
The next thing I wanted to understand while still working on transactions was the lookup. I can imagine how to get the first or the last element of a partition but I had no idea how it can work for more fine-grained access, like the one using timestamp.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
To understand the execution logic behind timestamp-lookup, I divided this post into 3 sections. In the first one, I will show a high-level view from the KafkaConsumer request to the broker. In the next one, I will recall some basics about internal storage. They will help me to explain easier the timestamp-based lookup in the last section.
High-level view - from client to server
Timestamp lookup is about retrieving the offsets corresponding to the timestamps associated with every topic/partition we want to process. Everything starts with KafkaConsumer's offsetsForTimes(Map
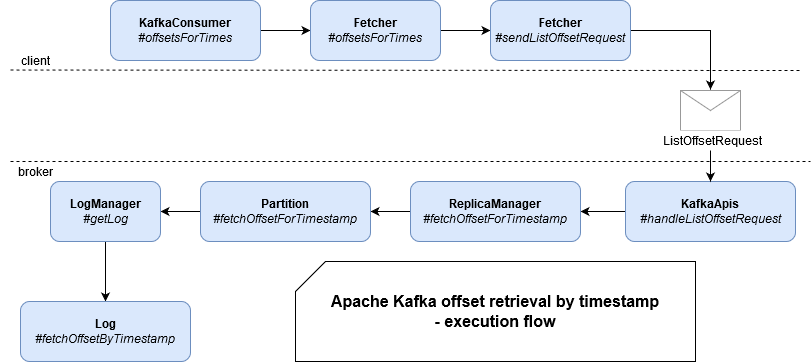
As you can see, the request for offsets retrieval is delegated to Fetcher which sends the request to the broker. On the broker side, there is nothing strange, maybe except the fact of using ReplicaManager. If I understood the code correctly, the fact of passing by ReplicaManager avoids the case of reads on replica brokers and helps the clients to refresh their information:
def getPartitionOrError(topicPartition: TopicPartition, expectLeader: Boolean): Either[Errors, Partition] = {
getPartition(topicPartition) match {
// ...
case HostedPartition.None if metadataCache.contains(topicPartition) =>
if (expectLeader) {
// The topic exists, but this broker is no longer a replica of it, so we return NOT_LEADER which
// forces clients to refresh metadata to find the new location. This can happen, for example,
// during a partition reassignment if a produce request from the client is sent to a broker after
// the local replica has been deleted.
Left(Errors.NOT_LEADER_FOR_PARTITION)
} else {
Left(Errors.REPLICA_NOT_AVAILABLE)
}
Logs, segments and batches
The high-level view from the previous part is not enough to understand how the offsets are fetched by the timestamp. There is a missing piece which is the physical organization of the partition on disk, summarized in this schema:
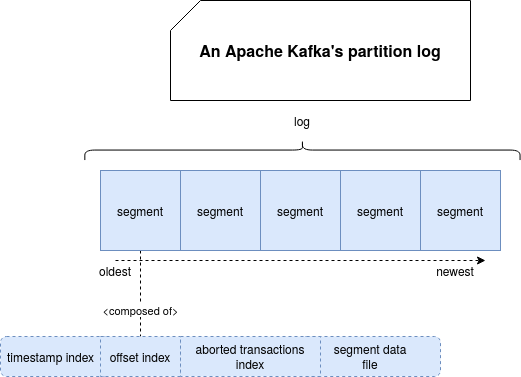
As you can notice, every log composing a partition (usually there will be a single one) is composed of multiple segments, ordered from the oldest to the most recent ones. Every segment has its data file where all records are stored and in addition to it, it also has 3 different indexes. Digression mode on - When I discovered the aborted transactions index I was happy because it answers one of my questions about records visibility during the transaction. But I will cover this topic in another blog posts - Digression mode off.
Timestamp index is a mapping between records timestamps and their positions whereas offset index is the mapping between offsets and their positions in the files. And as I can suppose right now, you start to know how the timestamp fetches works.
Timestamp lookup
Before I give you the answer, one thing to notice. The entries in the indexes aren't added for every single record added to the log. The frequency of updates is controlled by index.interval.bytes property which by default is 4096. It means that Apache Kafka will add new entries to the offset and timestamp indexes every 4096 bytes. You can see how it's used in LogSegment class:
// append an entry to the index (if needed)
if (bytesSinceLastIndexEntry > indexIntervalBytes) {
offsetIndex.append(largestOffset, physicalPosition)
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar)
bytesSinceLastIndexEntry = 0
}
Why am I saying that? To explain the comment from TimeIndex class representing the timestamp index:
An index that maps from the timestamp to the logical offsets of the messages in a segment. This index might be sparse, i.e. it may not hold an entry for all the messages in the segment.
But let's get back to the offsets retrieval from the timestamp. The lookup starts in Log class which retrieves LogSegment with the max timestamp smaller than the looked one. Later, it calls findOffsetByTimestamp(timestamp: Long, startingOffset: Long = baseOffset) method this segment. This function uses timestamp and offset indexes to figure out the offset:
// Get the index entry with a timestamp less than or equal to the target timestamp
val timestampOffset = timeIndex.lookup(timestamp)
val position = offsetIndex.lookup(math.max(timestampOffset.offset, startingOffset)).position
// Search the timestamp
Option(log.searchForTimestamp(timestamp, position, startingOffset))
As you can see, first, it tries to find the timestamp offset corresponding to the looked offset. This lookup consists of using binary search on the timestamp index to find the closest lower offset corresponding to the searched value. Later, it uses a similar method to find the physical position of the data in the segment log from the offset index.
Once the position is retrieved, LogSegment delegates the work to Log and its searchForTimestamp(long targetTimestamp, int startingPosition, long startingOffset) method where, as you can see in the following snippet, Apache Kafka retrieves all messages equal or greater than the position. Later, for every message, it compares its timestamp and offset that should never be lower than the lowest offset in the partition which is exposed to the client (can be changed because of TTL or truncation):
public TimestampAndOffset searchForTimestamp(long targetTimestamp, int startingPosition, long startingOffset) {
for (RecordBatch batch : batchesFrom(startingPosition)) {
if (batch.maxTimestamp() >= targetTimestamp) {
// We found a message
for (Record record : batch) {
long timestamp = record.timestamp();
if (timestamp >= targetTimestamp && record.offset() >= startingOffset)
return new TimestampAndOffset(timestamp, record.offset(),
maybeLeaderEpoch(batch.partitionLeaderEpoch()));
}
}
}
return null;
}
And so resolved offsets are later returned to the client. As you can notice, there is nothing done by chance. Apache Kafka design, thanks to the log segments and associated indexes, makes this retrieval quite easy and, among others, efficient.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Timestamp-based lookup in Apache Kafka here:
Related blog posts:
- Isolation level in Apache Kafka consumers
- Control messages in Apache Kafka
- Records writing in Apache Kafka
In my journey to understand transaction internals, I explored the world of #ApacheKafka timestamp lookups ?https://t.co/vu9hZbHU4M
— Bartosz Konieczny (@waitingforcode) March 29, 2020