
Since my very first experiences with Apache Kafka, I was always amazed by the features handled by this tool. One of them, that I haven't had a chance to explore yet, is logs compaction. I will shed some light on it in this and next week's article.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In the first part of the blog post, I will introduce the cleanup policy that will be the main topic of the next articles. After that, I will go through the internal classes involved in the compaction to understand better what happens inside and what delete strategies can apply.
Cleanup policy
Kafka's behavior for compaction is defined in thecleanup.policy property. It applies at topic's level and defines the cleanup behavior which can be delete, compact or both, which means that given topic will be compacted (only the most recent key is kept) and/or cleaned (too old segments deleted).
In this article I will focus only on the delete flag because, as you will see later, the topic is quite complex, and explaining both of them at the same time would be overkill.
Background process
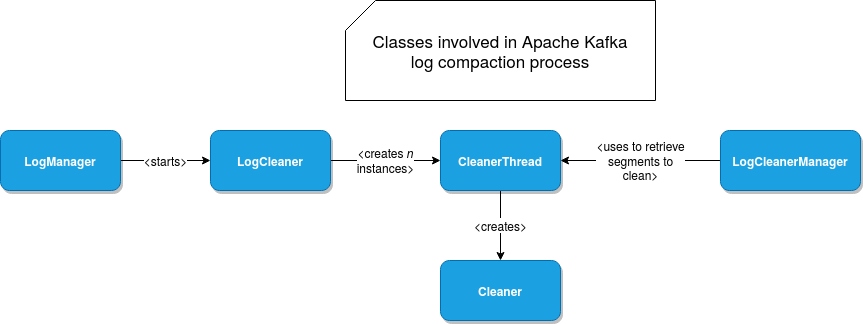
Kafka performs log compaction in a background process defined in CleanerThread class. The number of CleanerThreads depends on the log.cleaner.threads property and the object responsible for their initialization is LogCleaner. Logs cleaning, which by the way can be disabled with log.cleaner.enable property, is managed by LogManager class.
CleanerThread is a long-running process that communicates with LogCleanerManager to retrieve logs to clean. The instance of LogCleanerManager is shared by all cleaning threads to guarantee exclusive access to the log segments. To achieve that, it uses exclusive locks that are acquired every time the segments to clean are resolved.
The last important object is the one involved in the physical cleaning. It's an instance of Cleaner class initialized inside every CleanerThread. A simplified dependencies diagram for all these classes looks like that:
Logs deletion
Let's begin with the easiest cleanup policy, logs removal. To understand what happens, we have to start with the "when". How often the logs will be deleted? The cleaning thread (CleanerThread) runs indefinitely but doesn't work the whole time. Instead it does the cleaning and sleeps for the time specified in log.cleaner.backoff.ms property.
Once awaken, the CleanerThread instance goes to its tryCleanFilthiestLog where the compaction happens. The name of this method can seem strange at first glance but "filthiest" is another way to describe something as "dirty". The method is responsible for both compaction and deletion but let's focus only on the latter one in this article. By the way, this fact shows that CleanerThread is not exclusively linked to any topic because we can use a different cleanup policy per topic.
At the beginning of the deletion process, the LogCleanerManager returns a list of logs to delete from its deletableLogs() method. A partition's segment can be deleted if:
- the partition is not already deleted by another CleanerThread - LogCleanerManager stores a list of currently cleaned partitions and it explains why I described it as a concurrency controller earlier in the post
- the cleanup policy is set to compact for the topic - I was quite surprised with this flag but it makes sense. The clean up policy will apply in this context to the compacted segments which contain too old logs for a given key. For example, if the key "A" was overridden with a new value, we should check whether it still makes sense to keep the segment storing the old value after the compaction.
- the partition to be cleaned didn't raise any fatal error during previous cleaning activity - it happens for any not recoverable exception, as you can see in the following snippet from the CleanerThread:
private def tryCleanFilthiestLog(): Boolean = { try { cleanFilthiestLog() } catch { case e: LogCleaningException => warn(s"Unexpected exception thrown when cleaning log ${e.log}. Marking its partition (${e.log.topicPartition}) as uncleanable", e) cleanerManager.markPartitionUncleanable(e.log.dir.getParent, e.log.topicPartition) false } }
Once all eligible partitions with logs are retrieved, they're put to the in-progress list and returned to the CleanerThread. The cleaner iterates over all logs and deletes too old segments. Just to recall, a log is a sequence of segments and that's why there is no need to extra fetch for them.
Deletion modes
The deletion process is driven by the cleanup policy configuration. If it's set to delete, the following things happen:
- deleteRetentionMsBreachedSegments - here the segments delete is controled by the last written record. If the last record was written later than retention.ms ago, it means that the segment can be deleted. It applies only when the retention.ms is set.
- deleteRetentionSizeBreachedSegments - here the delete process is controlled by retention.bytes property which defines the maximal size of every partition.
- deleteLogStartOffsetBreachedSegments - here the delete happens for all segments having the records that aren't exposed to the client. The predicate uses the currently exposed offset and the lower bound of the offset in the segment and marks for deletion any segment whose offset is lower than the exposed one.
If the cleanup policy is not set to delete, only the last deletion is performed. So regarding the conditions from the previous step, only the last, deleteLogtartOffsetBreachedSegments, will be performed by CleanerThread.
So when all 3 methods are executed? They're executed every log.retention.check.interval.ms by the LogManager. This operation seems to be more a garbage-collection operation whereas the one made by the CleanerThread deletion applies more to the compacted segments.
Asynchronous deletion
The deletion process doesn't remove the segment files immediately. Still, they're removed from all the in-memory mapping of the log to make them invisible for the process, but the files are marked for deletion. How does it work? The delete method takes an asyncDelete flag as a parameter and depending on its value, deletes the files immediately or simply schedules the physical delete.
In the case of cleanup policy the delete is scheduled and will execute in file.delete.delay.ms milliseconds. How the physical deletion process knows what files should be deleted? They're in the scope of the function:
private def deleteSegmentFiles(segments: Iterable[LogSegment], asyncDelete: Boolean): Unit = {
segments.foreach(_.changeFileSuffixes("", Log.DeletedFileSuffix))
def deleteSegments(): Unit = {
info(s"Deleting segments $segments")
maybeHandleIOException(s"Error while deleting segments for $topicPartition in dir ${dir.getParent}") {
segments.foreach(_.deleteIfExists())
}
}
if (asyncDelete) {
info(s"Scheduling segments for deletion $segments")
scheduler.schedule("delete-file", () => deleteSegments, delay = config.fileDeleteDelayMs)
} else {
deleteSegments()
}
}
As you can see, the cleanup process also marks all files as "to be deleted" by adding the .deleted suffix to them. In my understanding, the goal of this operation is to hide these files from any processes as long as the physical delete doesn't happen and this behavior is exposed in the Log methods like:
private def isIndexFile(file: File): Boolean = {
val filename = file.getName
filename.endsWith(IndexFileSuffix) || filename.endsWith(TimeIndexFileSuffix) || filename.endsWith(TxnIndexFileSuffix)
}
private def isLogFile(file: File): Boolean =
file.getPath.endsWith(LogFileSuffix)
Log deletes
So far I described the segments deletion but in the code of the presented classes you can also see another delete process, triggered by LogManager that concerns the whole logs, so all segments at once! This process is not related to the cleanup policy and is more involved in the replication process.
This feature was implemented as a part of KIP-113 which introduced the possibility to change the log directory of a given replica. To handle the log removal in that case, Apache Kafka also uses the suffix technique, except here the whole log directory is marked for deletion by adding the -delete suffix to it. The logs are also added to LogManager's logsToBeDeleted queue.
LogManager uses the queue to get the old logs to delete. Under-the-hood, one of the log deletion components is previously mentioned deleteSegmentFiles method that, this time, is invoked synchronously.
Before I started to write this article, I wanted to present both compaction and delete policies. However, with the exploration moving forward I saw that it can be hard because the topic was not as easy as I thought. You can see that it's true, even though the internal classes architecture is quite straightforward, there are a lot of interesting aspects to cover like async vs sync deletes or log vs log segments deletes. That's why only in the next article from the series you will discover the log compaction process.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Logs compaction in Apache Kafka - delete and cleanup policy here:
Related blog posts:
- Isolation level in Apache Kafka consumers
- Control messages in Apache Kafka
- Records writing in Apache Kafka
After few months, #ApacheKafka topic is back. In the new blog post you can learn about the delete clean up policy internals. https://t.co/bKWwStbqG7
— Bartosz Konieczny (@waitingforcode) August 16, 2020