0(AbstractPythonFunctionOperator.java:118) ~[?:?]
at org.apache.flink.streaming.runtime.tasks.StreamTask.invokeProcessingTimeCallback(StreamTask.java:1713) ~[flink-dist-1.17.0.jar:1.17.0]
... 14 more
Caused by: java.lang.ClassCastException: [B cannot be cast to java.lang.String
at org.apache.flink.api.common.serialization.SimpleStringSchema.serialize(SimpleStringSchema.java:36) ~[flink-dist-1.17.0.jar:1.17.0]
at org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchemaBuilder$KafkaRecordSerializationSchemaWrapper.serialize(KafkaRecordSerializationSchemaBuilder.java:312) ~[?:?]
at org.apache.flink.connector.kafka.sink.KafkaWriter.write(KafkaWriter.java:196) ~[?:?]
at org.apache.flink.streaming.runtime.operators.sink.SinkWriterOperator.processElement(SinkWriterOperator.java:158) ~[flink-dist-1.17.0.jar:1.17.0]
at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.pushToOperator(CopyingChainingOutput.java:75) ~[flink-dist-1.17.0.jar:1.17.0]
at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:50) ~[flink-dist-1.17.0.jar:1.17.0]
at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:29) ~[flink-dist-1.17.0.jar:1.17.0]
I was surprised because I correctly defined the value serializers. Turns out I was missing the type descriptor for the mapping function. The working code should be then:
# MyTestWindowProcessor returns strings
window_output: DataStream = records_per_letter_count.process(MyTestWindowProcessor(), Types.STRING()).uid("window output")
kafka_sink = KafkaSink.builder().set_bootstrap_servers("kafka:9092") \
.set_record_serializer(KafkaRecordSerializationSchema.builder()
.set_topic(get_output_topic()) \
.set_value_serialization_schema(SimpleStringSchema()).build()) \
.set_delivery_guarantee(DeliveryGuarantee.AT_LEAST_ONCE).build()
Name everything
As far as I have understood Apache Flink so far, it relies on a different checkpoint mechanism than Apache Spark Structured Streaming and this somehow implies the job structure. It turns out, it's recommended to assign a unique id to each state operator. Stateful operators can be restored from the savepoint/checkpoint only when their names correspond.Otherwise, you will get the exception like this one when you try to restore an incompatible state:
docker_jobmanager_1 | Caused by: org.apache.flink.client.deployment.application.ApplicationExecutionException: Could not execute application. docker_jobmanager_1 | ... 14 more docker_jobmanager_1 | Caused by: org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: Failed to execute job 'counter'. docker_jobmanager_1 | ... 13 more // ... docker_jobmanager_1 | Caused by: java.util.concurrent.CompletionException: java.lang.IllegalStateException: Failed to rollback to checkpoint/savepoint file:/checkpoints_flink/fd72014d4c864993a2e5a9287b4a9c5d/chk-6. Cannot map checkpoint/savepoint state for operator cbc357ccb763df2852fee8c4fc7d55f2 to the new program, because the operator is not available in the new program. If you want to allow to skip this, you can set the --allowNonRestoredState option on the CLI.
It's only the beginning but I'm not leaving Apache Spark! I hope to leave my comfort zone for a bit and learn something completely new with the goal to write better Structured Streaming pipelines in the future. There are so many great Apache Flink features that I miss in the Vanilla Apache Spark, including the triggers API, late data capture, side outputs, scalable state or stable continuous mode. Hopefully I'll be able to understand them in Flink and who knows, maybe find in future Apache Spark releases?
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Apache Flink vs. Apache Spark Structured Streaming - high-level comparison
- Data enrichment strategies in Apache Flink
- Apache Flink and the input data reading
Current status: exploring #ApacheFlink for the first time and being hit by some beginner's issues ? Just in case I get them in the future, I wrote a blog post. It may be helpful if you want to start with the framework ? https://t.co/WzWhGwDzIH
— Bartosz Konieczny (@waitingforcode) June 30, 2023