
During my last exploration of logs compaction, I found a method called isControlBatch. At the time, I only had a rough idea about this category of batches and that's the reason why I decided to learn a little bit more about them.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this blog post I will analyze the control messages from 2 perspectives, the reader's and writer's. And it's another important post that can help to understand what happens with the transactions in Apache Kafka. Maybe next time I will be able to write a full post about it?
Control messages and readers
A control message is a technical record written to the user topic and processed by the user's consumer. But despite these similarities with classical "data" records, it's never exposed to the client.
In the following schema you can see what happens when you call KafkaConsumer's poll method. At some point, the call goes to the instance of Fetcher class that is responsible for filtering out the control messages:
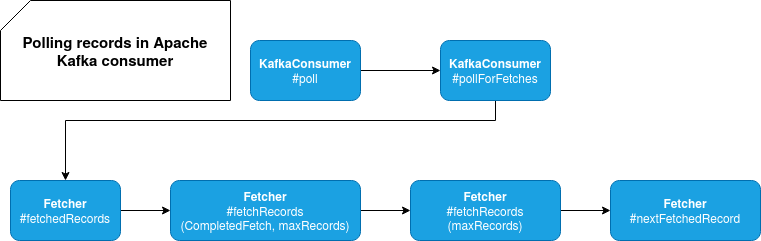
In the code, the control messages are skipped in the nextFetchedRecord() method. At the beginning, the fetching process goes to the next written batch of records:
private Record nextFetchedRecord() {
while (true) {
if (records == null || !records.hasNext()) {
// ...
currentBatch = batches.next();
// ...
records = currentBatch.streamingIterator(decompressionBufferSupplier);
}
At the end of this method you can see that a new set of records is created. At the next iteration in this while loop, the fetcher goes to the else statement that returns the record of the processed batch only when the batch itself is not a control message:
} else {
Record record = records.next();
// skip any records out of range
if (record.offset() >= nextFetchOffset) {
// we only do validation when the message should not be skipped.
maybeEnsureValid(record);
// control records are not returned to the user
if (!currentBatch.isControlBatch()) {
return record;
} else {
// Increment the next fetch offset when we skip a control batch.
nextFetchOffset = record.offset() + 1;
}
}
}
That way the control messages, even though they're written alongside the "data" records, are not returned to the consumer. Control messages are also related to the records visibility within a transaction, and more exactly to the filtering of records written by an aborted transaction, but it will be the topic of one of the next blog posts.
Control messages and writers
To understand where the control messages are used in writing process, let's zoom a little at the simplified version for transactions management:
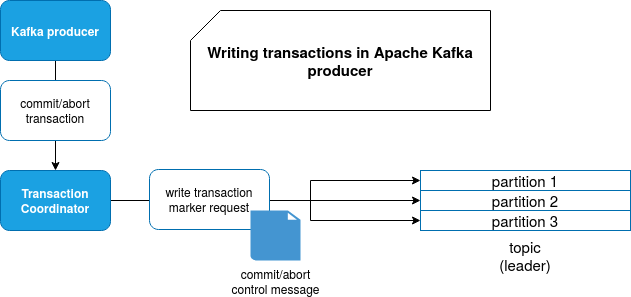
When the producer issues a commit or abort transaction, it sends a request to the transaction coordinator. The coordinator sends a request to the broker to add a control message in the logs. The method responsible for handling that is kafka.server.KafkaApis#handleWriteTxnMarkersRequest. The fragment which is interesting for this blog post is located in the snippet below. At the beginning the transaction outcome is converted to the type expected by the storage layer and just after that, the control batch is written there:
if (partitionsWithCompatibleMessageFormat.isEmpty) {
numAppends.decrementAndGet()
skippedMarkers += 1
} else {
val controlRecords = partitionsWithCompatibleMessageFormat.map { partition =>
val controlRecordType = marker.transactionResult match {
case TransactionResult.COMMIT => ControlRecordType.COMMIT
case TransactionResult.ABORT => ControlRecordType.ABORT
}
val endTxnMarker = new EndTransactionMarker(controlRecordType, marker.coordinatorEpoch)
partition -> MemoryRecords.withEndTransactionMarker(producerId, marker.producerEpoch, endTxnMarker)
}.toMap
replicaManager.appendRecords(
timeout = config.requestTimeoutMs.toLong,
requiredAcks = -1,
internalTopicsAllowed = true,
isFromClient = false,
entriesPerPartition = controlRecords,
responseCallback = maybeSendResponseCallback(producerId, marker.transactionResult))
}
Under-the-hood, the control message writing happens in MemoryRecords.withEndTransactionMarker:
public static void writeEndTransactionalMarker(ByteBuffer buffer, long initialOffset, long timestamp,
int partitionLeaderEpoch, long producerId, short producerEpoch,
EndTransactionMarker marker) {
boolean isTransactional = true;
boolean isControlBatch = true;
MemoryRecordsBuilder builder = new MemoryRecordsBuilder(buffer, RecordBatch.CURRENT_MAGIC_VALUE, CompressionType.NONE,
TimestampType.CREATE_TIME, initialOffset, timestamp, producerId, producerEpoch,
RecordBatch.NO_SEQUENCE, isTransactional, isControlBatch, partitionLeaderEpoch,
buffer.capacity());
builder.appendEndTxnMarker(timestamp, marker);
builder.close();
}
public Long appendEndTxnMarker(long timestamp, EndTransactionMarker marker) {
if (producerId == RecordBatch.NO_PRODUCER_ID)
throw new IllegalArgumentException("End transaction marker requires a valid producerId");
if (!isTransactional)
throw new IllegalArgumentException("End transaction marker depends on batch transactional flag being enabled");
ByteBuffer value = marker.serializeValue();
return appendControlRecord(timestamp, marker.controlType(), value);
}
Physically on disk, the control record is composed of a version and a type fields, where version is fixed to 0 and type can be either 0 (abort) or 1 (commit):
// ControlRecordType
public Struct recordKey() {
if (this == UNKNOWN)
throw new IllegalArgumentException("Cannot serialize UNKNOWN control record type");
Struct struct = new Struct(CONTROL_RECORD_KEY_SCHEMA_VERSION_V0);
struct.set("version", CURRENT_CONTROL_RECORD_KEY_VERSION);
struct.set("type", type);
return struct;
}
Control messages are then used to inform the consumer whether it can read the records written within a transaction. I will cover this aspect in the next post but thanks to the control message, the consumer can skip the records written by an aborted transaction. And as you saw in the post, even though these messages are written alongside the data, they're not returned to the consumer exposed to the client.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Control messages in Apache Kafka here:
Related blog posts:
- Isolation level in Apache Kafka consumers
- Records writing in Apache Kafka
- Offset-based lookup in Apache Kafka
Control messages in #ApacheKafka ? A short introduction of this type of records in the new blog post ? https://t.co/02WtMZ65V1
— Bartosz Konieczny (@waitingforcode) September 27, 2020