
In March I published a blog post about timestamp-based lookup in Apache Kafka. But as you know, it's not the single lookup possibility. Another one uses indexes and it will be the topic of this article.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
I will start this blog post by introducing some storage details of the offset index files. After this introduction, I'll explain how Apache Kafka uses this information to know the position of the record to read in the logs. To not repeat myself but give you a little bit more context about the basic storage, I will just recall the picture summarizing the composition of the log from Timestamp-based lookup in Apache Kafka blog post:
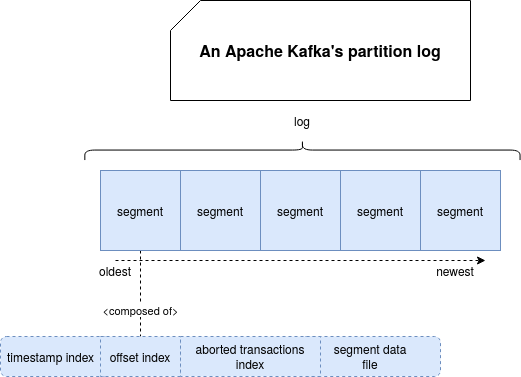
Today, I'll focus on the offset index file.
Offset index
Internally, the offset log is represented by the ... OffsetIndex class. As it's indicated on the picture, the offset index is associated with a log segment and it stores the relationship between the global offsets (the ones from the partition) to the physical location of the record in the segment file.
On this occasion, it's important to highlight how the offsets are stored. The offset index uses relative offsets to the base offset of the index file. What does it mean concretely? For example, if the index stores the records starting from the offset 100, then any subsequent offsets will be stored as 100 + ${offset}. In other words, the offset 120 will be stored as 20 and not 120. Thanks to this optimization, every mapping pair uses only 8 bytes, 4 for the relative and 4 for the physical offset.
Under-the-hood, the relative offset computation is made by this method of AbstractIndex class shared by both OffsetIndex and TimeIndex class presented in March:
private def toRelative(offset: Long): Option[Int] = {
val relativeOffset = offset - baseOffset
if (relativeOffset < 0 || relativeOffset > Int.MaxValue)
None
else
Some(relativeOffset.toInt)
}
Offset lookup
The information about the AbstractIndex class shared between OffsetIndex and TimeIndex is important not only from the relative offset resolution point of view. In addition to that, the AbstractIndex class provides a binary search method used by both types of indexes to look for the offset entries.
OffsetIndex exposes this search possibility from lookup(targetOffset: Long) method. If an entry is found, it returns an instance of OffsetPosition class constructed that way:
override protected def parseEntry(buffer: ByteBuffer, n: Int): OffsetPosition = {
OffsetPosition(baseOffset + relativeOffset(buffer, n), physical(buffer, n))
}
where both, relative and physical, offsets are computed from this formula:
private def relativeOffset(buffer: ByteBuffer, n: Int): Int = buffer.getInt(n * entrySize) private def physical(buffer: ByteBuffer, n: Int): Int = buffer.getInt(n * entrySize + 4)
As you can see, we retrieve here the magic number of 4 which corresponds to the size of every offset. Besides, this snippet shows how the data is written to the index file. When a new record is appended to the segment, it first writes the relative offset as a key and later, more exactly 4 bytes further, it adds the physical position (hence "+ 4" in physical).
After, this physical position is used to find the matching records in the segment file:
public LogOffsetPosition searchForOffsetWithSize(long targetOffset, int startingPosition) {
for (FileChannelRecordBatch batch : batchesFrom(startingPosition)) {
long offset = batch.lastOffset();
if (offset >= targetOffset)
return new LogOffsetPosition(offset, batch.position(), batch.sizeInBytes());
}
return null;
}
As you can learn from this article, the offset index has some points in common with timestamp-index. It shares the same parent class, thanks to which it uses the same, entry size-controlled behavior, and the identical binary search method for the lookups. Apart from that, it's important to keep in mind the relative offsets and the physical location for the records stored in the index.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Isolation level in Apache Kafka consumers
- Control messages in Apache Kafka
- Records writing in Apache Kafka
With topics and partitions, offsets are one of the main building blocks of #ApacheKafka That's why in my today's post I presented the offset-based lookup ? https://t.co/YnkojowGa4
— Bartosz Konieczny (@waitingforcode) September 13, 2020