
When I was playing with Kafka HDFS Connector, I saw that the generated files are suffixed by some numbers. It intrigued me and I decided to explore the topic in this article.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Even though I'm not very familiar with Kafka Connect API, I will try to analyze the code source and answer the question of why these suffixes are generated?
File name composition
When I was playing with Kafka HDFS Connector, the files were always generated with the same pattern, namely: ${topic}+${partition}+${starting offset}+${end offset}. An example of it was my_topic+0+0000000010+0000000014.avro.
That name is created in io.confluent.connect.hdfs.FileUtils#committedFileName method where all of the filename components are passed as parameters:
public static String committedFileName(
String url,
String topicsDir,
String directory,
TopicPartition topicPart,
long startOffset,
long endOffset,
String extension,
String zeroPadFormat
) {
String topic = topicPart.topic();
int partition = topicPart.partition();
StringBuilder sb = new StringBuilder();
sb.append(topic);
sb.append(HdfsSinkConnectorConstants.COMMMITTED_FILENAME_SEPARATOR);
sb.append(partition);
sb.append(HdfsSinkConnectorConstants.COMMMITTED_FILENAME_SEPARATOR);
sb.append(String.format(zeroPadFormat, startOffset));
sb.append(HdfsSinkConnectorConstants.COMMMITTED_FILENAME_SEPARATOR);
sb.append(String.format(zeroPadFormat, endOffset));
sb.append(extension);
String name = sb.toString();
return fileName(url, topicsDir, directory, name);
}
But it's only the visible part of the iceberg, the easiest one to find. The whole logic in the hidden part is important as well. Let's see now what happens when the files are synchronized from an Apache Kafka topic to HDFS.
Execution flow
The entry class is HdfsSinkConnector and by itself it does nothing but configuring the connector and exposing the class representing the tasks that will physically execute the synchronization between Kafka and HDFS. These tasks will be the instances of HdfsSinkTask and inside you will find much more logic.
The task instance creates an instance of DataWriter that receives, from HdfsSinkTasks's put method, all records to synchronize. But under-the-hood, DataWriter doesn't persist the data. It delegates this task to TopicPartitionWriter instances which, as you can deduce from the name of the class, are responsible for persisting every partition.
How does it work? The records are first buffered in memory of the TopicPartitionWriters and later every record is written into a temporary file, still at partition basis. At the end, when the current execution terminates, the commit happens and the temporary file is transformed into the final one with the rename operation (temporary → committed).
Internally, all this logic is managed with a state machine that I will introduce in the next part.
State machine
Let's see first the sequence of states in the task execution process:
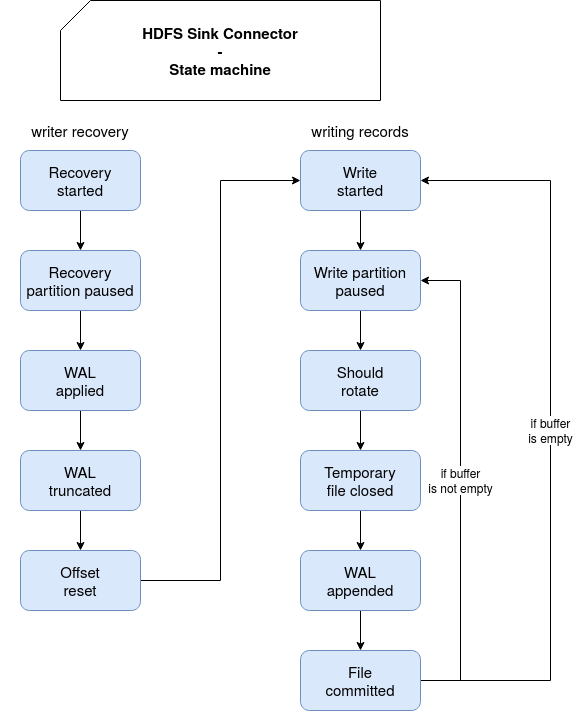
Everything starts when the TopicPartitionWriter instance is created where the recovery stage is executed (DataWriter#open, recovery called after partition assignment when TopicPartitionWriter instancess are created). During the recovery, the writer checks in the Write Ahead Logs (WAL) whether there are some pending temporary files that need to be committed. If it's the case, the commit (rename temporary --> committed file) happens. Later, a new WAL file is created and the next offset to the process is resolved. Before going to the record writing, let's focus on these 2 aspects:
- WAL file - this file contains a mapping between a temporary file and the name of the committed file. A new entry is added every time a new temporary file is created, for example the writer should rotate the files with the properties like rotate.schedule.interval.ms.
- next offset resolution - the magic happens in FileUtils#fileStatusWithMaxOffset where first all written files are listed and later the max written offset is resolved from their names (to recall, the last integer is the max written offset):
private void readOffset() throws ConnectException { String path = FileUtils.topicDirectory(url, topicsDir, tp.topic()); CommittedFileFilter filter = new TopicPartitionCommittedFileFilter(tp); FileStatus fileStatusWithMaxOffset = FileUtils.fileStatusWithMaxOffset( storage, new Path(path), filter ); if (fileStatusWithMaxOffset != null) { long lastCommittedOffsetToHdfs = FileUtils.extractOffset( fileStatusWithMaxOffset.getPath().getName()); // `offset` represents the next offset to read after the most recent commit offset = lastCommittedOffsetToHdfs + 1; } }
Once we know what to do (ie. what data read from the partition), the execution resumes. Some records are first buffered and later the consumption from the partition stops for the time of flushing the buffered entities to the file system.
The flushing consists of rotating the temporary files or writing the records to them with the help of RecordWriter built from RecordWriterProvider which corresponds to our output format (JSON, Avro, Parquet, ...). After writing the file to the temporary location, the commit happens.
Once all buffered files are written, the loop starts again by resuming the consumption of given partition:
if (buffer.isEmpty()) {
// committing files after waiting for rotateIntervalMs time but less than flush.size
// records available
if (recordCounter > 0 && shouldRotateAndMaybeUpdateTimers(currentRecord, now)) {
log.info(
"committing files after waiting for rotateIntervalMs time but less than flush.size "
+ "records available."
);
updateRotationTimers(currentRecord);
try {
closeTempFile();
appendToWAL();
commitFile();
} catch (ConnectException e) {
log.error("Exception on topic partition {}: ", tp, e);
failureTime = time.milliseconds();
setRetryTimeout(timeoutMs);
}
}
resume();
state = State.WRITE_STARTED;
}
As you can learn from this post, commits, WAL file, and offsets in the file names are 3 important techniques in Kafka HDFS Sink to ensure an exactly-once delivery. However, keep in mind that exactly-once delivery means here that every record will be written only once. If your topic has duplicates because of some data production issues, you will still retrieve them on the written files and should handle them in your application logic accordingly.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Files synchronization - zoom at Kafka HDFS Connector here:
Related blog posts:
- Isolation level in Apache Kafka consumers
- Control messages in Apache Kafka
- Records writing in Apache Kafka
What is the logic behind the exactly-once delivery semantic of #ApacheKafka #HDFS sink? I focused on this aspect in my today's post ?https://t.co/wYg2HXH34a
— Bartosz Konieczny (@waitingforcode) May 17, 2020