
I didn't plan to write this post at all. However, when I was analyzing the idempotent producer, it was hard to understand out-of-sequence policy for multiple in-flight requests without understanding what this in-flight requests parameter really means.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
After 2 previous posts about NIO Selector and its implementation in Apache Kafka, it's time to go a little bit higher and focus on one of the producer properties called in-flight requests.This property is configured on the producer side by max.in.flight.requests.per.connection property. The connection here is understood as the broker and thus, this property represents the number of not processed requests that can be buffered on the producer's side. It was introduced to minimize the waiting time of the clients by letting them send requests even though some of the prior ones are still processed by the broker.
In 2 sections I will explain how the producer manages them. In the first part, I will introduce the creation of batches. In the next one, I will show how the producer handles retries to help you understand how it's possible to produce duplicates.
Batches creation
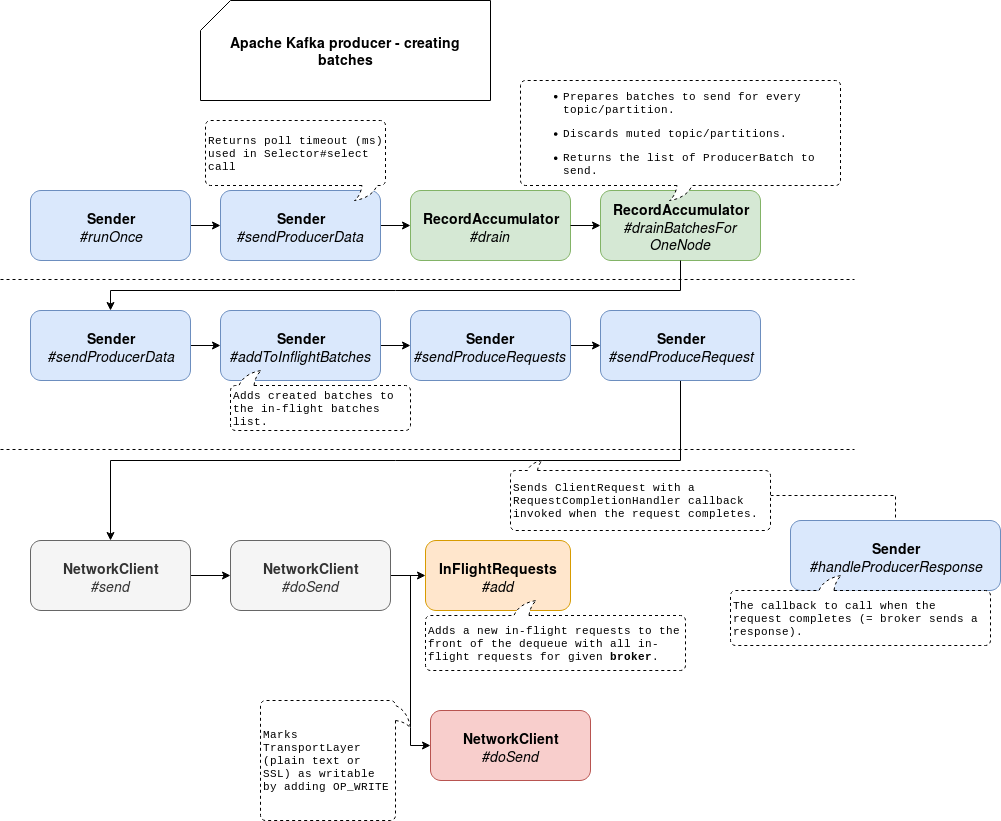
Producer creates batches in iterations, one long-running method on its side calls runOnce() method every time. Every iteration does many things but in the context of this blog post the most important ones are the communication with the broker (input/output) and retries management in case of failures.
Before I introduce the classes involved in batches creation, I'd like to highlight the fact that I make this analysis for a non-transactional producer with in-flight requests higher than 1. So, as I said in the previous paragraph, everything starts with Sender's runOnce method. Internally, it initializes draining process on RecordAccumulator side. The draining consists simply on preparing batches to send per topic/partition basis.
Once all batches to send are returned, they're added to an internal map of in-flight batches on the Sender's side. Every batch has a callback which will be called when the broker will return a response to the client's request. This callback is responsible for handling the response and figuring out the outcome of the communication (success, retryable error, not retryable error, ...).
After that, the Sender delivers the batches. To do so, it gives the list of batches to the NetworkClient which:
- adds the batches to an instance of InFlightRequests storing all requests currently being sent or already sent but awaiting a response. Unlike in-flight batches list from the Sender, InFlightRequests object controls whether a new in-flight request can be added for given broker. So it's here where the parameter I introduced at the beginning of the post is used:
public boolean canSendMore(String node) { Deque<NetworkClient.InFlightRequest> queue = requests.get(node); return queue == null || queue.isEmpty() || (queue.peekFirst().send.completed() && queue.size() < this.maxInFlightRequestsPerConnection); } - marks the SocketChannel associated with given broker as ready to send messages by adding SelectionKey.OP_WRITE to the keys of its interest
The following schema summarizes all steps listed before:
Handling failed requests
Batches creation doesn't mean the direct delivery. The communication with the broker consists in calling NetworkClient's poll(timeout, now) method where all I/O actions happen. And that's also here where broker responses are processed, in the callbacks introduced previously. The responses are returned by the server in order, so if the client sends requests 1, 2, 3, it will receive the responses in the same order. I haven't covered network server-side yet but already in the documentation, you can learn about that guarantee:
The maximum number of unacknowledged requests the client will send on a single connection before blocking. Note that if this setting is set to be greater than 1 and there are failed sends, there is a risk of message re-ordering due to retries (i.e., if retries are enabled).
So what will happen if one of the in-flight requests fails? To see that, let's analyze what happens when the client gets a new response from the server. Everything happens in NetworkClient's poll method where different types of exchanges are processed (new connections, disconnections, time-out requests). The ones that are appropriate for our problem are managed in handleCompletedReceives method. Inside the client iterates over the data received from the server and completes the oldest request. That request is removed from the deque storing all in-flight requests and here the magic things happen:
- First, the response's body is parsed. During the parsing, the client uses a correlation id to verify if the response corresponds to the request. If it's not the case, the errors like Correlation id for response (475734766) does not match request (475734763) may happen. But for most of the cases, it won't occur since the server processes requests in order of sending and that order is kept in the in-flight requests deque.
- After a successful parsing, the response will be added to an internal list with all responses received from the server. That list will be later passed to a method called completeResponses:
private void completeResponses(List<ClientResponse> responses) { for (ClientResponse response : responses) { try { response.onComplete(); } catch (Exception e) { log.error("Uncaught error in request completion:", e); } } }
As you can see, the response invokes the callback method introduced in the previous section. And that callback for our case of writing records will be handleProduceResponse method from Sender class. Inside this method, the Sender will handle different use cases like disconnection and API version mismatch. It will also handle batches writing. Here too, there are different cases but let's focus on the one corresponding to this post, retries without a transaction.
The retry consists in calling reenqueueBatch that will add the failed batch at the beginning of the batches dequeue:
public void reenqueue(ProducerBatch batch, long now) {
batch.reenqueued(now);
Dequel<ProducerBatch> deque = getOrCreateDeque(batch.topicPartition);
synchronized (deque) {
if (transactionManager != null)
insertInSequenceOrder(deque, batch);
else
deque.addFirst(batch);
}
}
The same method will also remove the failed batch from the in-flight batches list for a given partition. Thanks to that it will be readded to the list at the next execution of sendProducerData method. It will also avoid duplicated send of the same request.
To sum-up, the interaction schema looks like that:
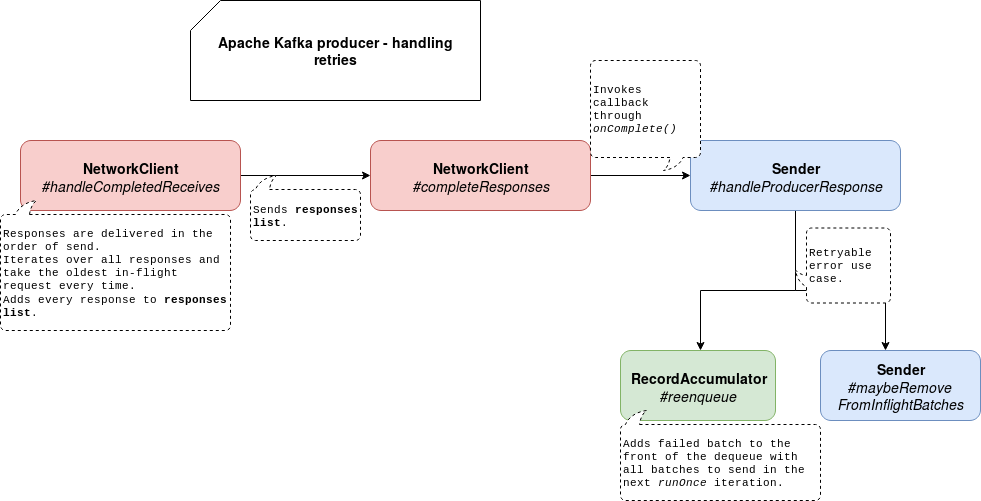
In consequence of these 2 actions, the failed batch will always be added to the head of the deque. So, even if you have at most 1 in-flight request allowed per broker it's not a big deal since you will always retry the same batch.
And that's globally why, if multiple in-flight requests are allowed, the data can be stored unordered on the broker. I gave a lot of (only?) internals details intending to help you to understand my next post from Apache Kafka series about the idempotent producer. And to stay simple, I didn't cover transactional generation here.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Apache Kafka and max.in.flight.requests.per.connection here:
- Producer configs Kafka protocol guide it this a bug? - message disorder in async send mode -- 0.9.0java client sdk InFlightRequests [KAFKA-4669] Correlation id for response () does not match request
Related blog posts:
- Isolation level in Apache Kafka consumers
- Control messages in Apache Kafka
- Records writing in Apache Kafka
My journey to understand idempotent producers in #ApacheKafka continues ?♂️. Today I published the last post before the final one, explaining max in flight requests per connection property https://t.co/YAjOwe3lsS
— Bartosz Konieczny (@waitingforcode) January 18, 2020