
Who says transaction, automatically invokes isolation levels, so what can be viewed by the consumer from uncommitted transactions. Apache Kafka also implements this concept and I will take a closer look on it in this blog post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
I divided the post into three parts. The first one shows a big picture of the interaction between the client and the broker. The next 2 ones explain, respectively, records retrieval and aborted transaction handling. Finally, the last one shows a quick demo of isolation levels.
Isolation level in record fetching
Let's start with a general explanation of the isolation level. When you initialize a KafkaConsumer, you can set the property called isolation.level to control what transaction records are exposed to the consumer. Two values are then possible, read_uncommitted to retrieve all records, independently on the transaction outcome (if any), and read_committed to get only the records from committed transactions.
The committed isolation level doesn't mean that the consumer will only read the transactional records. It will still read, unconditionally, the non-transactional writes as well. The difference is that it won't read the not committed records.
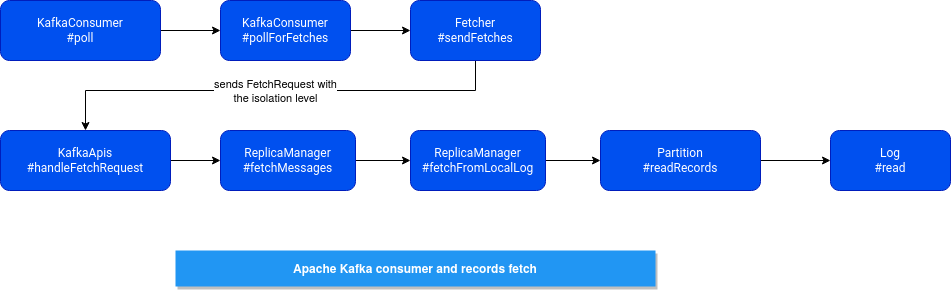
The isolation level is set for each consumer and sent to the broker with the fetch request. On the broker's side, the isolation level is later transformed into an instance of kafka.server.FetchIsolation (one of FetchLogEnd, FetchTxnCommitted, FetchHighWatermark), and passed from ReplicaManager to the Log, where the physical data retrieval happens. The retrieval consists of finding the max allowed offset and reading the records up to it:
val maxOffsetMetadata = isolation match {
case FetchLogEnd => nextOffsetMetadata
case FetchHighWatermark => fetchHighWatermarkMetadata
case FetchTxnCommitted => fetchLastStableOffsetMetadata
}
In the following schema you can see the classes and methods involved in the records reading:
Offsets resolution
The offset for the committed isolation level is returned from fetchLastStableOffsetMetadata method. Internally, it uses Log's attribute called firstUnstableOffsetMetadatathat tracks the earliest offset of an incomplete or not replicated yet transaction. It retrieves this information from these attributes of ProducerStateManager, always taking the first entry (since they're sorted by the data structure):
// ongoing transactions sorted by the first offset of the transaction private val ongoingTxns = new util.TreeMap[Long, TxnMetadata] // completed transactions whose markers are at offsets above the high watermark private val unreplicatedTxns = new util.TreeMap[Long, TxnMetadata]
You can learn from this snippet about the high watermark, which corresponds to the biggest offset, fully replicated to the partition's replicas. The unstable offset changes when the log has a new record appended or when the log is truncated. This offset information is, by the way, used in the uncommitted isolation level. This level, represented by FetchHighWatermark isolation level class, retrieves the max offset from fetchHighWatermarkMetadata.
Finally, but it's not related to the transaction isolation levels, the fetch can return the last written entry if the request comes from a follower or future local replica (replicaId equal to -3).
Aborted transactions
The next thing to notice regarding the isolation level is this flag variable:
// Log.scala val includeAbortedTxns = isolation == FetchTxnCommitted
As you can see, only the committed isolation level will not contain the aborted transaction's information in the response sent to the client. And everything happens in this part, where the broker iterates over all segments matching the queried offsets:
while (segmentEntry != null) {
// ...
val fetchInfo = segment.read(startOffset, maxLength, maxPosition, minOneMessage)
if (fetchInfo == null) {
segmentEntry = segments.higherEntry(segmentEntry.getKey)
} else {
return if (includeAbortedTxns)
addAbortedTransactions(startOffset, segmentEntry, fetchInfo)
else
fetchInfo
}
Later, the information about aborted transactions is retrieved from transaction index associated to the given log segment:
def collectAbortedTxns(fetchOffset: Long, upperBoundOffset: Long): TxnIndexSearchResult =
txnIndex.collectAbortedTxns(fetchOffset, upperBoundOffset)
The information about aborted transactions appeared from the previous fetch are returned to the client. But why, since the broker returns only the committed records? Especially than these aborted transactions seem to be used only for the committed isolation level:
if (isolationLevel == IsolationLevel.READ_COMMITTED && currentBatch.hasProducerId()) {
// remove from the aborted transaction queue all aborted transactions which have begun
// before the current batch's last offset and add the associated producerIds to the
// aborted producer set
consumeAbortedTransactionsUpTo(currentBatch.lastOffset());
long producerId = currentBatch.producerId();
if (containsAbortMarker(currentBatch)) {
abortedProducerIds.remove(producerId);
} else if (isBatchAborted(currentBatch)) {
log.debug("Skipping aborted record batch from partition {} with producerId {} and " +
"offsets {} to {}",
partition, producerId, currentBatch.baseOffset(), currentBatch.lastOffset());
nextFetchOffset = currentBatch.nextOffset();
continue;
}
}
I found the reason for that in the KIP-98 (I'll remember this number for life, I think :P):
Note also the addition of the field for aborted transactions. This is used by the consumer in READ_COMMITTED mode to know where aborted transactions begin. This allows the consumer to discard the aborted transaction data without buffering until the associated marker is read.
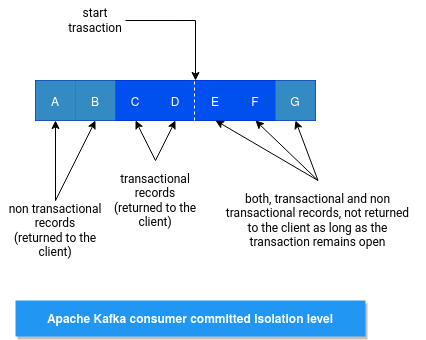
To understand the purpose, let's imagine the case when one transactional writer and one non-transactional writer produce data concurrently to the same partition. The former fails, and the latter succeeds. A few moments later, another transactional producer starts and this time, it successfully commits the transaction. Now, when a consumer fetches the records, he will get the records from the first transactional producer, the non-transactional producer, and the last transactional producer, which set the last stable offset. The following schema summarizes this situation:

Thanks to the code presented above, the consumer will skip all records generated by the first transactional consumer.
Demo
Let's see now the isolation levels in action. In the following video I'm creating 2 consumers and 1 producer, all running in different threads. The producer generates a sequence of data presented in the previous picture: a failed transaction and successful non transactional and transactional writes. The goal is to verify what records, depending on the isolation level of the consumers, are returned by the broker:
As for every transactional system, isolation levels are also present in Apache Kafka. In this blog post, you discovered some hidden details of the implementation and also learned (at least, I did) some new concepts like watermark or last stable offset. And at the same time, I can remove another point from my transactions discovery backlog!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Isolation level in Apache Kafka consumers here:
- Kafka - difference between Log end offset(LEO) vs High Watermark(HW) KIP-98 - Exactly Once Delivery and Transactional Messaging
Related blog posts:
- Control messages in Apache Kafka
- Records writing in Apache Kafka
- Offset-based lookup in Apache Kafka
This week no Apache Spark on the blog, sorry ?♂️ I had to finally publish the last post from the interrupted transactions exploration in #ApacheKafka. And I did it here ? https://t.co/pLWMscfgqC
— Bartosz Konieczny (@waitingforcode) November 21, 2020